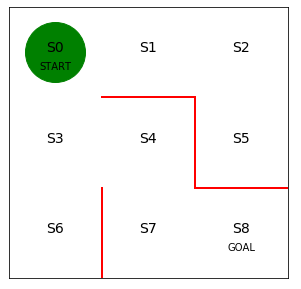
Dueling Networkという深層強化学習を実装します。
Dueling NetworkではQ関数を2つに分けて学習します。
- 状態sだけで決まるV(s)
- 行動しだいできまるAdvantage関数 A(s,a)
最後にこの2関数を足してQ(s,a)と決めます。
使用するパッケージをインポートします。
1 | # パッケージのimport |
動画ファイルを保存する関数を定義します。
1 | # 動画の描画関数の宣言 |
経験(Transition)を表すnamedtupleを生成します。
状態 state、行動 action、次の状態 next_state、報酬 rewardに容易にアクセスできます。
1 | # namedtupleを生成 |
定数を宣言します。
1 | # 定数の設定 |
経験を保存するメモリクラスを定義します。
経験を保存する関数 push、ランダムに経験を取り出す関数 sampleがあります。
1 | # 経験を保存するメモリクラスを定義します |
Dueling Network型のディープ・ニューラルネットワークを構築します。
Advantage側の層 fc3_advと状態価値の層 fc3_vを作成します。
最後に出力する行動価値 output は上記2つを足したものとなります。
1 | # Dueling Network型のディープ・ニューラルネットワークの構築 |
Brainクラスを実装します。
このクラスがニューラルネットワークを保持します。
1 | # エージェントが持つ脳となるクラスです、Dueling Networkを実行します |
棒付き台車を表すAgentクラスを実装します。
関数 memorizeでメモリオブジェクトに経験したデータ transitionを格納します。
1 | # CartPoleで動くエージェントクラスです、棒付き台車そのものになります |
CartPoleを実行する環境クラスを定義します。
表形式表現のように離散化は行わず、観測結果 observationをそのままstateとして使用します。
1 | # CartPoleを実行する環境のクラスです |
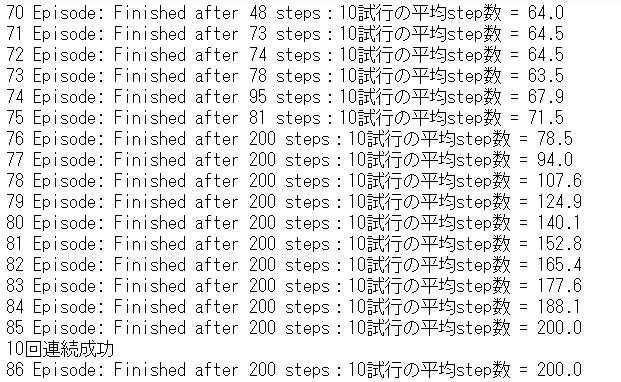
学習を実行します。
1 | # main クラス |
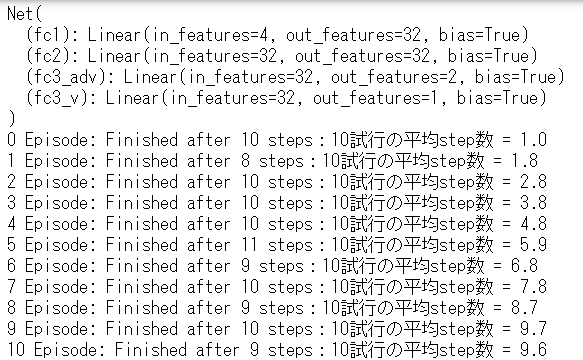
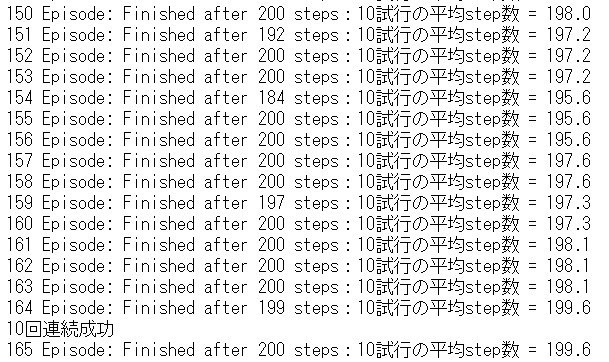
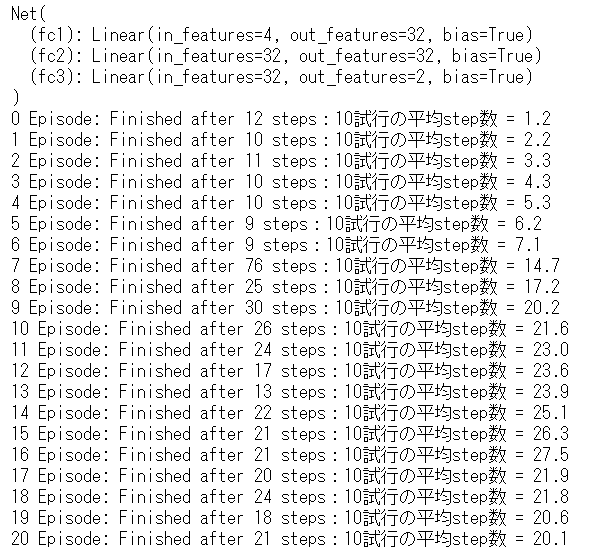
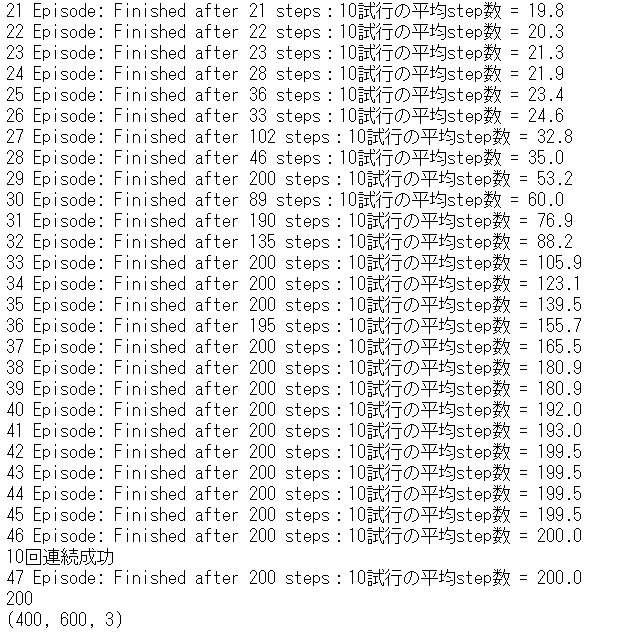
164エピソードで学習が完了しました。
出力された動画ファイル’6_3movie_cartpole_dueling_network.mp4’は下記のようになります。
参考 > つくりながら学ぶ!深層強化学習 サポートページ