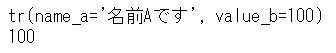深層強化学習でOpenAI GymのCartPoleを攻略します。
使用するパッケージをインポートします。
1 2 3 4 5 import numpy as npimport matplotlib.pyplot as plt%matplotlib inline import gym
動画ファイルを保存する関数を定義します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from JSAnimation.IPython_display import display_animationfrom matplotlib import animationfrom IPython.display import displaydef display_frames_as_gif (frames ): plt.figure(figsize=(frames[0 ].shape[1 ]/72.0 , frames[0 ].shape[0 ]/72.0 ), dpi=72 ) patch = plt.imshow(frames[0 ]) plt.axis('off' ) def animate (i ): patch.set_data(frames[i]) anim = animation.FuncAnimation(plt.gcf(), animate, frames=len (frames), interval=50 ) anim.save('5_4movie_cartpole_DQN.mp4' )
namedtupleを使うことで、値をフィールド名とペアで格納でき、値に対してフィールド名でアクセスできて便利です。
1 2 3 4 5 6 7 from collections import namedtupleTr = namedtuple('tr' , ('name_a' , 'value_b' )) Tr_object = Tr('名前Aです' , 100 ) print (Tr_object)print (Tr_object.value_b)
経験(Transition)を表すnamedtupleを生成します。
1 2 3 from collections import namedtupleTransition = namedtuple('Transition' , ('state' , 'action' , 'next_state' , 'reward' ))
定数を宣言します。
1 2 3 4 5 ENV = 'CartPole-v0' GAMMA = 0.99 MAX_STEPS = 200 NUM_EPISODES = 500
ミニバッチ学習を実現するために、経験データを保存しておくメモリクラス ReplayMemoryを定義します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class ReplayMemory : def __init__ (self, CAPACITY ): self .capacity = CAPACITY self .memory = [] self .index = 0 def push (self, state, action, state_next, reward ): '''transition = (state, action, state_next, reward)をメモリに保存する''' if len (self .memory) < self .capacity: self .memory.append(None ) self .memory[self .index] = Transition(state, action, state_next, reward) self .index = (self .index + 1 ) % self .capacity def sample (self, batch_size ): '''batch_size分だけ、ランダムに保存内容を取り出す''' return random.sample(self .memory, batch_size) def __len__ (self ): '''関数lenに対して、現在の変数memoryの長さを返す''' return len (self .memory)
Brainクラスを実装します。
関数 replayはメモリクラスからミニバッチを取り出し、ニューラルネットワークの結合パラメータを学習し、Q関数を更新します。
メモリサイズの確認
メモリサイズがミニバッチより小さい間は何もしない。
ミニバッチの作成
メモリからミニバッチ分のデータを取り出す。
各変数をミニバッチに対応する形に変形する。
各変数の要素をミニバッチに対応する形に変形する。
教師信号となるQ値を算出
ネットワークを推論モードに切り替える。
ネットワークが出力したQ値を求める。
maxQ値を求める。
教師となるQ値をQ学習の式から求める。
結合パラメータの更新
ネットワークを訓練モードに切り替える。
損失関数の値を計算する。
結合パラメータを更新する。
関数 decide_actionはε-greedy法によりランダムな行動 または 現在の状態に対してQ値が最大となる行動のindexを返します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 import randomimport torchfrom torch import nnfrom torch import optimimport torch.nn.functional as FBATCH_SIZE = 32 CAPACITY = 10000 class Brain : def __init__ (self, num_states, num_actions ): self .num_actions = num_actions self .memory = ReplayMemory(CAPACITY) self .model = nn.Sequential() self .model.add_module('fc1' , nn.Linear(num_states, 32 )) self .model.add_module('relu1' , nn.ReLU()) self .model.add_module('fc2' , nn.Linear(32 , 32 )) self .model.add_module('relu2' , nn.ReLU()) self .model.add_module('fc3' , nn.Linear(32 , num_actions)) print (self .model) self .optimizer = optim.Adam(self .model.parameters(), lr=0.0001 ) def replay (self ): '''Experience Replayでネットワークの結合パラメータを学習''' if len (self .memory) < BATCH_SIZE: return transitions = self .memory.sample(BATCH_SIZE) batch = Transition(*zip (*transitions)) state_batch = torch.cat(batch.state) action_batch = torch.cat(batch.action) reward_batch = torch.cat(batch.reward) non_final_next_states = torch.cat([s for s in batch.next_state if s is not None ]) self .model.eval () state_action_values = self .model(state_batch).gather(1 , action_batch) non_final_mask = torch.ByteTensor(tuple (map (lambda s: s is not None , batch.next_state))) next_state_values = torch.zeros(BATCH_SIZE) next_state_values[non_final_mask] = self .model( non_final_next_states).max (1 )[0 ].detach() expected_state_action_values = reward_batch + GAMMA * next_state_values self .model.train() loss = F.smooth_l1_loss(state_action_values, expected_state_action_values.unsqueeze(1 )) self .optimizer.zero_grad() loss.backward() self .optimizer.step() def decide_action (self, state, episode ): '''現在の状態に応じて、行動を決定する''' epsilon = 0.5 * (1 / (episode + 1 )) if epsilon <= np.random.uniform(0 , 1 ): self .model.eval () with torch.no_grad(): action = self .model(state).max (1 )[1 ].view(1 , 1 ) else : action = torch.LongTensor( [[random.randrange(self .num_actions)]]) return action
棒付き台車を表すAgentクラスを実装します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Agent : def __init__ (self, num_states, num_actions ): '''課題の状態と行動の数を設定する''' self .brain = Brain(num_states, num_actions) def update_q_function (self ): '''Q関数を更新する''' self .brain.replay() def get_action (self, state, episode ): '''行動を決定する''' action = self .brain.decide_action(state, episode) return action def memorize (self, state, action, state_next, reward ): '''memoryオブジェクトに、state, action, state_next, rewardの内容を保存する''' self .brain.memory.push(state, action, state_next, reward)
CartPoleを実行する環境クラスを定義します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 class Environment : def __init__ (self ): self .env = gym.make(ENV) num_states = self .env.observation_space.shape[0 ] num_actions = self .env.action_space.n self .agent = Agent(num_states, num_actions) def run (self ): '''実行''' episode_10_list = np.zeros(10 ) complete_episodes = 0 episode_final = False frames = [] for episode in range (NUM_EPISODES): observation = self .env.reset() state = observation state = torch.from_numpy(state).type ( torch.FloatTensor) state = torch.unsqueeze(state, 0 ) for step in range (MAX_STEPS): if episode_final is True : frames.append(self .env.render(mode='rgb_array' )) action = self .agent.get_action(state, episode) observation_next, _, done, _ = self .env.step( action.item()) if done: state_next = None episode_10_list = np.hstack( (episode_10_list[1 :], step + 1 )) if step < 195 : reward = torch.FloatTensor( [-1.0 ]) complete_episodes = 0 else : reward = torch.FloatTensor([1.0 ]) complete_episodes = complete_episodes + 1 else : reward = torch.FloatTensor([0.0 ]) state_next = observation_next state_next = torch.from_numpy(state_next).type ( torch.FloatTensor) state_next = torch.unsqueeze(state_next, 0 ) self .agent.memorize(state, action, state_next, reward) self .agent.update_q_function() state = state_next if done: print ('%d Episode: Finished after %d steps:10試行の平均step数 = %.1lf' % ( episode, step + 1 , episode_10_list.mean())) break if episode_final is True : display_frames_as_gif(frames) break if complete_episodes >= 10 : print ('10回連続成功' ) episode_final = True
学習を実行します。
1 2 3 cartpole_env = Environment() cartpole_env.run()
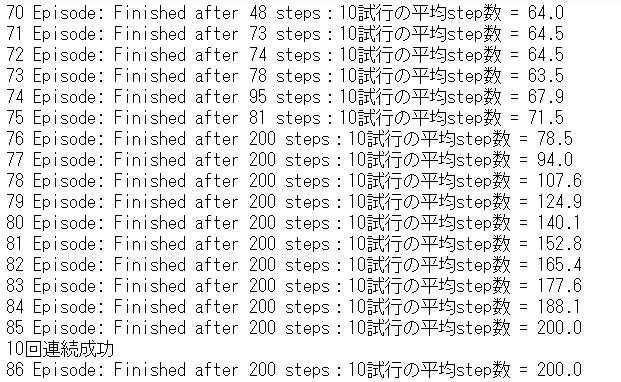
85エピソードで学習が完了しました。
VIDEO
参考
>
つくりながら学ぶ!深層強化学習 サポートページ