データセットには同じレコードが複数存在することがあります。(行データの重複)
またデータ名が違っているのにデータの値が全て同じという事もあります。(列データの重複)
行または列に重複するデータあるかどうかを確認し、重複がある場合は重複行/重複列を削除します。
重複行の削除
重複行のあるデータを定義します。
1 | import pandas as pd |
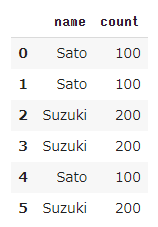
SatoさんとSuzukiさんの同じレコードが3件ずつありますが、同じデータが複数あっても意味がありませんので、それぞれ1レコード分に修正します。
重複行の削除はdrop_duplicates関数を使って簡単に行うことができます。
1 | df = df.drop_duplicates() |
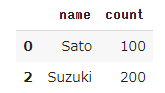
3レコード分あった重複データが1レコード分に修正されました。
重複列の削除
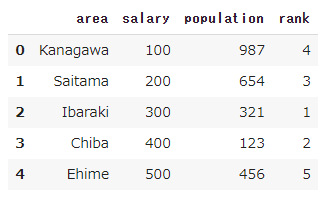
重複列があるデータを定義します。
1 | df = pd.DataFrame([['Kanagawa', 100, 987, 4, 100], |
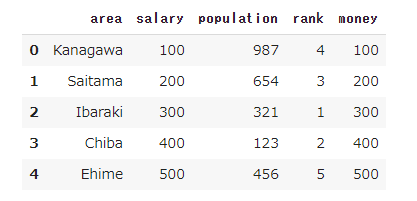
salaryとmoneyが全く同じことが分かりますが、データがたくさんあると重複列があるかとうかを確認するのは大変です。
そこでヒートマップを使うと相関を可視化することができ、重複行を簡単に見つけることができます。
1 | import seaborn as sns |
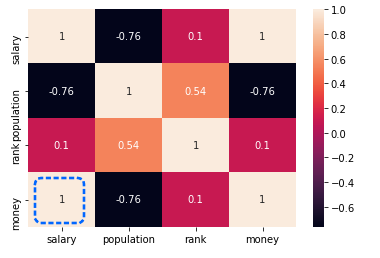
ヒートマップの一番左下が相関係数1.0であり、この2つの変数が重複の可能性があることを確認できます。
ただし、相関係数が1.0であってもかならず重複列であるとは限らないので、かならず実際のデータを確認して重複列であるかどうかの最終判断を行ってください。
重複列であることを確認できたらdrop関数を使って重複列の1つを削除します。
今回はsalary列を残して、money列を削除することにします。
1 | df = df.drop('money', axis=1) |
money列が削除されたことが確認できました。
(実行環境としてGoogleさんのColaboratoryを使用ています。)
次回は、データの型変換を行います。