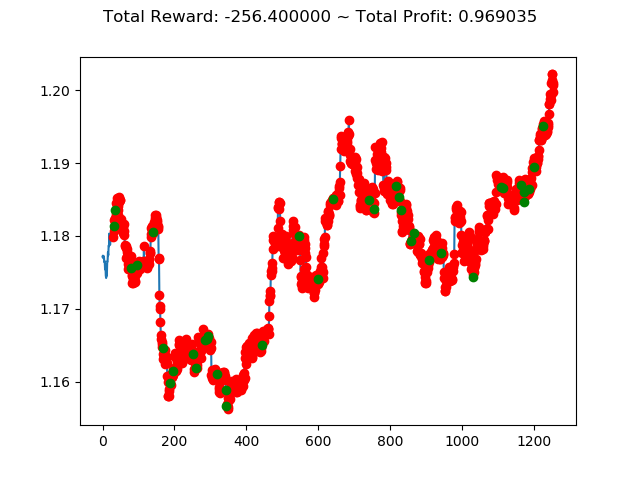
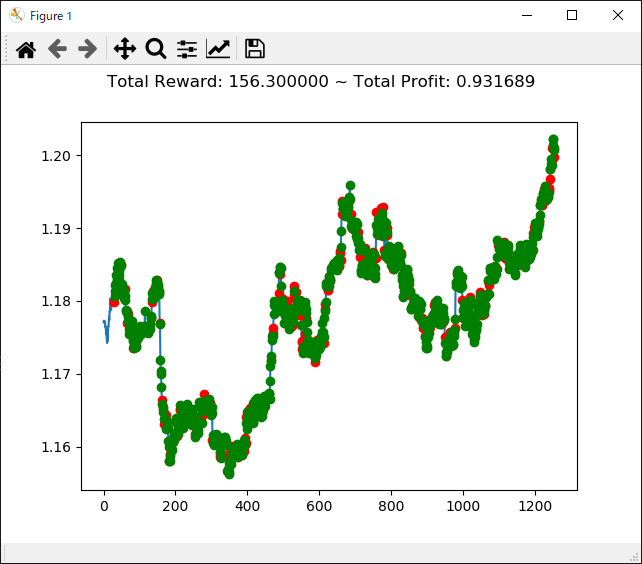
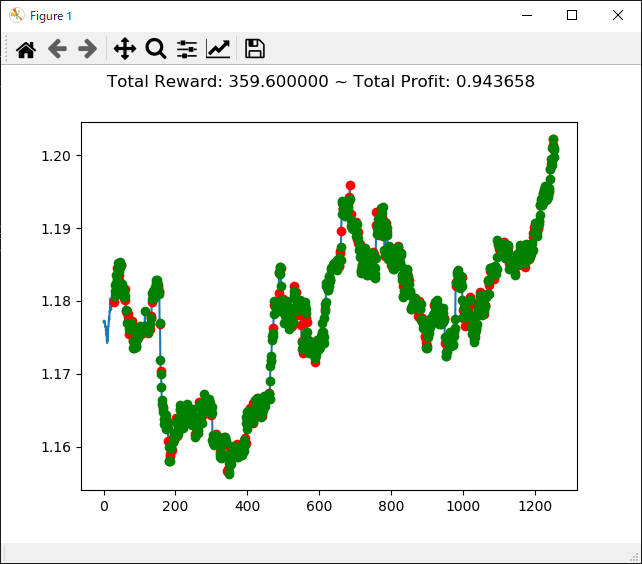
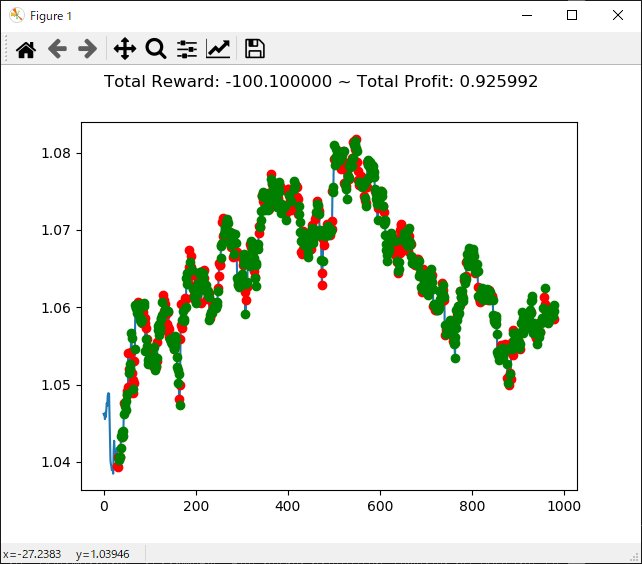
2020年になってコロナショックがあり大幅に動いた投資市場ですが、こんなときに強化学習で投資してたらどうなっていたのか気になったので検証してみます。
コロナショック時の投資シミュレーション(ACKTR)
検証データとしては USDJPYの分足データ を 2020年1月の最初から2020年5年の最後 までを使い、学習データとしては 2019年6月から2019年12月 のデータを使います。
今回は 強化学習アルゴリズムとしてACKTR を使い、前回使用した学習アルゴリズム PPO2 との結果を比較します。
1 | import os, gym |
35行目のアルゴリズム PPO2 をコメントアウトし、36行目のアルゴリズム ACKTR を有効化します。
FXトレードを実行
上記コードを実行すると次のような結果になります。
[コンソール出力]
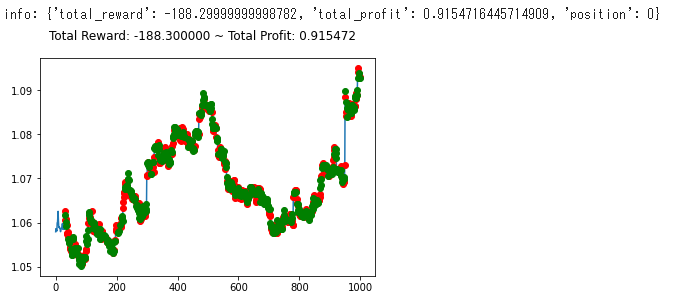
1 | info: {'total_reward': -68300.00000000806, |
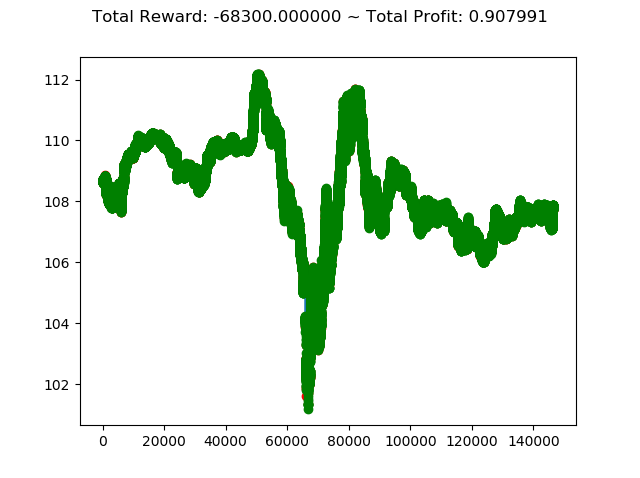
学習アルゴリズムを PPO2 から ACKTR に変更し、投資成績は次のように変化しました。
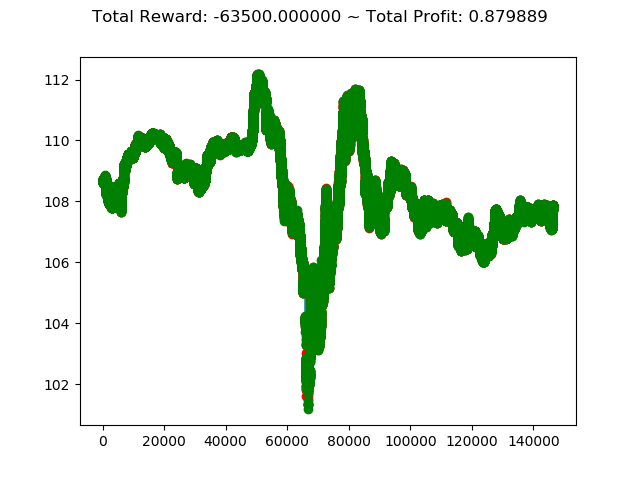
- トータル報酬 -63500 → -68300
- トータル収益 0.879 → 0.907
トータル報酬では PPO2 の方が成績がよく、トータル収益では ACKTR の方がやや上という結果になりました。
ただ今回はトータル報酬がどちらもかなりのマイナスなので、どちらのアルゴリズムでもコロナショック下の投資環境ではうまくいかないということが分かりました。
ただコロナショック直前のデータを学習したものでシミュレーションしたので、リーマンショック時など今回の状況に似たデータを学習すれば結果が変わるのかもしれません。