Scenario
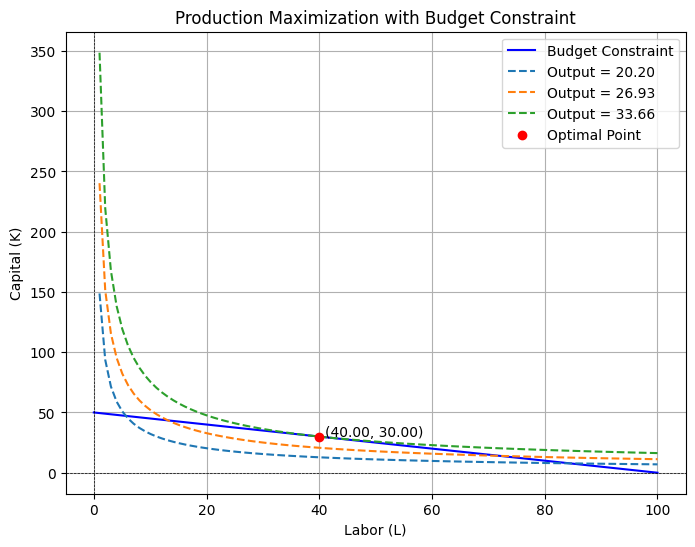
A firm produces a good using two inputs: labor (L) and capital (K).
The firm seeks to minimize its production costs while meeting a target output $( Q )$.
The cost function is:
$$
C = w \cdot L + r \cdot K
$$
- $( C )$: Total cost
- $( w )$: Wage rate (cost of labor)
- $( r )$: Rental rate of capital (cost of capital)
- $( L )$: Amount of labor used
- $( K )$: Amount of capital used
The production function is:
$$
Q = L^{0.5} \cdot K^{0.5}
$$
The firm must meet a specific output level $( Q = 10 )$.
The goal is to find the optimal values of $( L )$ and $( K )$ to minimize costs.
Python Implementation
Here is the $Python$ code to solve the cost minimization problem using SciPy.
1 | import numpy as np |
Explanation of the Code
Cost Function:
- The function $( C = w \cdot L + r \cdot K )$ calculates total cost for given $( L )$ and $( K )$.
Constraint:
- The output constraint ensures the production level $( Q )$ equals the target $( Q_{target} )$.
Optimization:
scipy.optimize.minimizeis used to minimize the cost function while satisfying the production constraint and non-negativity bounds for $( L )$ and $( K )$.
Visualization:
- The cost curve is plotted for varying labor values $( L )$, with the corresponding $( K )$ values derived from the production constraint.
- The optimal point is highlighted.
Results and Graphical Representation
Optimal Labor (L): 14.14 Optimal Capital (K): 7.07 Minimum Cost: 282.84
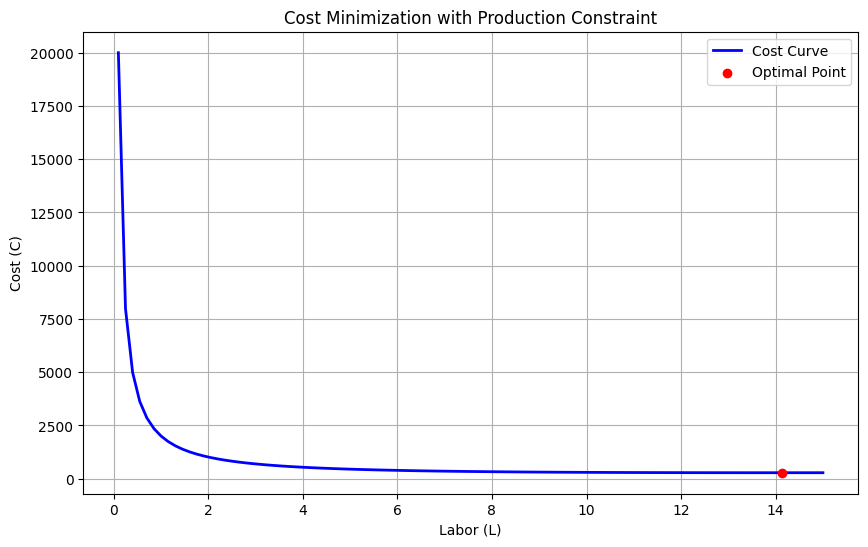
Optimal Values:
- The solution provides the values of $( L )$ and $( K )$ that minimize costs while producing the target output.
Graph:
- The blue curve represents the total cost for different allocations of labor and capital.
- The red point marks the minimum cost, highlighting the optimal combination of $( L )$ and $( K )$.
This example demonstrates how firms can allocate resources efficiently to minimize production costs while meeting output targets.