PyCaretを使って、教師なし学習(クラスタリング)を行っていきます。
データの読み込みと前処理
まずアイリスデータを読み込みます。
[Google Colaboratory]
1 | import pandas as pd |
次にsetup関数を使って前処理を行います。
[Google Colaboratory]
1 | from pycaret.clustering import * |
silentオプションにTrueを設定し、型推定の確認をスキップしています。(5行目)
[実行結果]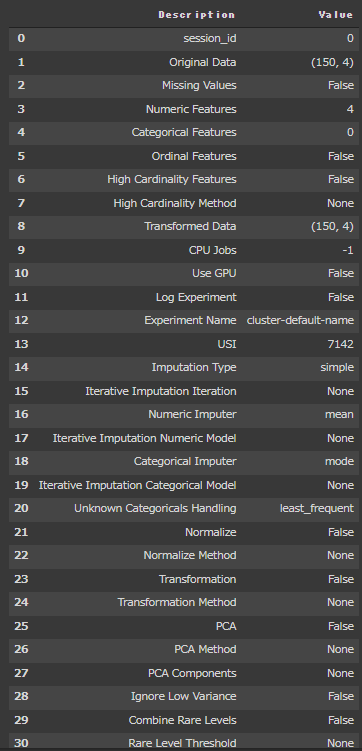
クラスタリング一覧
PyCaretが提供しているクラスタリング一覧を確認してみます。
[Google Colaboratory]
1 | models() |
[実行結果]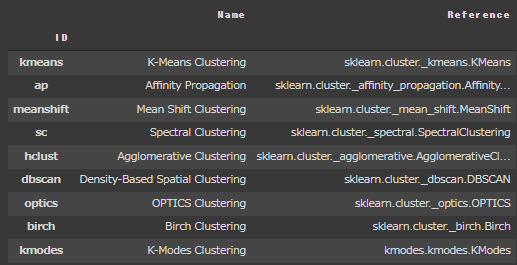
クラスタリングに関するいろいろなアルゴリズムが提供されていることが分かります。
クラスタリングモデルの作成
create_model関数に“kmeans”を指定し、クラスタリングモデルを作成します。
[Google Colaboratory]
1 | kmeans = create_model("kmeans", num_clusters=3) |
[実行結果]
SilhouetteやCalinski-Harabaszなどの評価指数が表示されました。
Cluster PCA Plot
クラスタリング結果を可視化します。
[Google Colaboratory]
1 | plot_model(kmeans) |
[実行結果]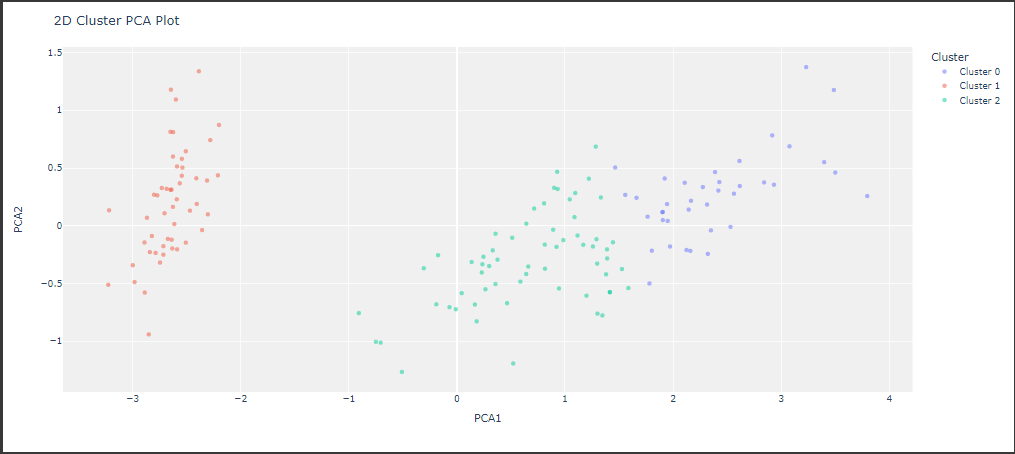
PCAが可視化され、きれいに分類されていることが確認できます。
PCAとは主成分分析のことで、特徴量を抽出することによって、次元削除や可視化をすることが可能になります。