表記の揺れとは、ある言語の文字表記において、2通り以上の書き方をされることにより、表記にばらつきが生じることです。
表記の揺れのデータ残っているとデータを正しく分類することができません。同じデータでも異なるものとして分類されてしまうからです。
そのためデータ分析前には表記の揺れを除去する必要があります。
表記の揺れの代表的なパターンは次の一覧の通りです。
| 表記ゆれのパターン | 表記ゆれの例 |
|---|---|
| 半角・全角 | カナガワ/カナガワ |
| 漢字・カナ | 猫/ネコ/ねこ |
| 送り仮名 | 切り替え/切替 |
| 語尾 | ユーザー/ユーザ |
| 数字 | 1年/一年 |
| 英単語 | スピード/speed |
| 固有名詞 | Macintosh/mac |
| 大文字・小文字 | Kanagawa/kanagawa/KANAGAWA |
| 省略形 | I would like to/I'd like to |
大文字・小文字の表記の揺れを統一
大文字と小文字の表記の揺れがあるデータを定義しデータをカウントしてみます。
1 | import pandas as pd |
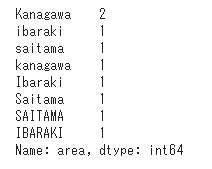
同じ地域でも別データとしてカウントされていることが分かります。
そこで、小文字表記に統一して再度データをカウントします。
1 | df['area'] = df.area.apply(lambda x:x.lower()) |
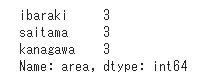
地域ごとに正しくカウントされるようになりました。
(実行環境としてGoogleさんのColaboratoryを使用ています。)
次回は、重複データの削除を行います。