データに外れ値がある場合、データ分析の結果に大きく影響を与えてしまいます。
特に平均値などの抵抗性が弱い統計量や相関係数にも影響を及ぼすので、データ分析を行う前に外れ値が存在しているかどうか確認し、必要であれば外れ値を除外する必要があります。
(実行環境としてGoogleさんのColaboratoryを使用します。)
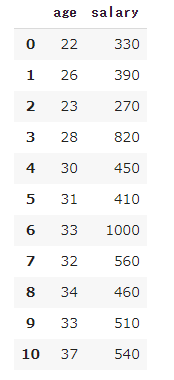
データを作成する
例として年齢と年収のデータを作成します。
1 | import pandas as pd |
散布図で外れ値を確認する
散布図を表示し、外れ値のあたりをつけてみます。
1 | import seaborn as sns |
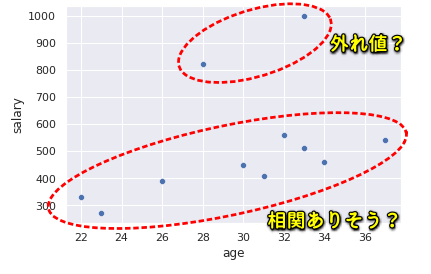
どうやら800万円以上の年収が外れ値のようです。
相関関係を確認する
相関係数を使って、年齢と年収の関係性の強さを調べます。
(相関係数は一般的に、+1 に近ければ近いほど「強い正の相関がある」、−1 に近ければ近いほど「強い負の相関がある」、0 に近ければ近いほど「ほとんど相関がない」と評価されます。)
まずは外れ値を含んだままで相関関係を確認します。相関係数の算出にはcorr関数を使います。
1 | df.corr()['age']['salary'] |
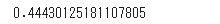
相関係数は0.44と相関が高くありません。
次に年収800万円を外れ値として除外し、そのデータで相関係数をとってみます。
1 | df=df[df['salary']>800] |

相関係数が1.0となり、外れ値を除外した後は強い相関関係があることがわかります。
次回は、外れ値の判断基準として四分位範囲(しぶんいはんい)による外れ値の判定を行います。