前回はランダムに行動する方策を実装しましたが、今回は方策勾配法に従ってエージェントを動かしてみます。
まず使用するパッケージをインポートします。
1 | # 使用するパッケージの宣言 |
次に迷路の初期状態を描画します。
1 | # 初期位置での迷路の様子 |
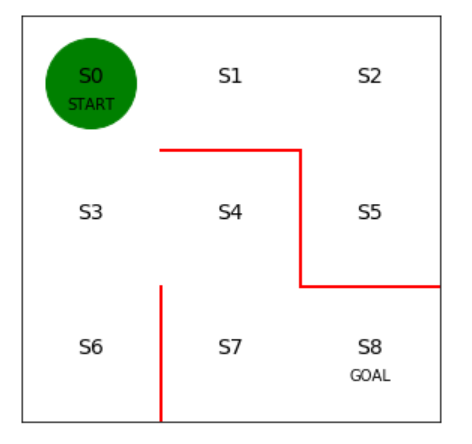
初期の方策を決定するパラメータtheta_0を設定します。
行は状態0~7を表し、列は上、右、下、左へ行動できるかどうかを表します。
状態8はゴールなので方策の定義は不要です。
1 | # 初期の方策を決定するパラメータtheta_0を設定 |
方策パラメータ(theta)をsoftmax関数で行動方策(pi)に変換する関数を定義します。
betaは逆温度と呼ばれ、小さいほど行動がランダムになります。
さらに指数関数(np.exp)を使って割合を計算しています。
softmax関数を使用するとパラメータθが負の値になっても方策を算出できるというメリットがあります。
1 | # 方策パラメータthetaを行動方策piにソフトマックス関数で変換する手法の定義 |
上記で定義したsoftmax_convert_into_pi_from_theta関数を使ってθ0から方策を算出します。
1 | # 初期の方策pi_0を求める |

学習前のため前回(ランダム行動)の方策と同じ結果になりますが問題ありません。
続いてsoftmax関数による方策に従ってエージェントを行動させる関数を実装します。
1ステップ移動後のエージェントの状態とその時の行動を返します。
1 | # 行動aと1step移動後の状態sを求める関数を定義 |
ゴールにたどり着くまでエージェントを移動させ続ける関数を定義します。
状態と行動の履歴をセットで返します。
1 | # 迷路を解く関数の定義、状態と行動の履歴を出力 |
初期の方策で迷路を解いてみます。
1 | # 初期の方策で迷路を解く |

スタートからゴールまでの状態と行動のセットが表示されます。
最後にトータルで何ステップかかったかを表示しています。
方策勾配法に従い方策を更新する関数を定義します。
学習率etaは1回の学習で更新される大きさを表します。
学習率が小さすぎるとなかなか学習が進みませんし、大きすぎるときちんと学習することができません。
方策の更新のために下記の3つを入力しています。
- 現在の方策 theta
- 方策 pi
- 現在の方策での実行結果 s_a_history
1 | # thetaの更新関数を定義します |
方策を更新し、方策がどう変化するのかを確認します。
1 | # 方策の更新 |

最初の方策から少し変化していることが分かります。
迷路をノーミスでクリアできるまで迷路内の探索とパラメータθの更新を繰り返す処理を実装します。
学習終了条件は課題に応じて調整する必要がありますが、今回は方策変化の絶対値和が10**-4より小さくなったら終了とします。
1 | # 方策勾配法で迷路を解く |

最終的にゴールまで最小ステップ数の4となっていることが分かります。
最終的な方策を確認してみます。
1 | # 最終的な方策を確認 |

最後に動画でエージェントの移動を可視化します。
1 | # エージェントの移動の様子を可視化します |
スタート地点からまっすぐゴールにたどり着いていることが分かります。
(Google Colaboratoryで動作確認しています。)
参考
つくりながら学ぶ!深層強化学習 サポートページ