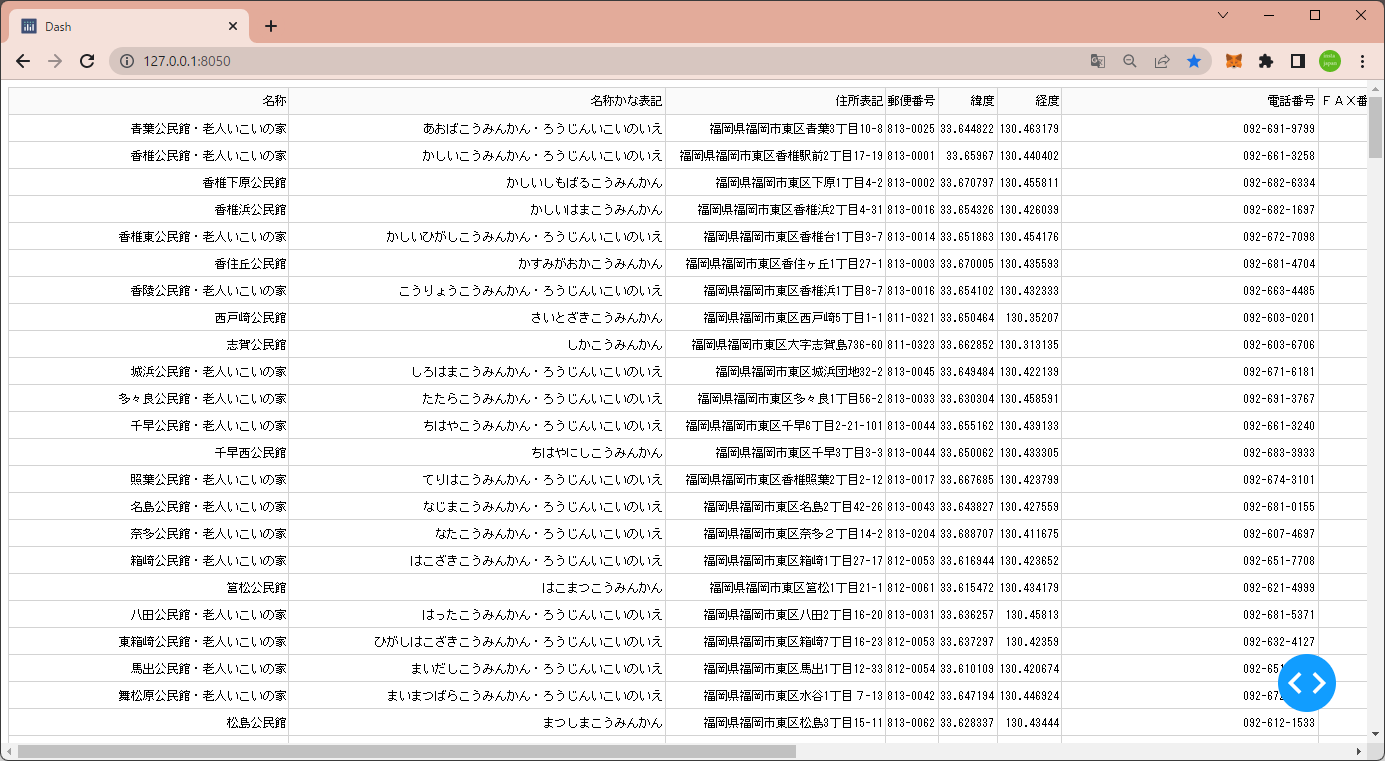
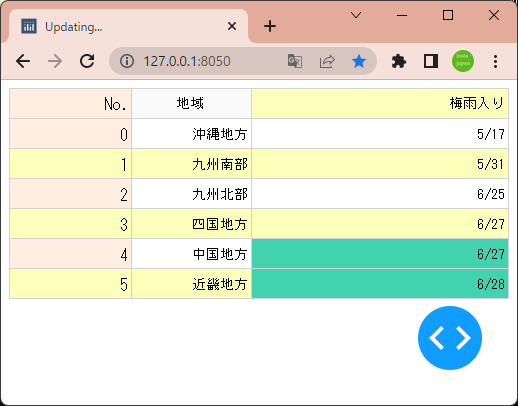
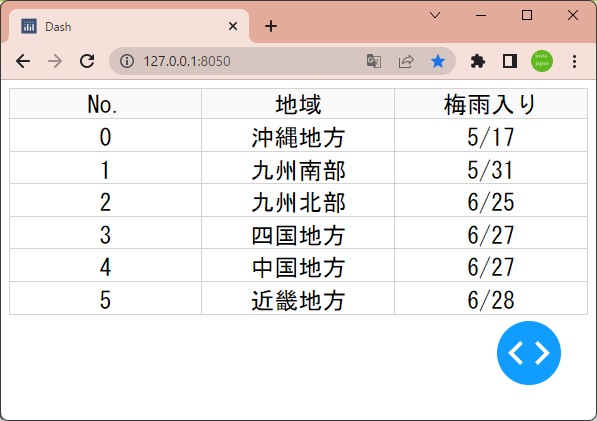
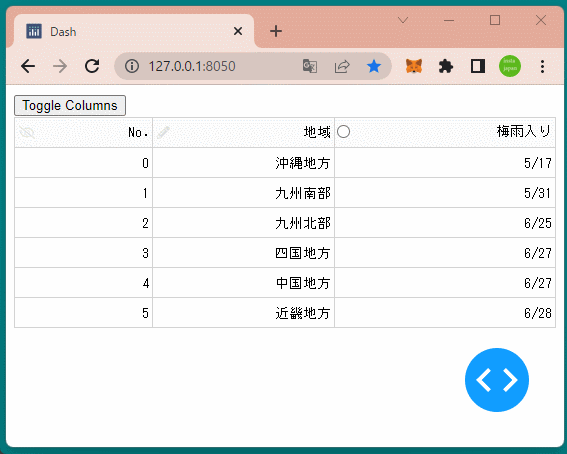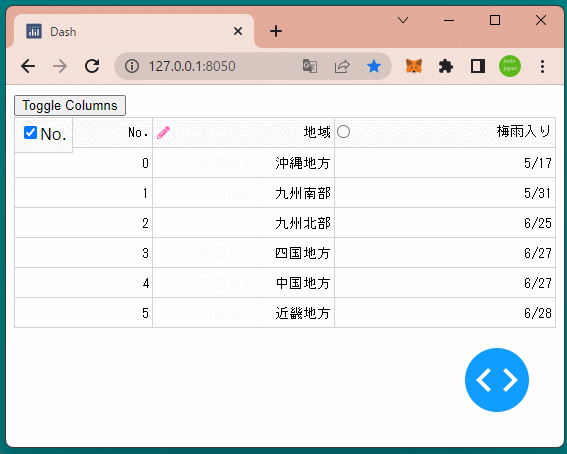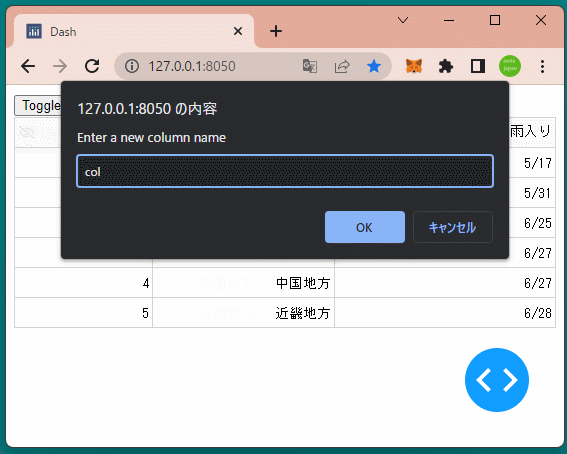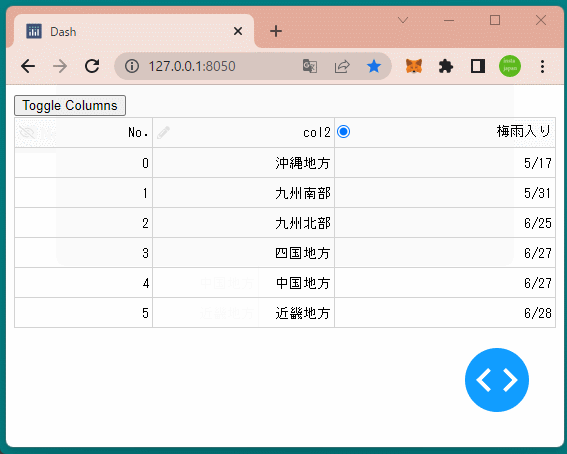
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| import io, base64
import pandas as pd
import dash
import dash_table
import dash_core_components as dcc
import dash_html_components as html
import plotly.graph_objects as go
import plotly.express as px
from dash.dependencies import Input, Output, State
app = dash.Dash(__name__)
app.layout = html.Div(
[
dcc.Upload(
id='upload1',
children=html.Div(['Drag and Drop or ', html.A('Select CSV or Excel File')]),
style={
'width':'80%',
'height':'50px',
'lineHeight':'60px',
'borderWidth':'1px',
'borderStyle':'dashed',
'borderRadius':'5px',
'textAlign':'center',
'margin':'5% auto',
}
),
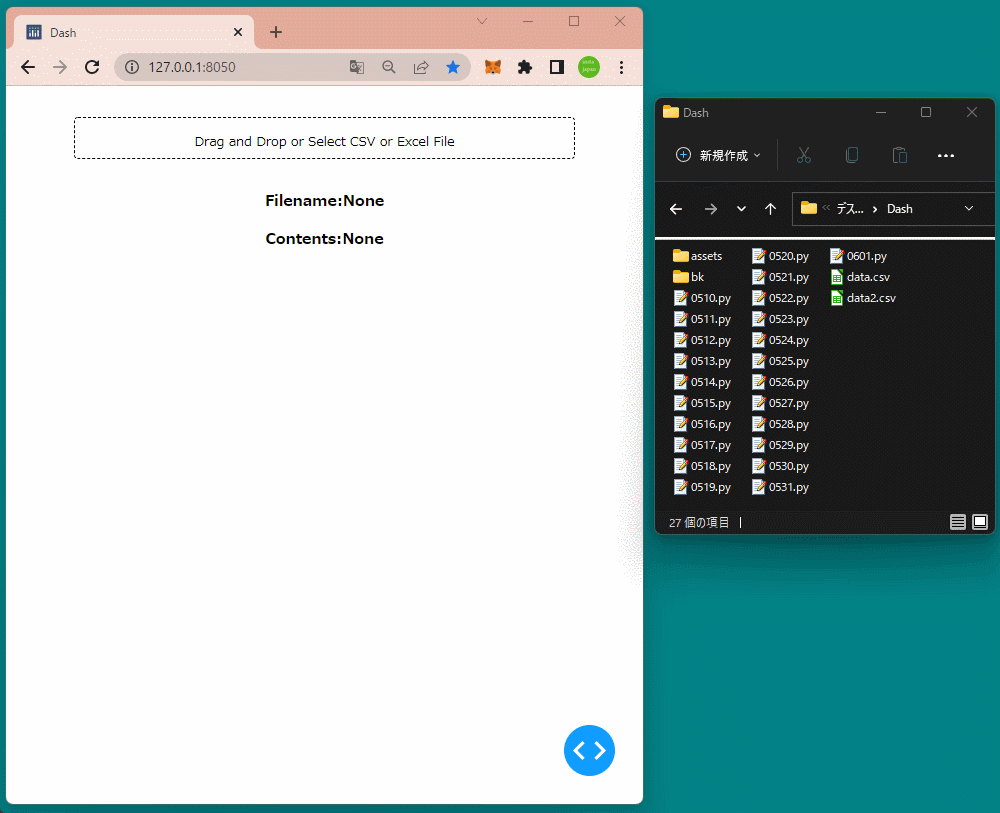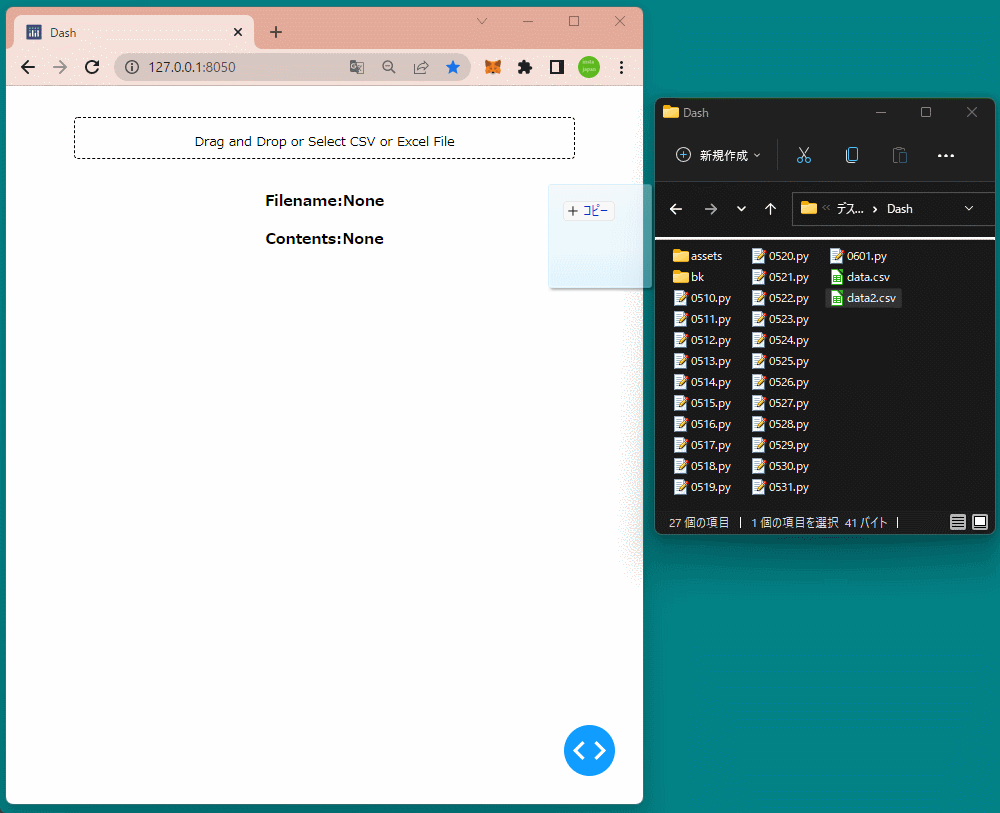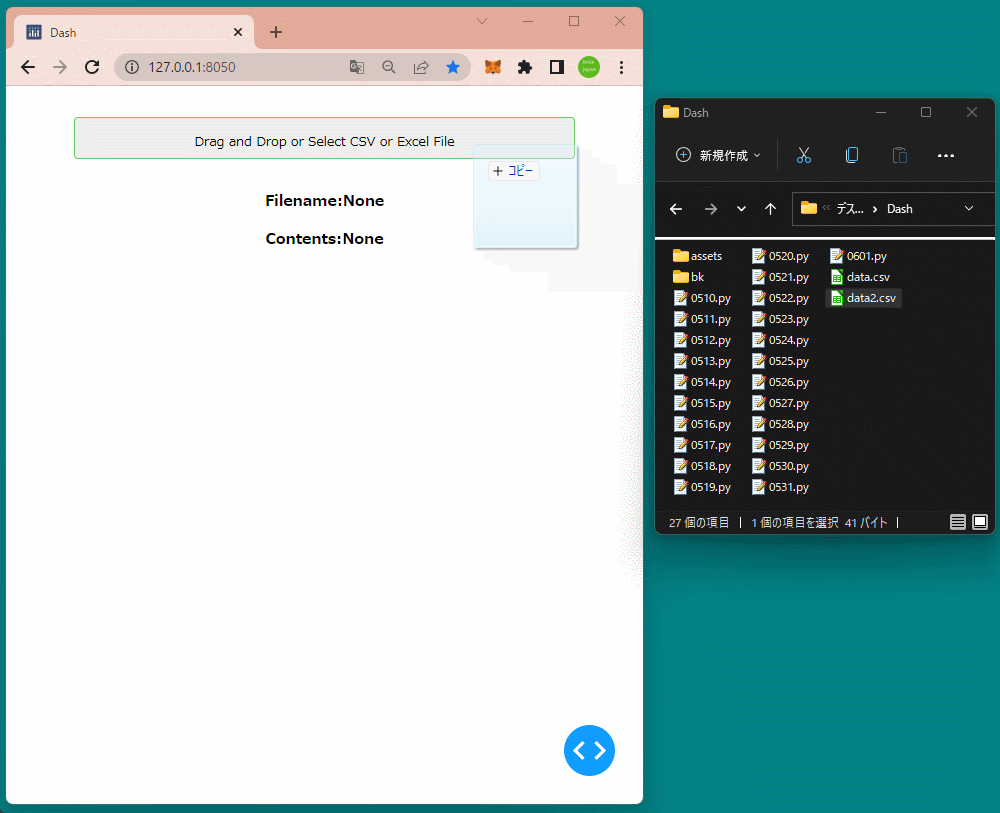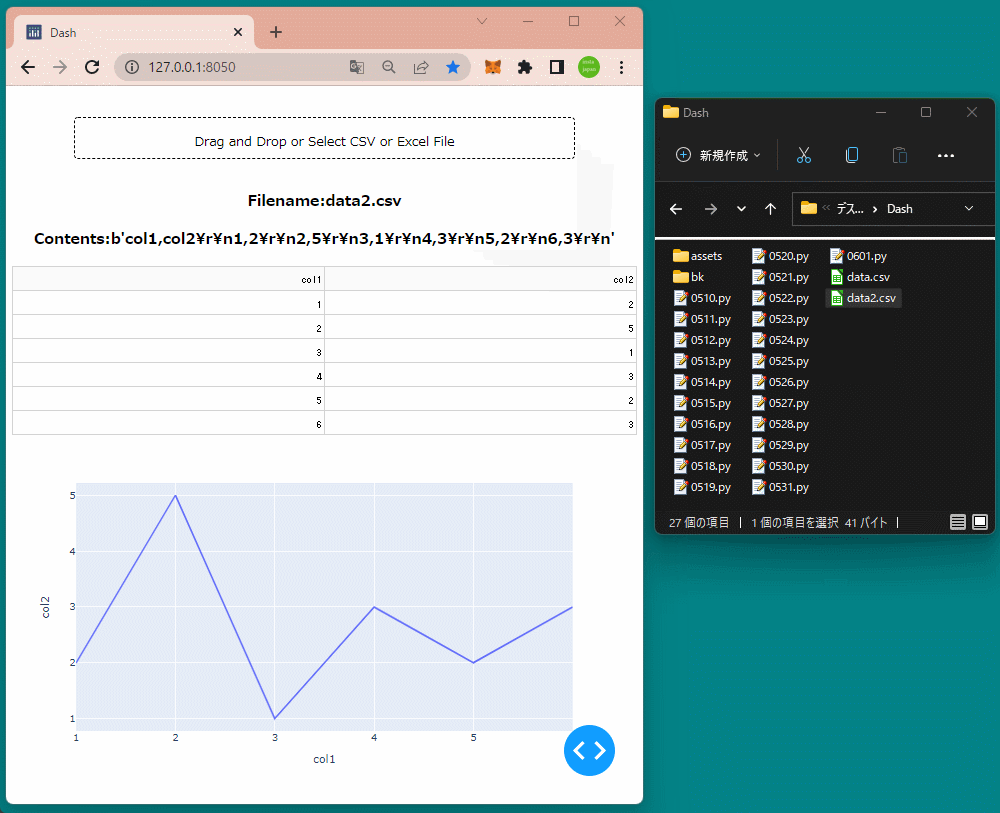
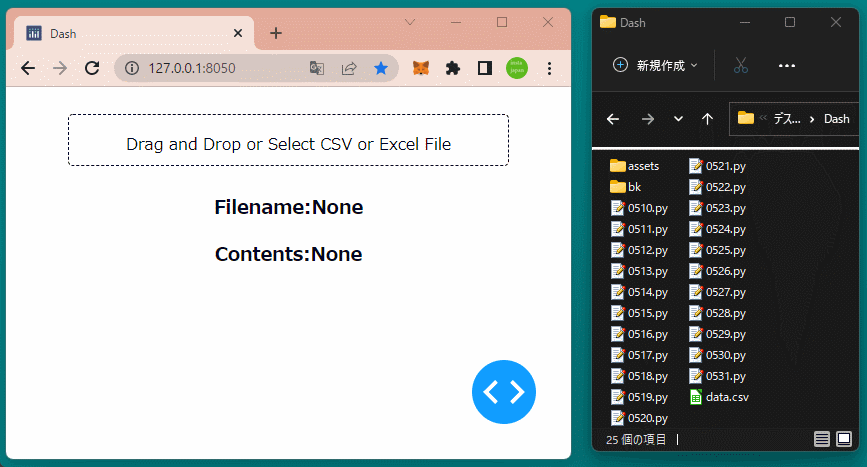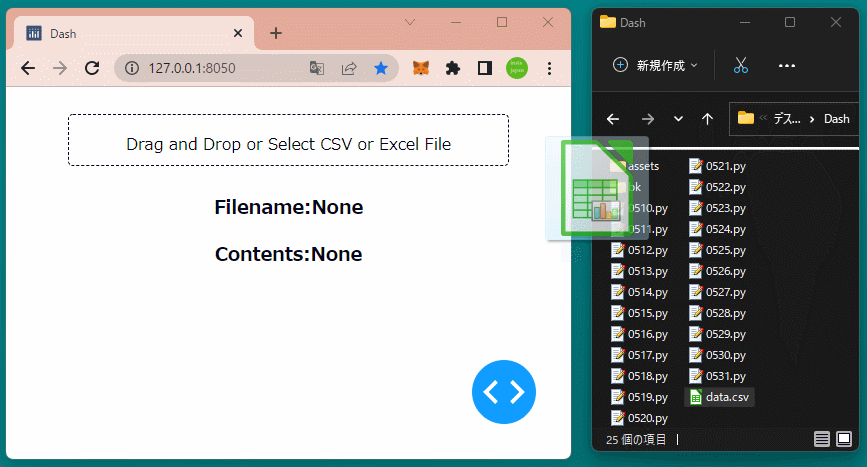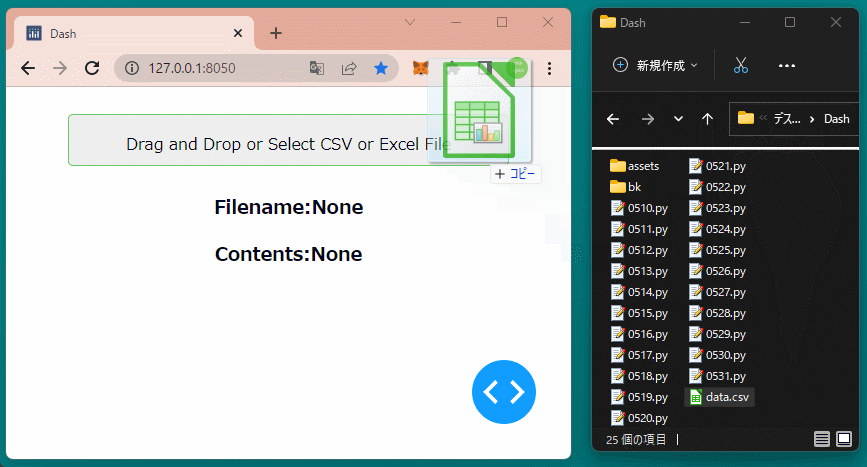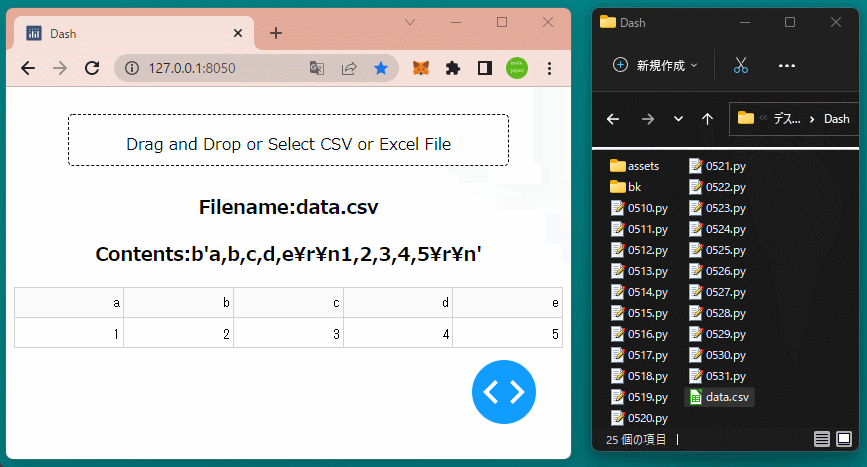
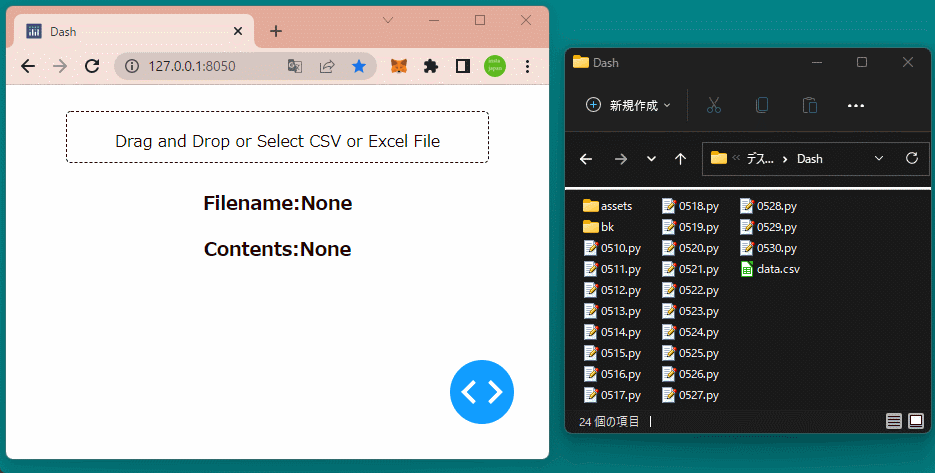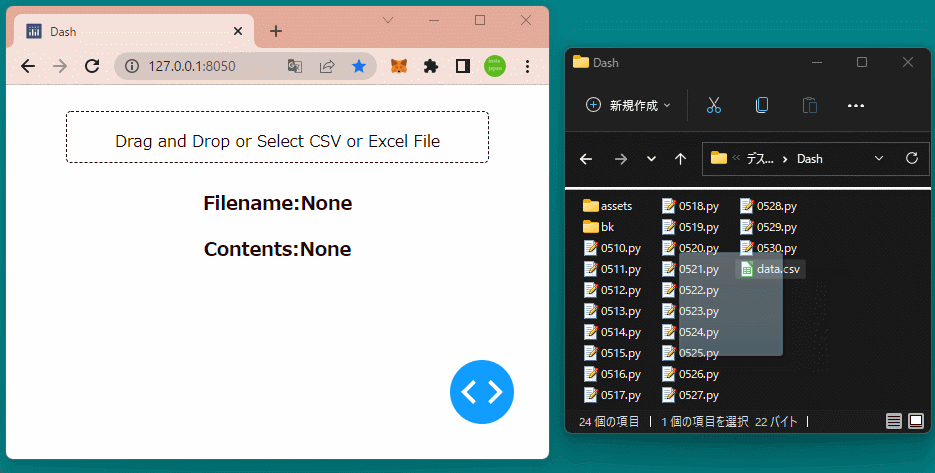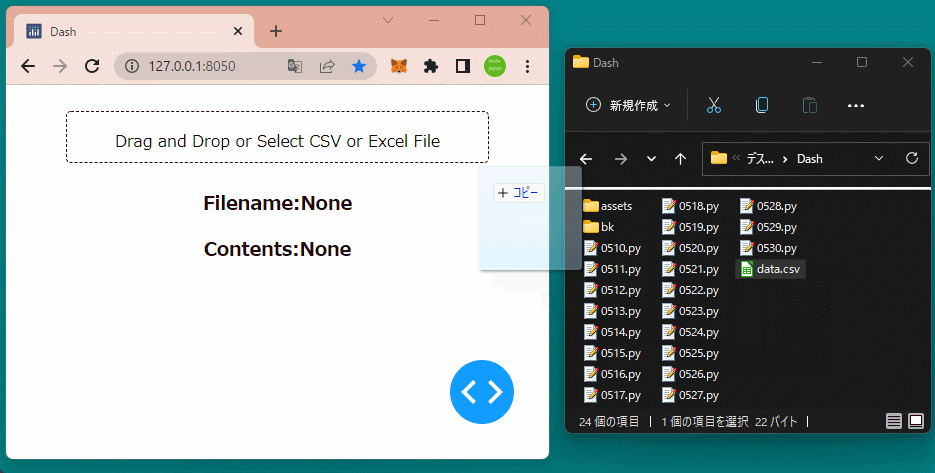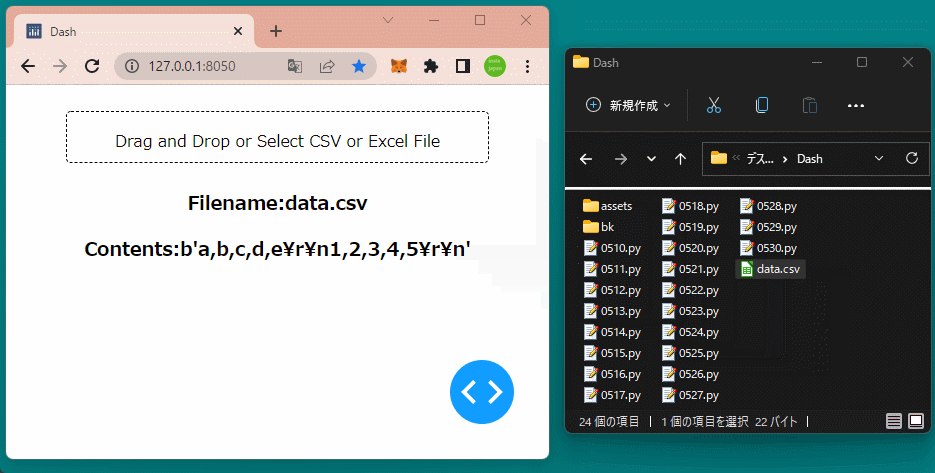
html.H3(id='filename1', style={'textAlign':'center'}),
html.H3(id='content1', style={'textAlign':'center'}),
html.Div(id='table1'),
html.Div(id='graph1'),
]
)
@app.callback(
Output('filename1', 'children'),
Output('content1', 'children'),
Output('table1', 'children'),
Output('graph1', 'children'),
Input('upload1', 'filename'),
Input('upload1', 'contents')
)
def update_content(filename, contents):
decoded = None
table1 = None
graph1 = None
if contents:
content_type, content_string = contents.split(',')
decoded = base64.b64decode(content_string)
df = pd.read_csv(io.StringIO(decoded.decode('utf-8')))
table1 = dash_table.DataTable(data=df.to_dict('records'),
columns=[{'name':i, 'id':i} for i in df.columns])
graph1 = dcc.Graph(figure=px.line(df, x='col1', y='col2'))
return 'Filename:{}'.format(filename), 'Contents:{}'.format(decoded), table1, graph1
if __name__ == '__main__':
app.run_server(debug=True)
|