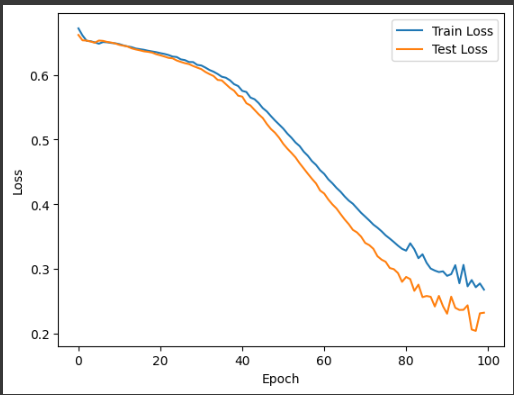
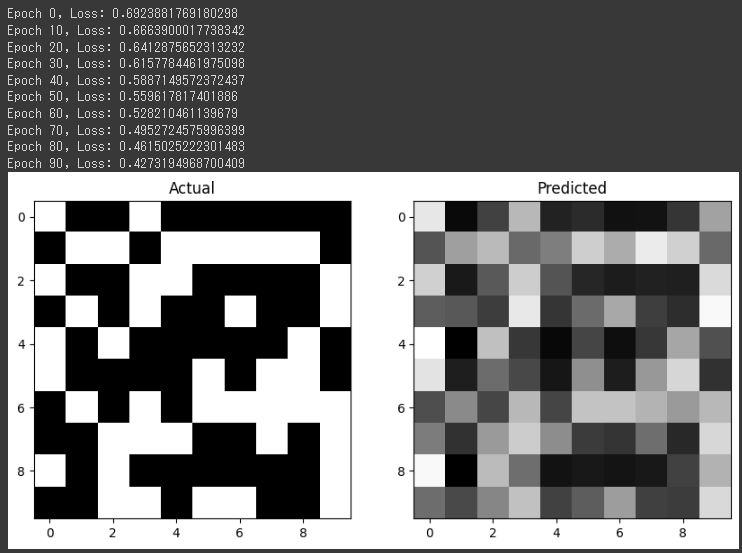
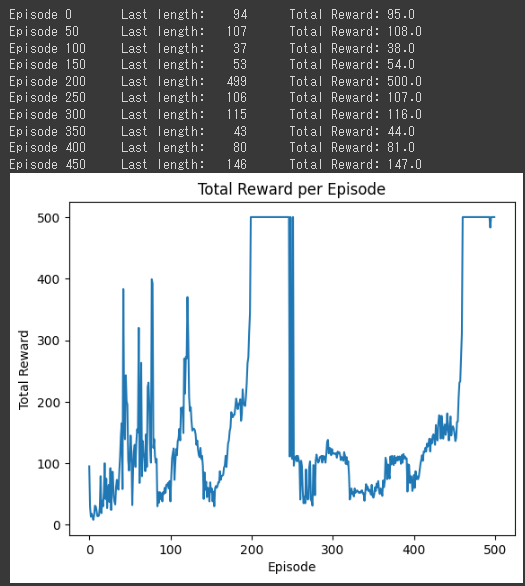
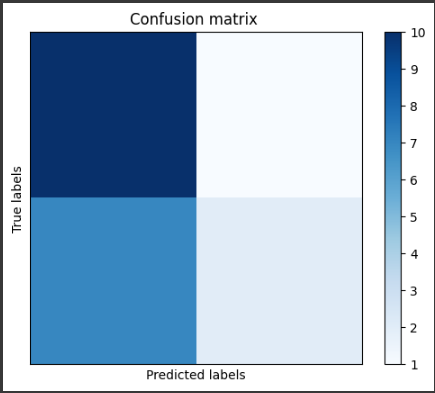
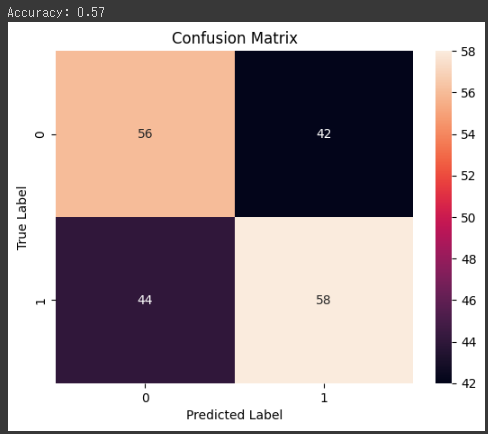
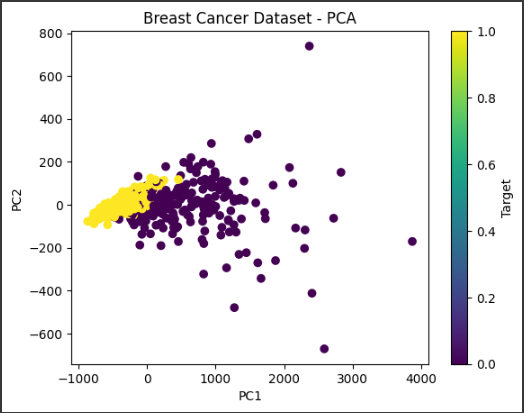
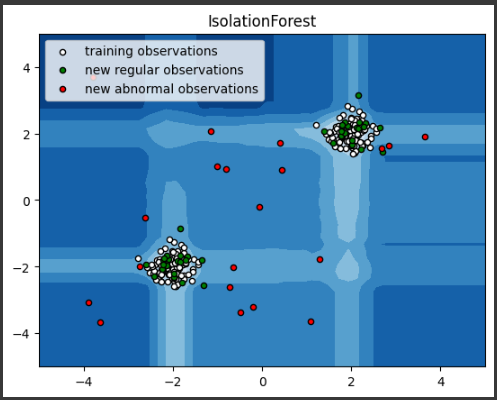
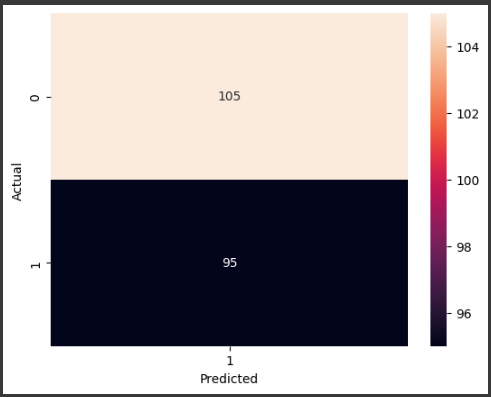
このサンプルでは、乳がんのデータセットであるBreast Cancer Wisconsin (Diagnostic) Data Setを使用します。
データセットはscikit-learnライブラリから利用できます。
また、結果を分かりやすくするためにMatplotlibを使用してグラフ化します。
まず、必要なライブラリをインポートします。
1 2 3 4 5 6
import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt
次に、データセットをロードして前処理を行います。
1 2 3 4 5 6 7 8 9 10
# データセットの読み込み data = load_breast_cancer() X, y = data.data, data.target
# データをPyTorchのテンソルに変換 X = torch.tensor(X, dtype=torch.float32) y = torch.tensor(y, dtype=torch.float32).view(-1, 1)
import gym import numpy as np import torch import torch.nn as nn import torch.optim as optim from torch.distributions import Categorical import matplotlib.pyplot as plt
defselect_action(state): state = torch.from_numpy(state).float().unsqueeze(0) probs = policy(state) m = Categorical(probs) action = m.sample() policy.saved_log_probs.append(m.log_prob(action)) return action.item()
deffinish_episode(): R = 0 policy_loss = [] returns = [] for r in policy.rewards[::-1]: R = r + 0.99 * R returns.insert(0, R) returns = torch.tensor(returns) returns = (returns - returns.mean()) / (returns.std() + 1e-6) for log_prob, R inzip(policy.saved_log_probs, returns): policy_loss.append(-log_prob * R) optimizer.zero_grad() policy_loss = torch.cat(policy_loss).sum() policy_loss.backward() optimizer.step() del policy.rewards[:] del policy.saved_log_probs[:]
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import confusion_matrix, accuracy_score import seaborn as sns
次に、仮想的なデータセットを作成します。
ここでは、年齢とタンパク質レベルの2つの特徴量を持つ1000人の患者データを生成します。
また、各患者がアルツハイマー病であるかどうかをランダムに決定します。
1 2 3
np.random.seed(0) X = np.random.randint(60, 100, (1000, 2)) # Age and Protein level y = np.random.choice([0, 1], 1000) # 0: Healthy, 1: Alzheimer's
データを訓練セットとテストセットに分割します。
1
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
import numpy as np import pandas as pd from sklearn.datasets import load_breast_cancer from sklearn.decomposition import PCA import matplotlib.pyplot as plt
# データセットの読み込み data = load_breast_cancer() X = data.data y = data.target
import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression import matplotlib.pyplot as plt import seaborn as sns
# 仮想データセットの作成 np.random.seed(0) age = np.random.randint(20, 70, 1000) income = np.random.randint(20000, 100000, 1000) will_pay_back = np.random.randint(0, 2, 1000)
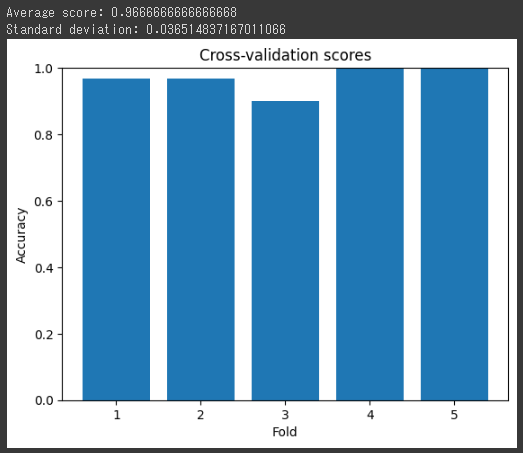
from sklearn.datasets import load_iris from sklearn.model_selection import cross_val_score from sklearn.tree import DecisionTreeClassifier import matplotlib.pyplot as plt import numpy as np
# データセットのロード iris = load_iris() X, y = iris.data, iris.target