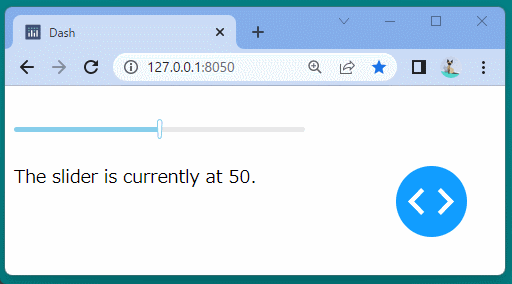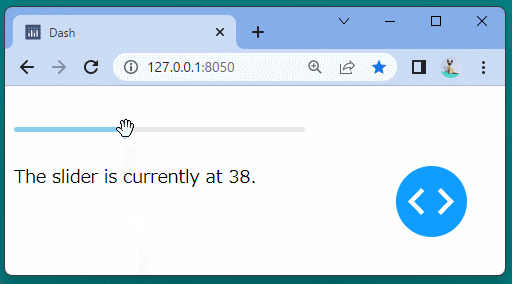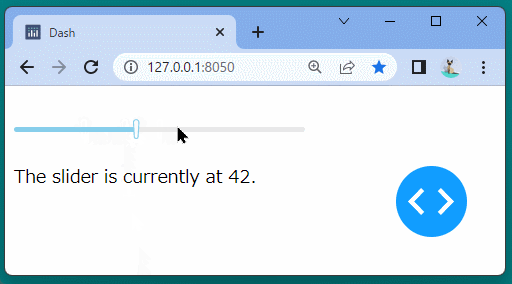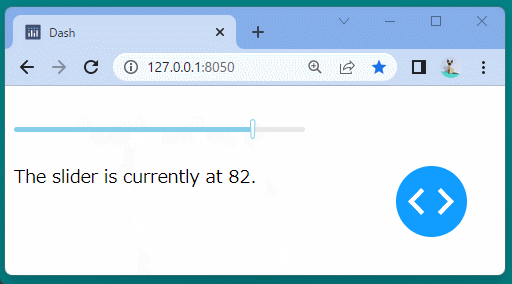
@app.callback( Output('slider-result', 'children'), Input('our-daq-slider-ex', 'value') ) defupdate_output(value): return'The slider is currently at {}.'.format(value)
if __name__ == '__main__': app.run_server(debug=True)
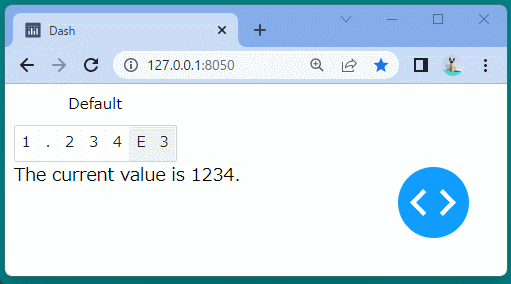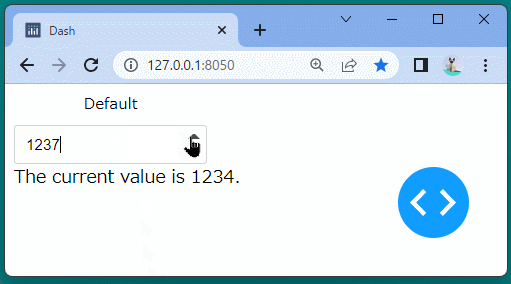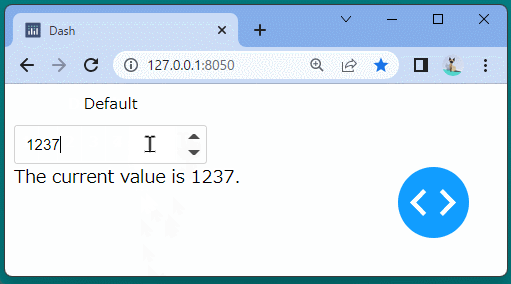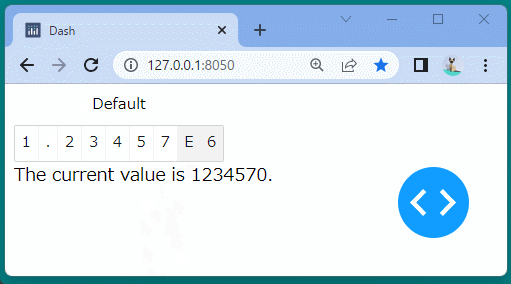
@app.callback( Output('precision-result', 'children'), Input('our-precision', 'value') ) defupdate_output(value): return'The current value is {}.'.format(value)
if __name__ == '__main__': app.run_server(debug=True)