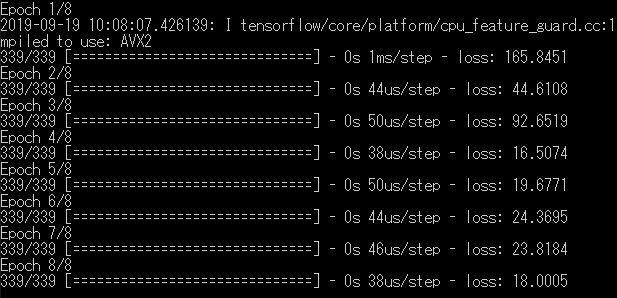
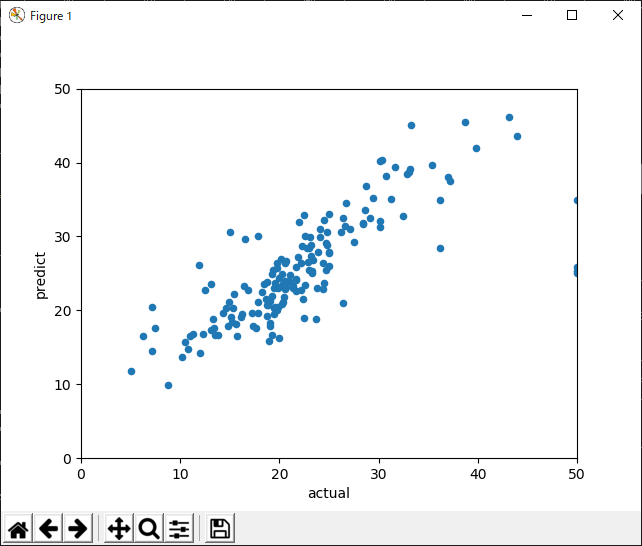
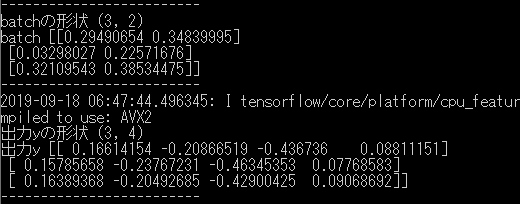
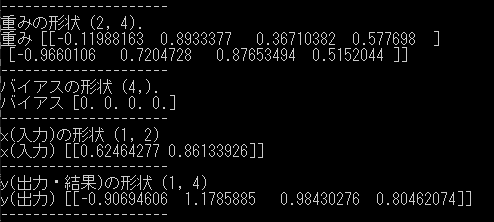
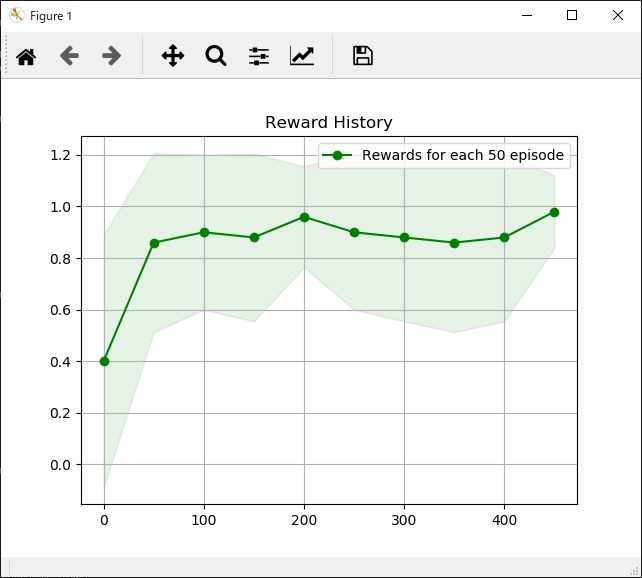
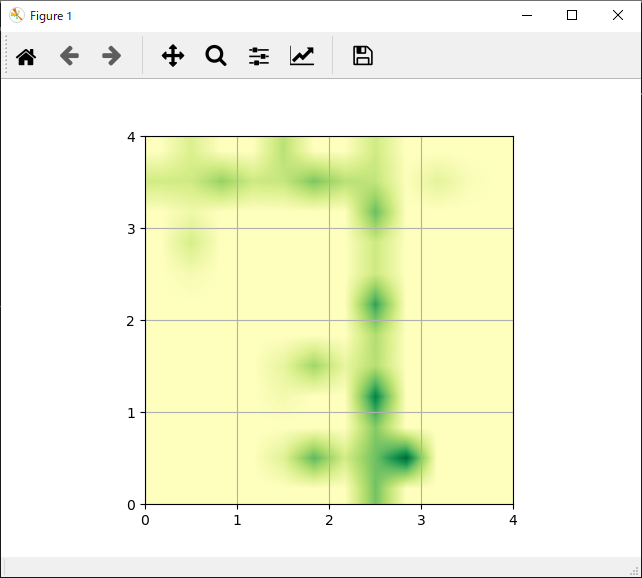
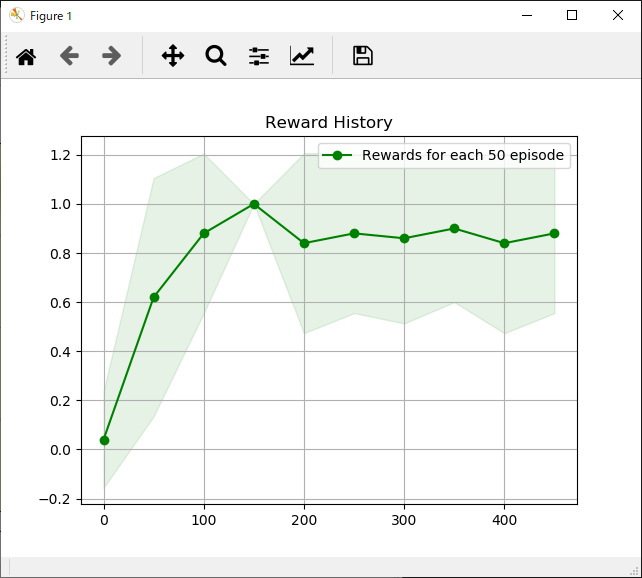
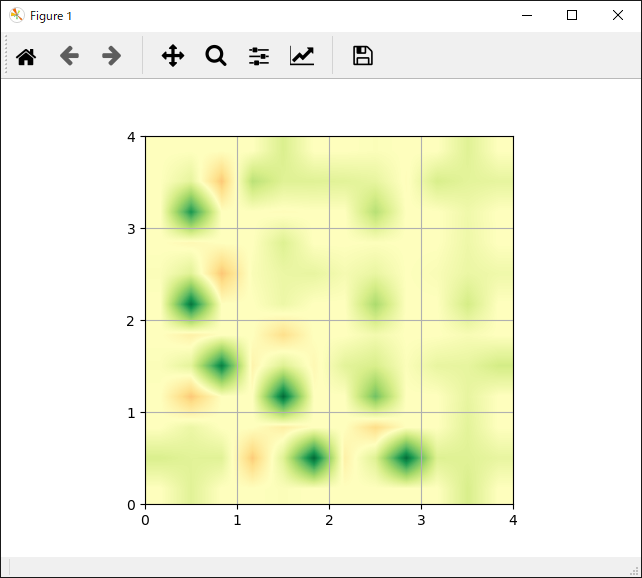
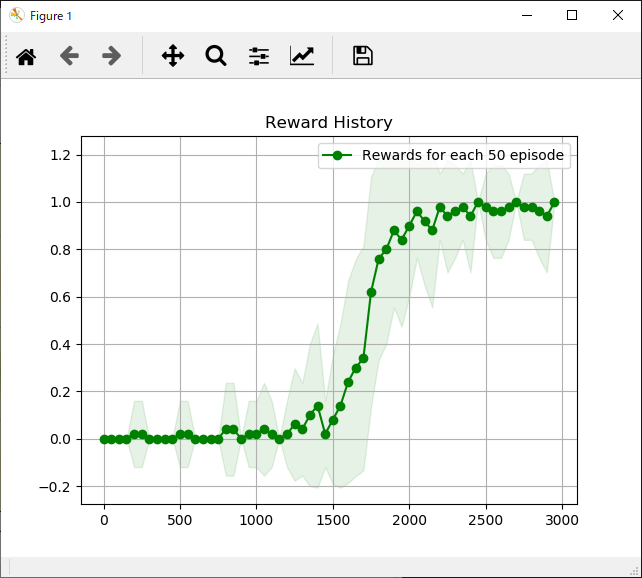
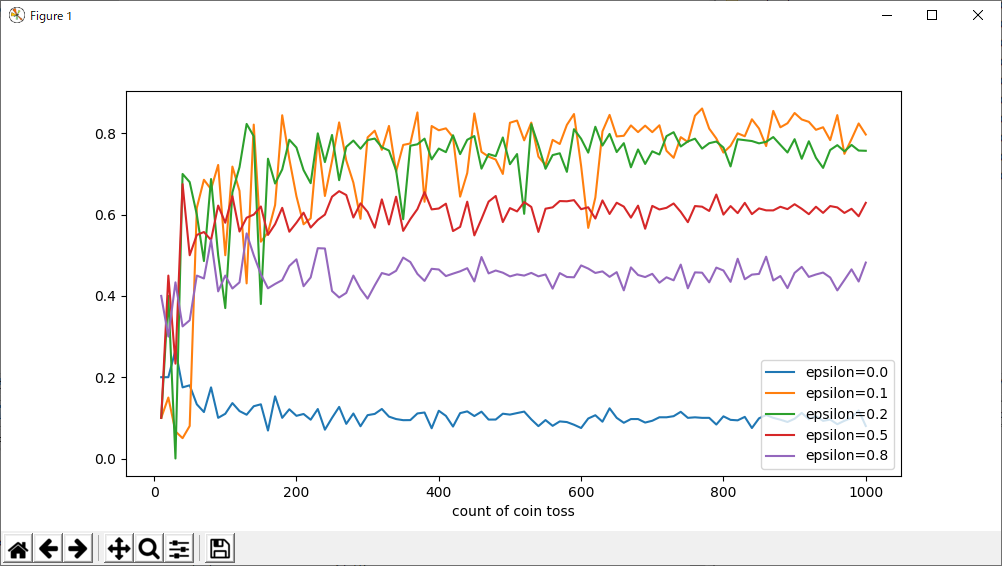
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
| import numpy as np
import gym
from el_agent import ELAgent
from frozen_lake_util import show_q_value
class Actor(ELAgent):
def __init__(self, env):
super().__init__(epsilon=-1)
nrow = env.observation_space.n
ncol = env.action_space.n
self.actions = list(range(env.action_space.n))
self.Q = np.random.uniform(0, 1, nrow * ncol).reshape((nrow, ncol))
def softmax(self, x):
return np.exp(x) / np.sum(np.exp(x), axis=0)
def policy(self, s):
a = np.random.choice(self.actions, 1,
p=self.softmax(self.Q[s]))
return a[0]
class Critic():
def __init__(self, env):
states = env.observation_space.n
self.V = np.zeros(states)
class ActorCritic():
def __init__(self, actor_class, critic_class):
self.actor_class = actor_class
self.critic_class = critic_class
def train(self, env, episode_count=1000, gamma=0.9,
learning_rate=0.1, render=False, report_interval=50):
actor = self.actor_class(env)
critic = self.critic_class(env)
actor.init_log()
for e in range(episode_count):
s = env.reset()
done = False
while not done:
if render:
env.render()
a = actor.policy(s)
n_state, reward, done, info = env.step(a)
gain = reward + gamma * critic.V[n_state]
estimated = critic.V[s]
td = gain - estimated
actor.Q[s][a] += learning_rate * td
critic.V[s] += learning_rate * td
s = n_state
else:
actor.log(reward)
if e != 0 and e % report_interval == 0:
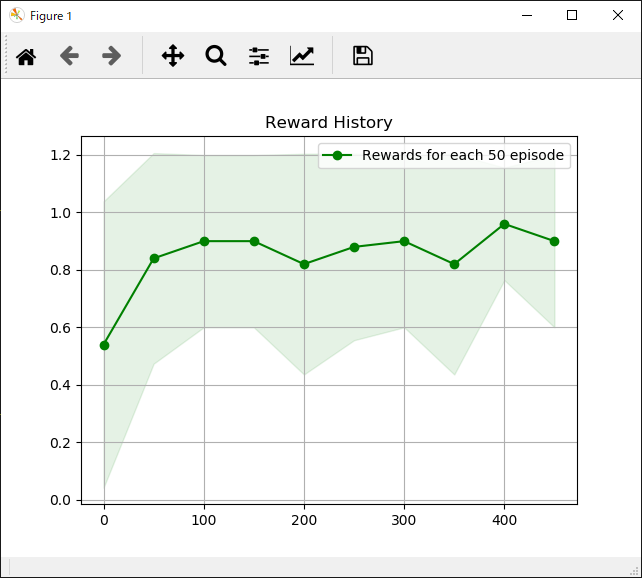
actor.show_reward_log(episode=e)
return actor, critic
def train():
trainer = ActorCritic(Actor, Critic)
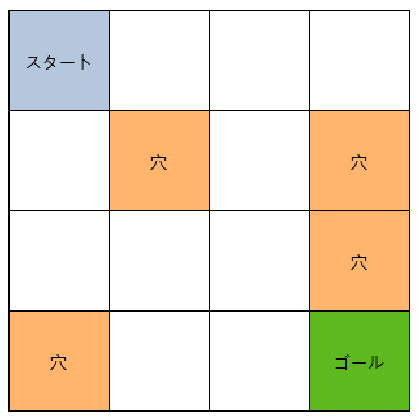
env = gym.make("FrozenLakeEasy-v0")
actor, critic = trainer.train(env, episode_count=3000)
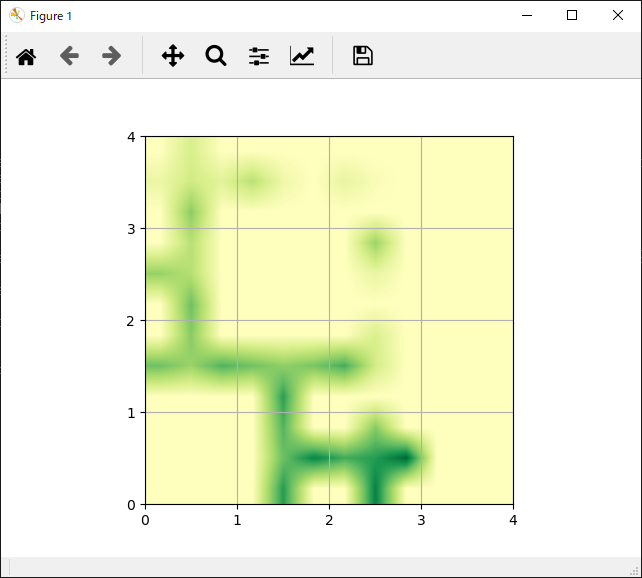
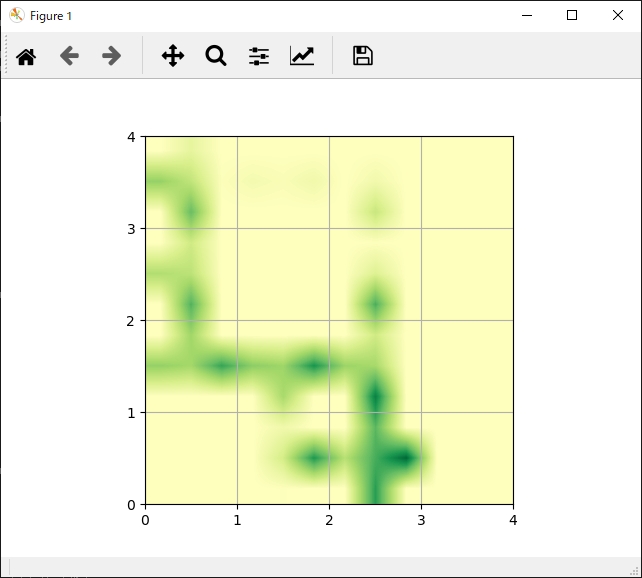
show_q_value(actor.Q)
actor.show_reward_log()
if __name__ == "__main__":
train()
|