スマホの画面をPCに表示することができる「LetsView」をご紹介します。
LetsView- https://letsview.com/jp/
次のような用途で使用すると便利かと思います。
- スマホ内の写真や動画をPCに転送することなくPCで確認する。
- スマホの操作動画をPCで撮影する。
※PCとスマホは同じLANに接続している必要があります。
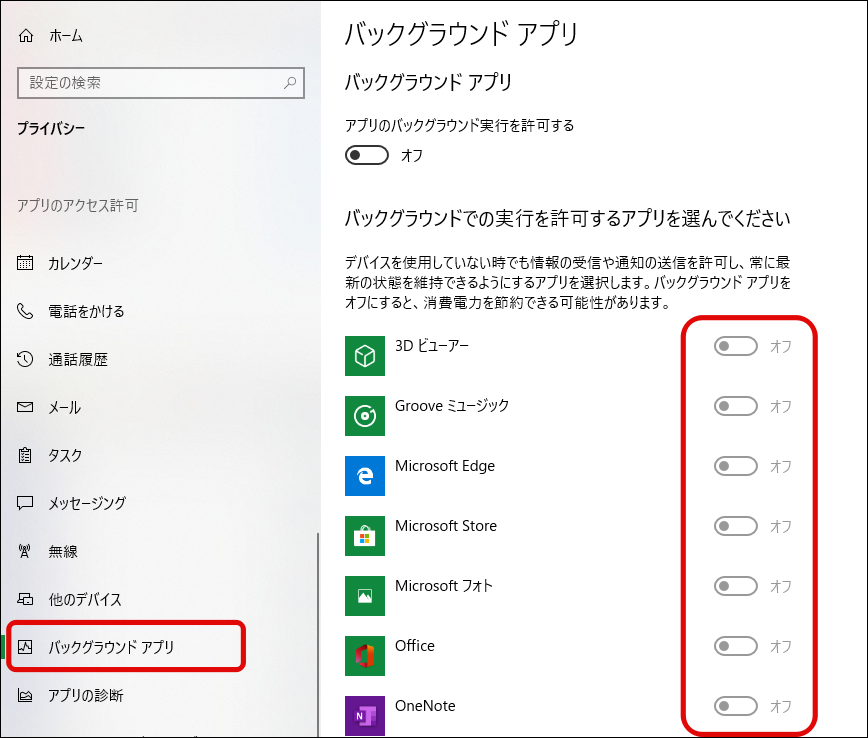
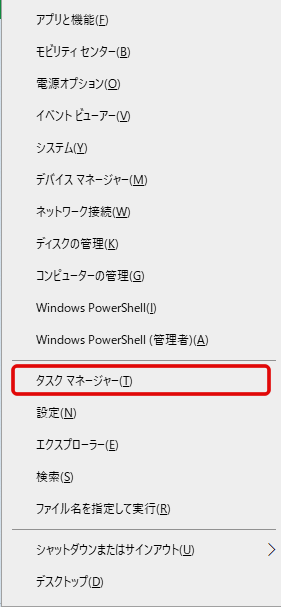
PC スマホ ①インストール
まずパソコンとスマホ(Android)に「LetsView」をインストールします。
PCは上記URLからインストーラをダウンロードしてインストールします。すべてデフォルト設定でのインストールで問題ありません。
スマホ(Android)はPlayストアからインストールします。
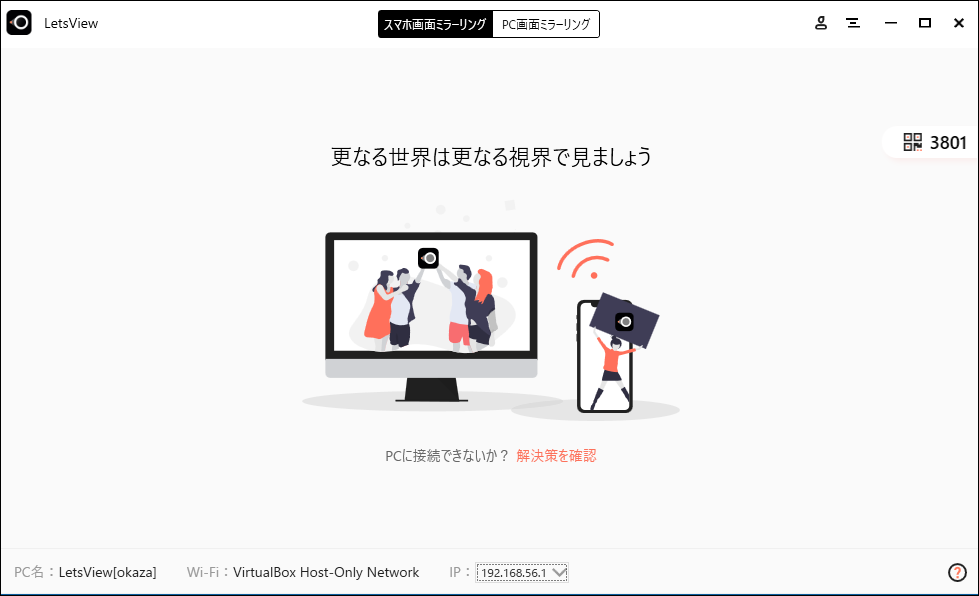
PC ②LetsView起動
PC側で「LestView」を起動します。起動後の画面は次のようになります。
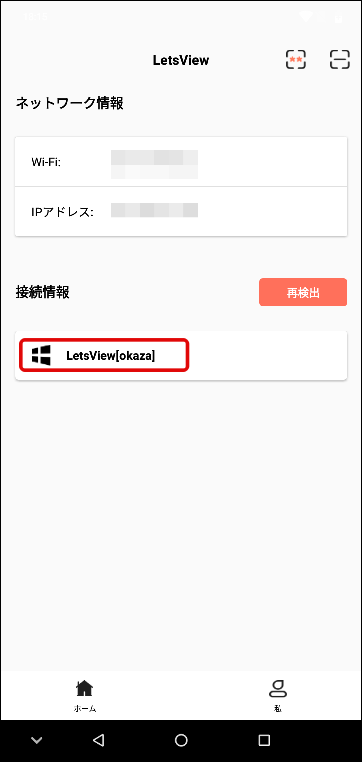
スマホ ③LetsView起動・接続するPCを選択
スマホ側で「LestView」を起動します。
次のような画面が表示されますので接続するPCを選択します。
PCが表示されていない場合は、同じネットワークに接続されているかどうか、「LetsView」が起動しているかどうかを確認して下さい。
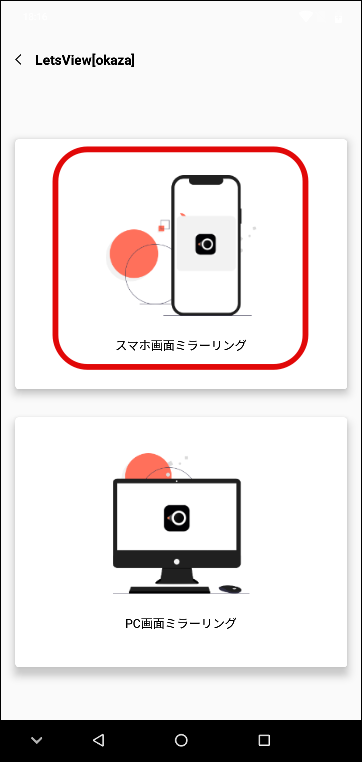
スマホ ④スマホ画面のミラーリング
「スマホ画面のミラーリング」を選択します。
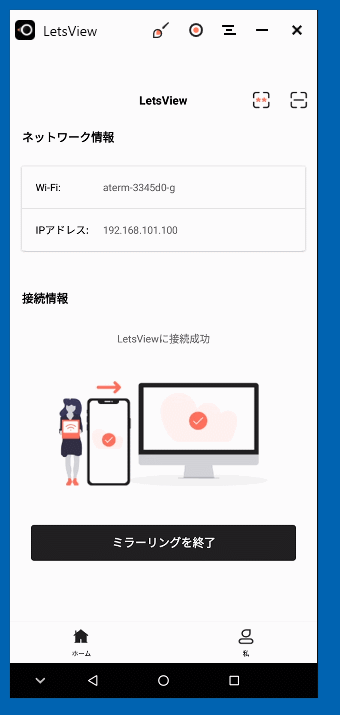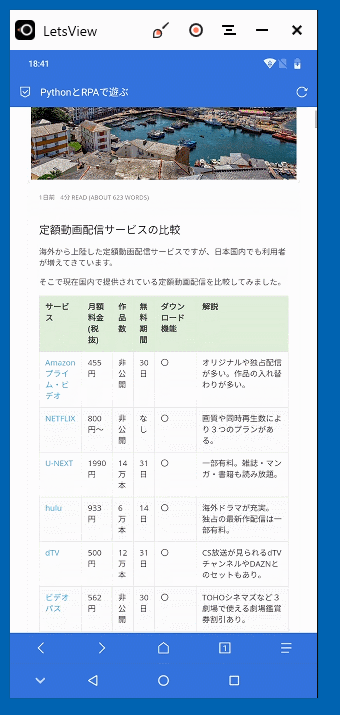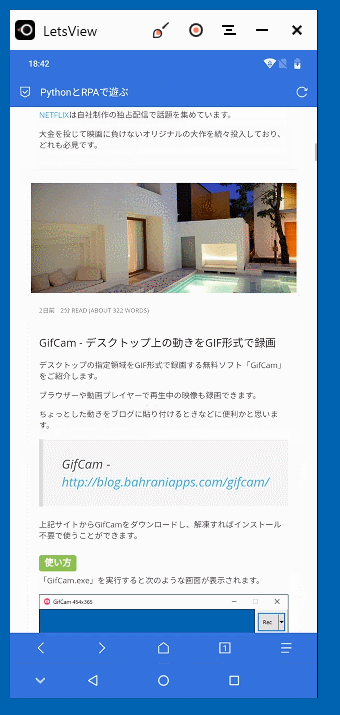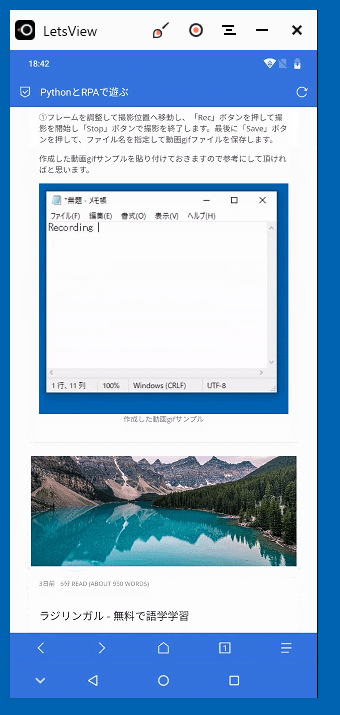
スマホ ⑤接続確認
PCに接続が成功すると次のように表示されます。

PC ⑥動作確認
PCにスマホ画面が表示されます。スマホ側を操作するとPC側でも表示が更新されます。
スマホ操作中のPC側表示を動画gifにしてみましたので参考にして下さい。
※PC側でのスマホ操作はできないようで少々残念ですが、スマホ操作をPCで録画できるようになったのでよかったです。