クリッピングとはデータの一部を抽出することです。
クリッピングすることで、分析に悪影響を及ぼすと考えられる外れ値を対象外とします。
(実行環境としてGoogleさんのColaboratoryを使用します。)
タイタニック データセットの読み込み
まずタイタニックのデータセットを読み込みます。
1 | import seaborn as sns |
外れ値の判定
料金(fare)の統計量を確認してみます。
1 | titanic.fare.describe() |
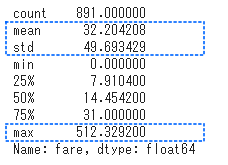
平均が32、標準偏差が49、最大値が512と分布に偏りがあるようです。
次にヒストグラムを表示して、分布を可視化してみます。
1 | plt.figure(figsize=(10,5)) |
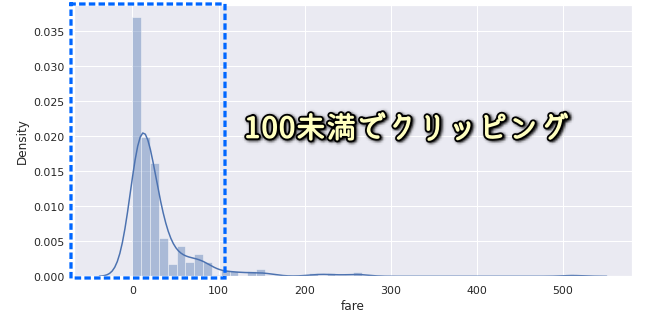
100以上のデータは度数が少なく偏りが大きいと見受けられますので、100未満のデータでクリッピングすることにします。
クリッピング
100未満のデータをクリッピングし、再度ヒストグラムを表示します。
1 | titanic = titanic[titanic['fare'] < 100] |
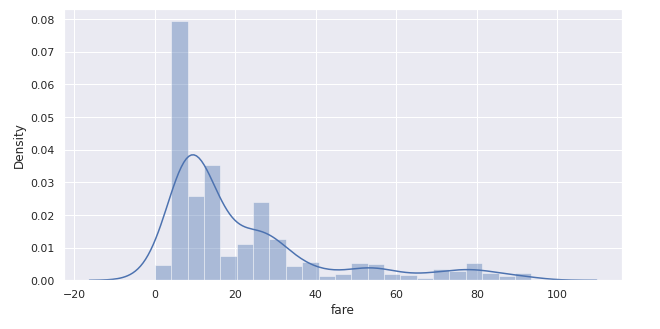
クリッピング前よりだいぶ偏りが少なくなったようです。
最後に、クリッピング後の統計量を確認します。
1 | titanic.fare.describe() |
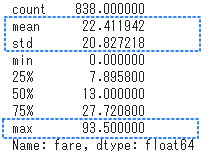
平均が22、標準偏差が20、最大値が93となり、統計量からも偏りが減少したことを確認できました。
次回は、表記の揺れの対応を行います。