スキャンした画像やカメラ画像などから、テキストを抽出できると大変便利です。
テキストを抽出するにはOCR処理を行う必要があります。
今回はGoogle社が提供する「tesseract-ocr」を使って画像からテキストを抽出してみます。
インストール
まず下記サイトから「tesseract-ocr-w64-setup-v5.0.0-alpha.20200223.exe」をダウンロードしてインストールします。
tesseract-ocr - https://github.com/UB-Mannheim/tesseract/wiki
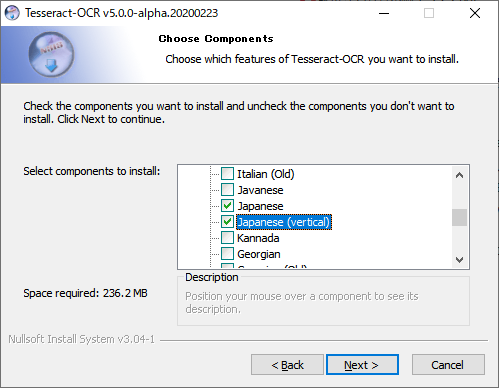
インストール中にコンポーネントを選択する画面が表示されますので
[Additional language data(download)] から、[Japanese] と [Japanese(vertical)] の2つを選択しておきます。
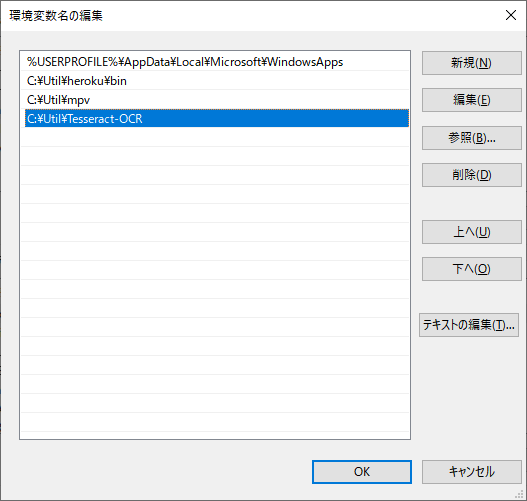
次に「tesseract-ocr」をインストールしたフォルダ・パスを、環境変数 path に追加します。
私は「C:\Util」配下へインストールしましたが、みなさんの環境に合わせて設定して下さい。
最後に、pyocrをコンソールからインストールします。
「pyocr」は「tesseract-ocr」を使うためのライブラリで、pipコマンドで次のようにインストールします。
1 | pip install pyocr |
コーディング
Pythonで下記のようにコーディングし、実行します。1 | from PIL import Image |
検証1
最初に簡単だと思われる平仮名だけの画像で試してみました。

結果は「うとん」。
おしい・・・濁点が読み取れなかったようです。
検証2
次にアルファベットの画像を試してみました。

結果は「SearchPrevlew」・・・・一瞬正解のように思えましたが 'i' のところを 'l' と誤って認識しています。
これは言語のパラメータを’jpn’から’eng’に変えて再度試したところ「SearchPreview」と正しく認識されました。
言語パラメータを合わせるのも大事なようです。
検証3
最後に漢字が含まれる2行の画像で試してみました。

結果は・・・
「ここにファイルをドラッグ&ドロップしてください。
お使いのブラウザが対応していれば」
完璧です。
ただほかにも難しめの漢字などを試してみましたが結果はよくありませんでした。
最初に大まかにOCRでテキスト化して、最後に人が確認するというように分担すれば作業効率化を図ることは可能かと思います。参考になれば幸いです。