データセットの中に分析に向かないデータがある場合、分析に適した形式に変更する必要があります。
例えば、「男」「女」のようなテキストデータの場合、seabornのヒートマップでは可視化できないため「男」→0、「女」→1のように数値へ変換します。
データセットに対してのいろいろな変換パターンがありますが、今回はデータ型の変換を実行してみます。
テキストデータから数値データへの変換
テキストデータを数値データに変換する例を次の一覧に示します。
| 変換前(テキスト) | 変換後(数値) |
|---|---|
| 男/女 | 0/1 |
| 良い/普通/悪い | 0/1/2 |
| 神奈川支店/千葉支店 | 100/200 |
タイタニックのデータセットには性別データ(male/female)がありますので、これを数値データに変換します。
まずはデータセットを読み込み、性別のデータを表示します。
1 | import seaborn as sns |
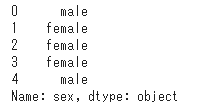
「male」を0に、「female」を1に変換するコードは次の通りです。
apply関数を使うと各データに関数を適用することができます。
1 | df = titanic['sex'].apply(lambda x: 0 if x == 'male' else 1) |
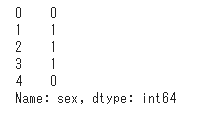
想定通りにテキストデータを数値データに変換することができました。
数値データからテキストデータへの変換
視点や切り口を変えてデータを分析するために、数値データからテキストデータへ変換を行うことがあります。
例えば、年齢のような数値データを「幼年/少年/成人/熟年」のように変換しデータの尺度を変えると、元の数値データには見えない特徴が見えることがあります。
タイタニックの年齢データを次の一覧のようにテキストデータに変換します。
| 変換前(数値) | 変換後(テキスト) |
|---|---|
| 0歳から6歳 | 幼年 |
| 7歳から15歳 | 少年 |
| 16歳から30歳 | 青年 |
| 31歳から45歳 | 壮年 |
| 46歳から60歳 | 中年 |
| 61歳以上 | 熟年 |
まずは元の年齢データを表示して数値を確認します。
1 | titanic['age'].head() |
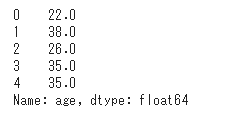
年齢をテキストデータに変換するコードは下記の通りです。
再びapply関数を使いますが、条件分岐が多いためlambdaを使わず事前に関数定義を行っています。
1 | # 年齢をテキストデータに変換 |

年齢に応じて青年、壮年などのテキストデータが表示されます。
(実行環境としてGoogleさんのColaboratoryを使用ています。)
次回は、要約統計量の表示を行います。