インベーダーゲームで一番成績の良かった学習アルゴリズム ACKTR をいろいろな環境で実行してみます。
今回は ブロック崩し(BreakoutNoFrameskip-v4) を攻略します。
BreakoutNoFrameskip-v4を攻略
ACKTR の学習済みモデル(Stable Baselines Zoo提供)を使ってBreakoutNoFrameskip-v4を実行し、その様子を動画ファイルに出力します。
各オプションは以下の通りです。
- 環境(env)
BreakoutNoFrameskip-v4 - 学習アルゴリズム(algo)
ACKTR - ステップ数(n)
3000
[コマンド]
1 | python3.7 -m utils.record_video --algo acktr --env BreakoutNoFrameskip-v4 -n 3000 |
実行結果は以下のようになりました。(Ubuntu 19.10で動作確認しています。)
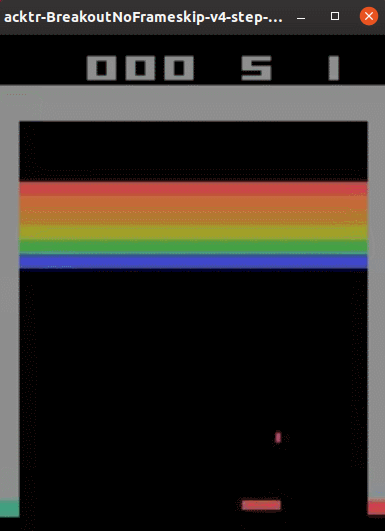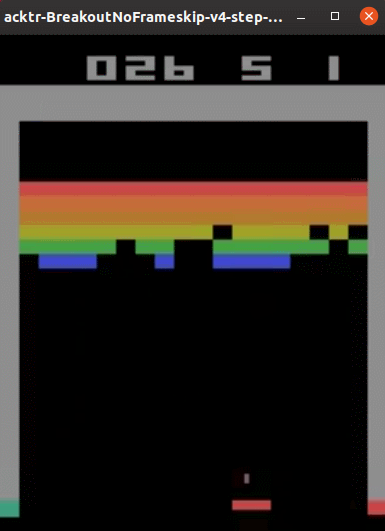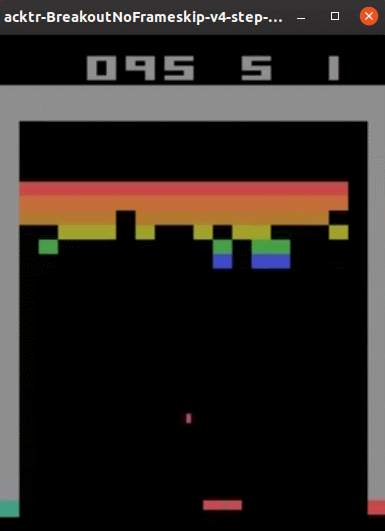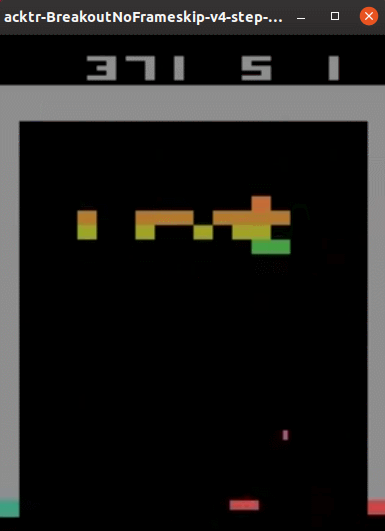
なかなかのプレイ内容です。順調にブロックを崩していきますが、ブロック数が少なくなった最後の方では無限ループのようなプレイになってしまいました。