PyCaretで分類モデルを構築してみます。
データの取得
まず、乳がんのデータセットを読み込みます。
[Google Colaboratory]
1 | import pandas as pd |
前処理はPyCaretに任せるのでここではデータの加工は行いません。
[実行結果(一部略)]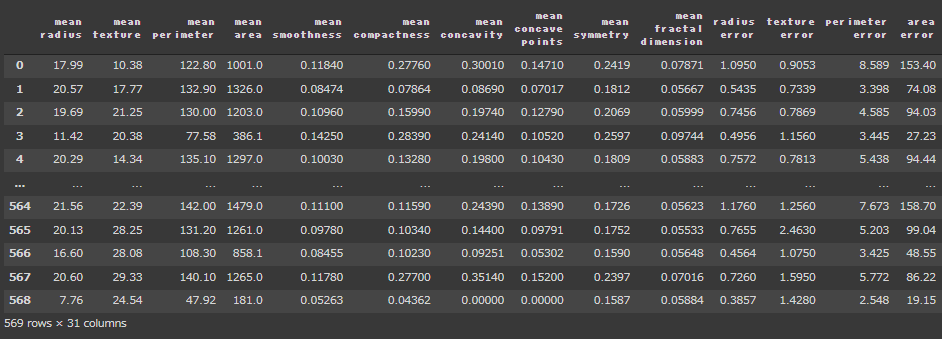
データ分割
モデル構築に使う訓練データ(90%)とモデル構築に使わないUnseenデータ(10%)に分割します。
[Google Colaboratory]
1 | tg_df = tg_df_all.sample(frac=0.90, random_state=0).reset_index(drop=True) |
[実行結果]
前処理
PyCaretを使って前処理を行います。
[Google Colaboratory]
1 | from pycaret.classification import * |
PyCaretの分類系ライブラリをインポートしています。(1行目)
setup関数のパラメータsilentにTrueを指定し、型推定の確認をスキップしています。(7行目)
[実行結果]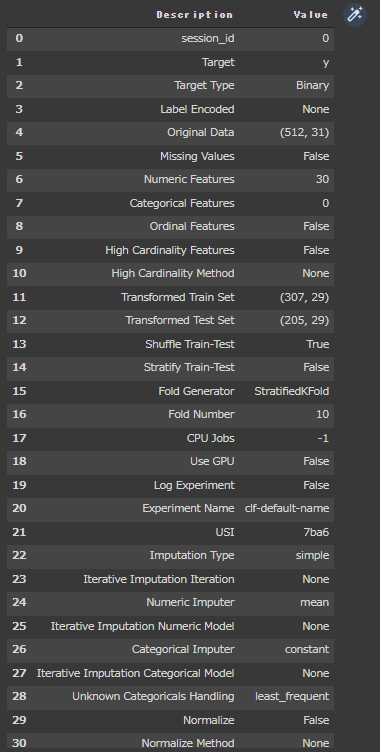
分類モデル一覧
PyCaretが提供している分類モデル一覧を確認します。
[Google Colaboratory]
1 | models() |
[実行結果]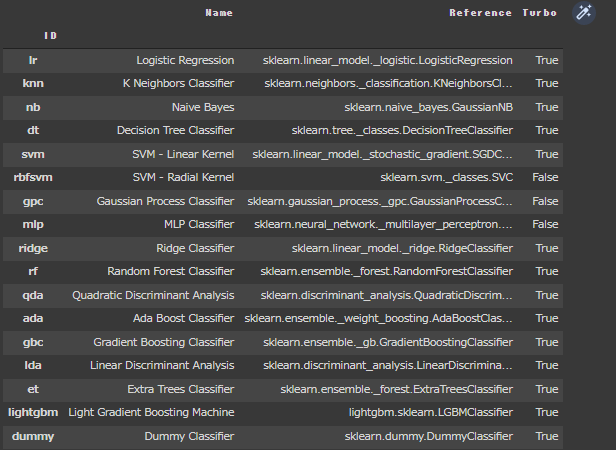
モデル評価一覧
compare_models関数を使って、各モデルを構築し評価一覧を表示します。
sortに“F1”を設定しているので、F1評価の高い順に表示します。
[Google Colaboratory]
1 | compare_models(sort = "F1", fold = 10) |
[実行結果]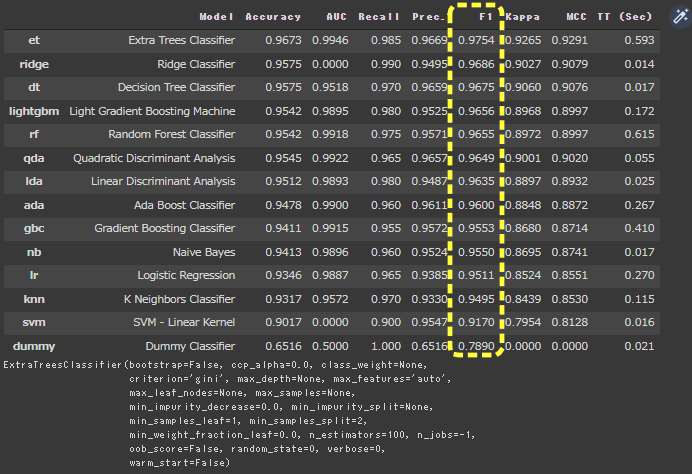
分類モデルの評価指標でモデル評価一覧が表示されました。
F1基準でExtra Trees Cassifierモデルの評価が1番高いことが確認できます。
パラメータチューニング
2番目に精度が良くて、速度が速いRidge Classifierのチューニングを行います。
まずはチューニングなしで実行してみます。
create_model関数に、Ridge ClassifierのID ridge を設定し実行します。
[Google Colaboratory]
1 | ridge = create_model("ridge", fold = 10) |
[実行結果]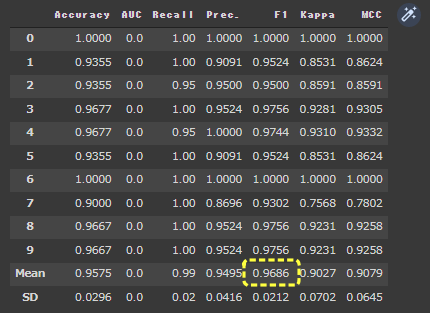
F1の平均は0.9686になりました。
次はハイパーパラメータのチューニングを行います。
optimize引数に対象指標F1、n_iter(パラメータ探索回数)に100を設定しtune_model関数を実行します。
[Google Colaboratory]
1 | tuned_ridge = tune_model(ridge, optimize = "F1", fold = 10, n_iter = 100) |
[実行結果]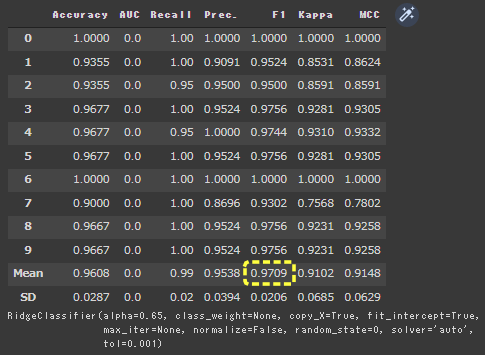
F1が0.9686から0.9709に向上したことが確認できました。