Windowsを使っていて絵文字を入力したい場合は、次のショートカットを使うと便利です。
Windowキー + .(ドット)
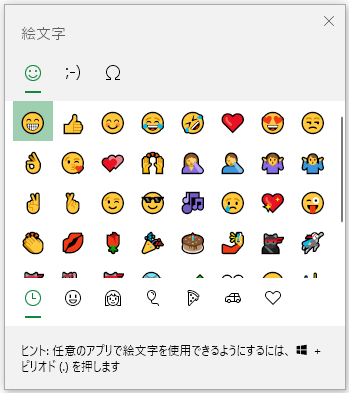
絵文字は6種類のカテゴリーがあり、絵文字だけでなく顔文字や記号も選ぶことができます。
Windowsを使っていて絵文字を入力したい場合は、次のショートカットを使うと便利です。
Windowキー + .(ドット)
今回は、Pythonで白地図を作る方法をご紹介します。
matplotlib basemap - https://matplotlib.org/basemap/
Anaconda Promptを開いて下記のコマンドを実行します。
1 | conda install -c conda-forge basemap |
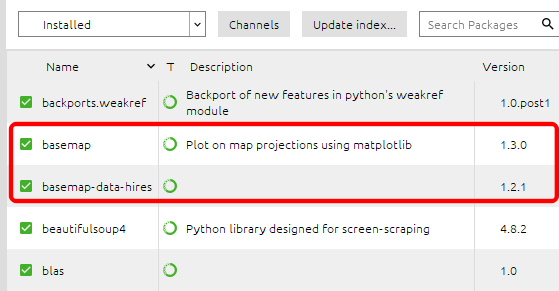
インストールに成功すると Anaconda Navigator でライブラリ一覧に「basemap」と「basemap-data-hires」が表示されます。
日本の白地図を表示するために下記のコードを準備します。
14-15行目で描画したい範囲の緯度と経度の座標を指定しています。
16行目のresolutionは解像度を指定しています。
1 | import matplotlib.pyplot as plot |
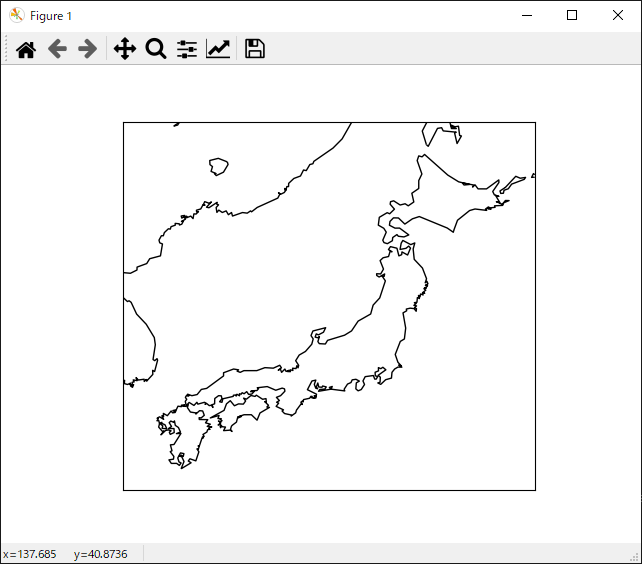
このコードを実行すると下記のように日本の白地図が表示されます。
PCをリモートで操作するためにしばらくTeamViewerを使っていましたが、商用利用検知されるようになりまともに使えなくなりました。
有料版のTeamViewerはなかなか高価なため、代替ソフトとして無料のChromeリモートデスクトップを使うようになりましたが、とても使いづらい点が。。。
それは [Alt+TAB]でアプリケーションの切り替えができないこと。
ネットで調べても『ブラウザで操作しているからリモートPC上での[Alt+TAB]切り替えができない』という意見ばかりで困っていましたが、意外と簡単に[Alt+TAB]が使えるようになりましたのでご紹介します。
まずChromeリモートデスクトップで他のPCに接続します。
接続が成功すると画面右に「セッションのオプション」を設定できるエリアが表示されます。
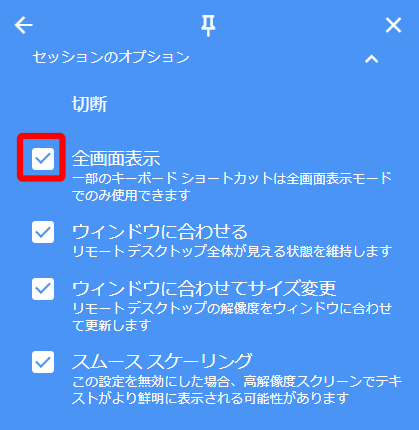
[Alt+TAB]を使うことででPCの使い勝手は各段に向上するので、とてもオススメのコンビネーションキーです。
前回に引き続きキーボードやマウス操作を行うライブラリ「pynput」をご紹介します。
前回は、単純に左クリックを連打するプログラムを作成しましたがこのままではとても使いにくいです。
今回は使い勝手をよくするために、ファンクションキー[F12]を押すと連打が有効になり、もう一度押すと連打が解除されるように実装します。
1 | from pynput.mouse import Button, Controller |
キーボードやマウス操作を行うライブラリ「pynput」をご紹介します。
「キー入力」や「マウスを動かす」「クリックする」などのほか、その操作をした時の「イベント」を処理することもできます。
次のコマンドを実行し「pynput」をインストールします。
1 | pip install pynput |
次は1秒おきに左クリックを行うソースになります。
1 | from pynput.mouse import Button, Controller |
プログラムを実行すると、連打が始まります。
コンソール上で「Enter」キーを押すと連打がとまります。
GUI操作を自動化できればPCの単純操作を任せることができるようになり大変便利です。
今回は、GUI操作を自動化するライブラリの「PyuAutoGUI」をご紹介します。
1 | pip install PyAutoGUI |
簡単に座標位置をクリックするだけのコードは次のようになります。
1 | import pyautogui |
この処理は「moveTo」と「click」を合わせて下記のように書くこともできます。
1 | pyautogui.click(100, 100) |
1 | import pyautogui |
ただ座標位置を指定する方法ですと、座標をいちいち調べないといけませんし座標が変わってしまうようなときには対応できなくなります、
このようなときには「画像マッチング機能」を使い画像を探してクリックや入力するなどの操作を行います。
1 | import pyautogui, time |
locateCenterOnScreenメソッドを使うと、画像とマッチした座標を探すことができます。
上記のコードでは、対象の画像が見つかった場合にその画像のクリックを行います。
スキャンした画像やカメラ画像などから、テキストを抽出できると大変便利です。
テキストを抽出するにはOCR処理を行う必要があります。
今回はGoogle社が提供する「tesseract-ocr」を使って画像からテキストを抽出してみます。
まず下記サイトから「tesseract-ocr-w64-setup-v5.0.0-alpha.20200223.exe」をダウンロードしてインストールします。
tesseract-ocr - https://github.com/UB-Mannheim/tesseract/wiki
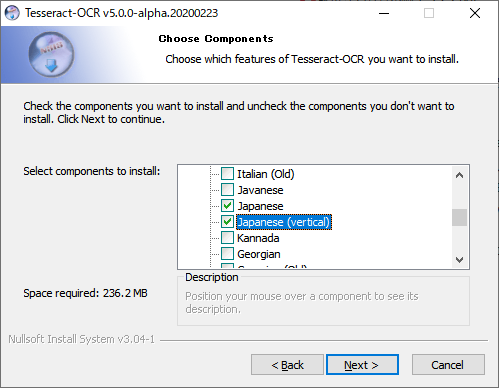
インストール中にコンポーネントを選択する画面が表示されますので
[Additional language data(download)] から、[Japanese] と [Japanese(vertical)] の2つを選択しておきます。
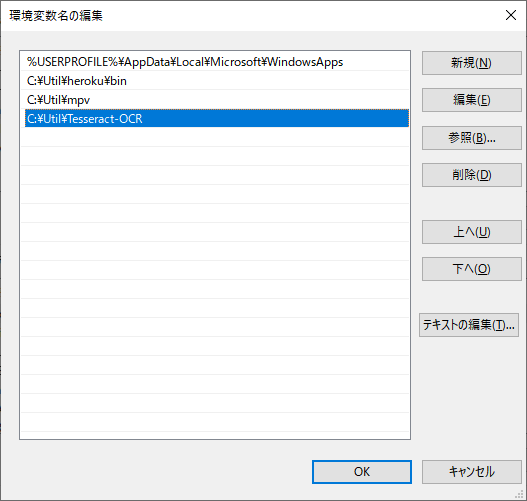
私は「C:\Util」配下へインストールしましたが、みなさんの環境に合わせて設定して下さい。
「pyocr」は「tesseract-ocr」を使うためのライブラリで、pipコマンドで次のようにインストールします。
1 | pip install pyocr |
1 | from PIL import Image |
最初に簡単だと思われる平仮名だけの画像で試してみました。

結果は「うとん」。
おしい・・・濁点が読み取れなかったようです。
次にアルファベットの画像を試してみました。

これは言語のパラメータを’jpn’から’eng’に変えて再度試したところ「SearchPreview」と正しく認識されました。
言語パラメータを合わせるのも大事なようです。
最後に漢字が含まれる2行の画像で試してみました。

「ここにファイルをドラッグ&ドロップしてください。
お使いのブラウザが対応していれば」
完璧です。
ただほかにも難しめの漢字などを試してみましたが結果はよくありませんでした。
最初に大まかにOCRでテキスト化して、最後に人が確認するというように分担すれば作業効率化を図ることは可能かと思います。参考になれば幸いです。
ブログやサムネイル作成など、画像に文字を重ねたいことがあります。
GIMPやペイントなどのグラフィックスソフトを使い、手作業で文字を入れることもできますが、コピーライトなど同じ文字を何度も入れたい場合は自動化すると便利です。
今回はPillowというライブラリを使って画像にテキストを追加する処理を自動化していきます。
1 | pip install pillow |
1 | from PIL import Image, ImageDraw, ImageFont |

正常に処理ができると次のように文字が追加された画像ファイルが出力されます。

動画を管理するときにはサムネイルがあると便利です。
サムネイルは、動画を再生してキャプチャしたり動画編集ソフトで切り出したりすることで作成できます。ただ数が多いと大変な作業となります。
PythonとOpenCVを使えば、動画からサムネイルを簡単に作ることができます。
1 | pip install opencv_python |
1 | import cv2 |
再生位置を変えて5~7行目の処理を繰り返せば、サムネイルを繰り返し作成することができます。
(ファイル名も変更する必要がありますので気を付けてください。)
上記のサンプルコードでは、再生位置を指定する場合「CAP_PROP_POS_MSEC」プロパティを使いましたが、それ以外でもよく使うプロパティを表にまとめておきます。
cap.getメソッドを使ってプロパティを指定すれば、動画の各種情報が取得できます。
| プロパティ名 | 値 | 説明 |
|---|---|---|
| CAP_PROP_POS_MSEC | 0 | 再生位置を時間で表したもの(ミリ秒単位) |
| CAP_PROP_POS_FRAMES | 1 | 再生中のフレーム番号 |
| CAP_PROP_FRAME_WIDTH | 3 | フレームの幅 |
| CAP_PROP_FRAME_HEIGHT | 4 | フレームの高さ |
| CAP_PROP_FPS | 5 | フレームレート |
| CAP_PROP_FRAME_COUNT | 7 | 全フレーム数 |
ファイルが同じかどうかを比較するにはハッシュが便利です。
ハッシュはデータの並びの特徴を表した数値です。
その値が同じであれば、データが同じである確率がとても高くなります。
下記のソースでは指定されたフォルダ(4行目)内に同じ内容のファイルがある場合、そのファイルを表示します。
今回は「SHA256」という種類のハッシュで計算しました。
1 | import os, sys, glob, hashlib |
13行目のコメントアウトを外すと重複したファイルを消すことができます。