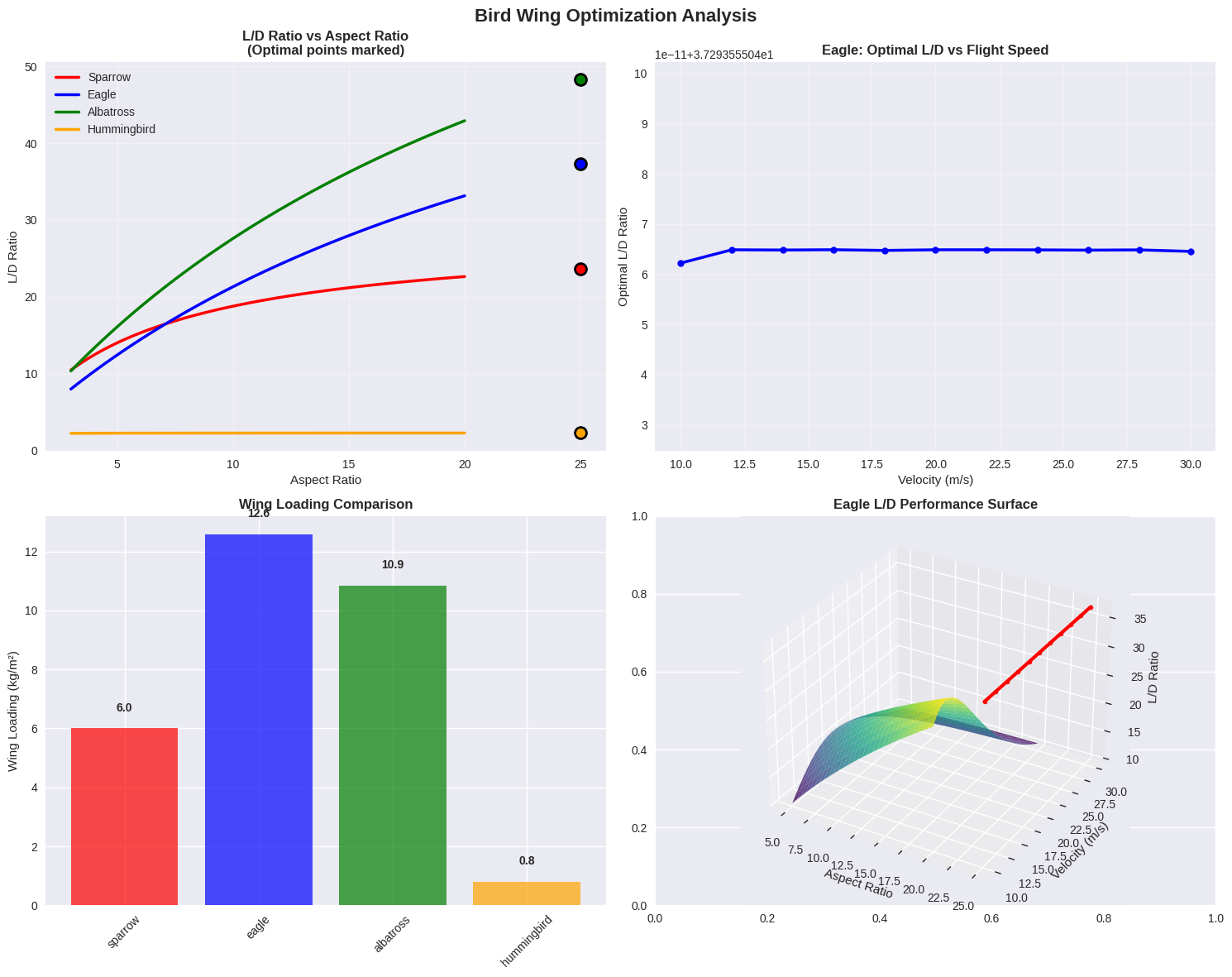
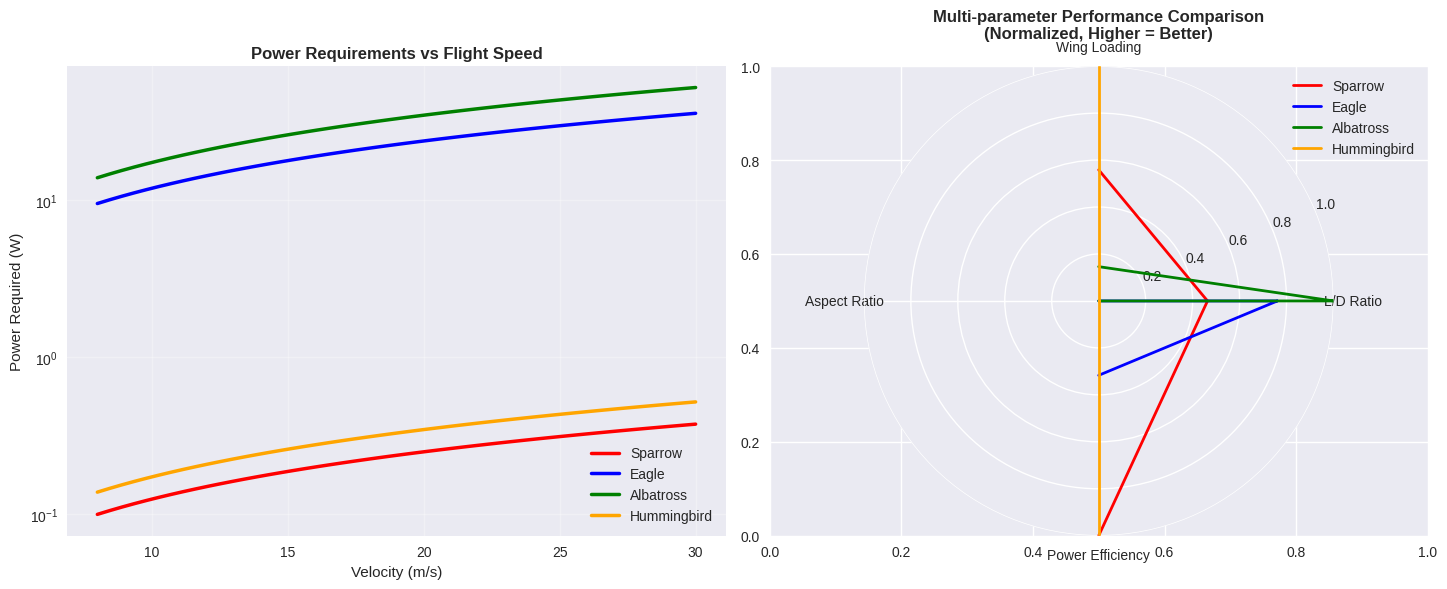
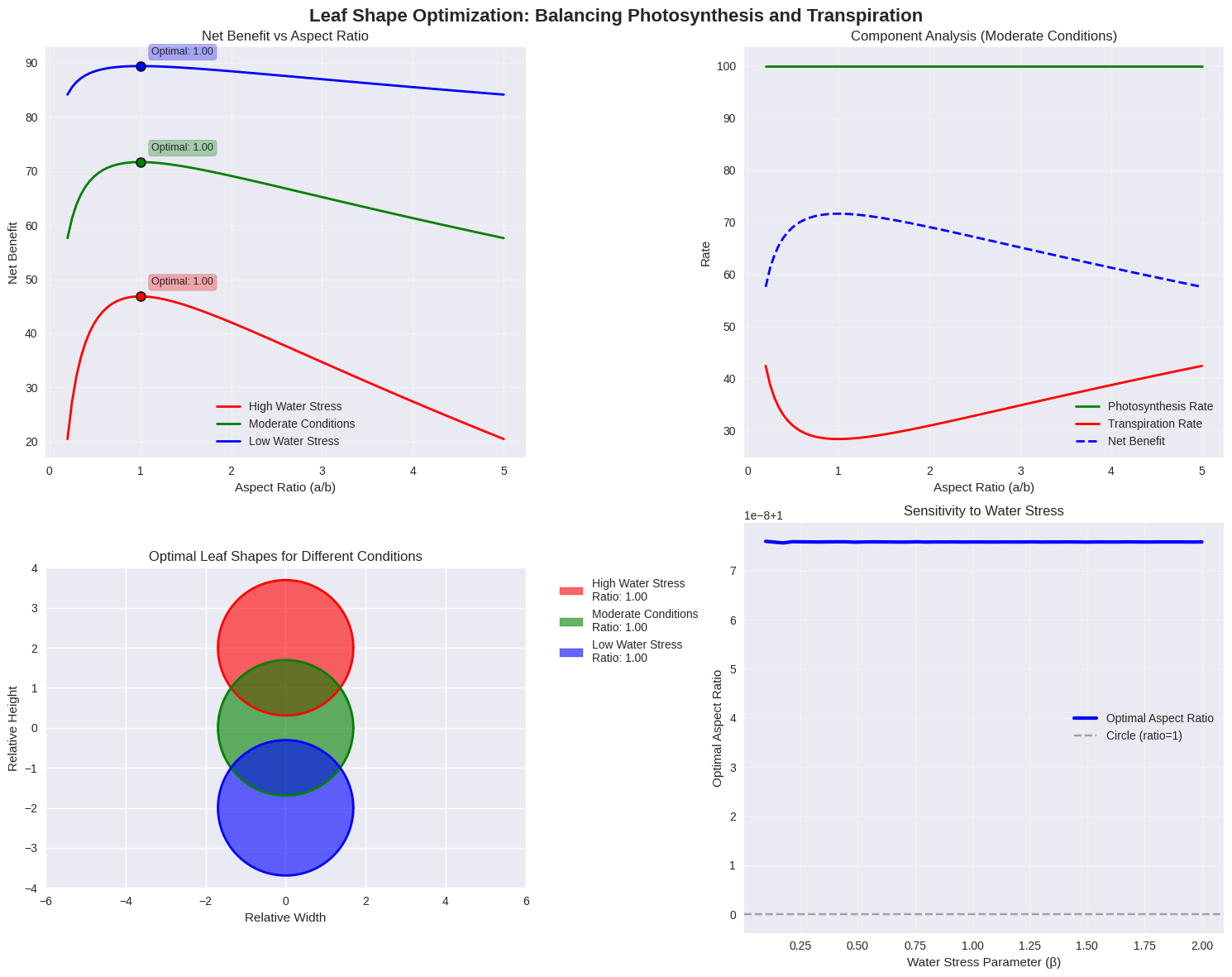
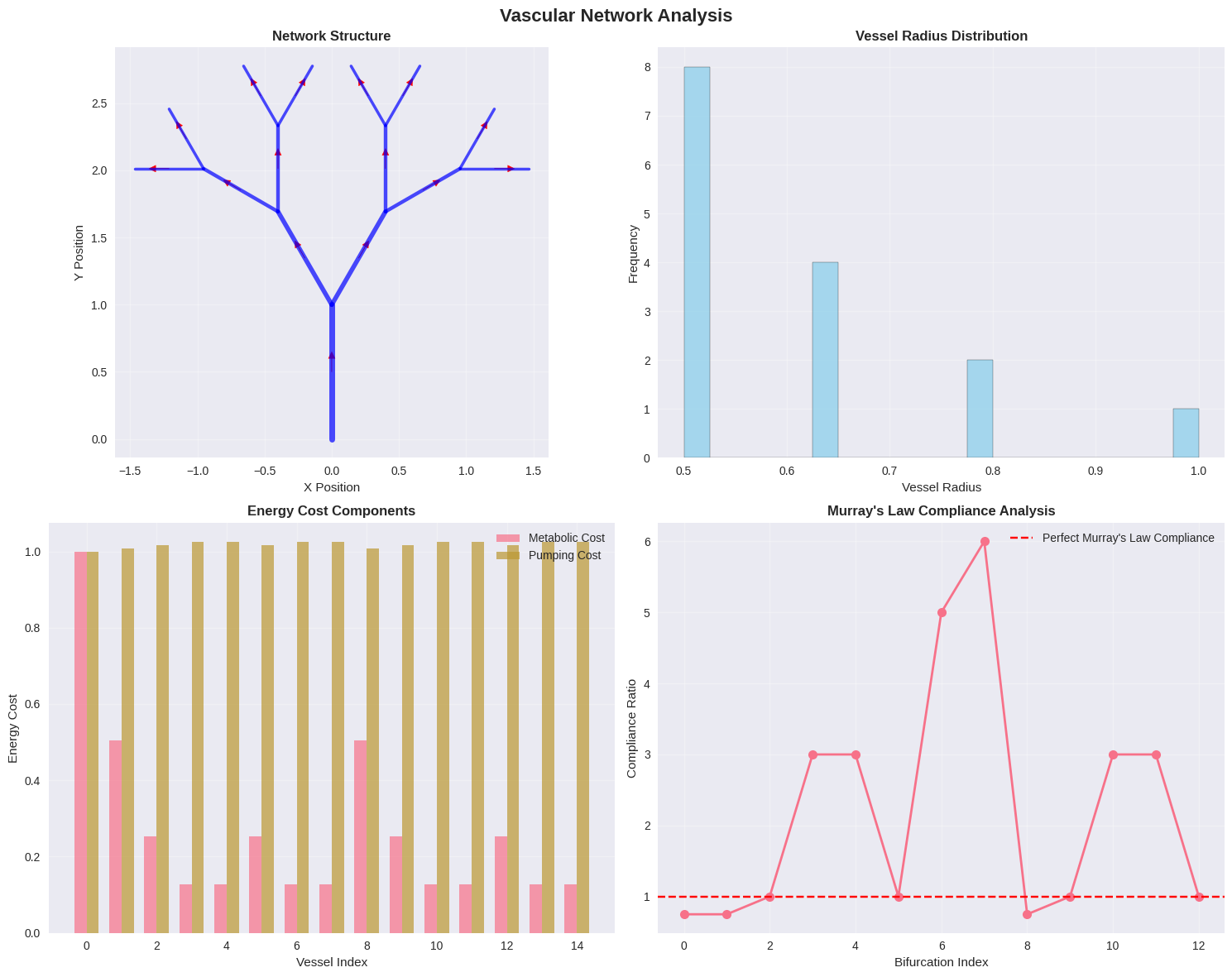
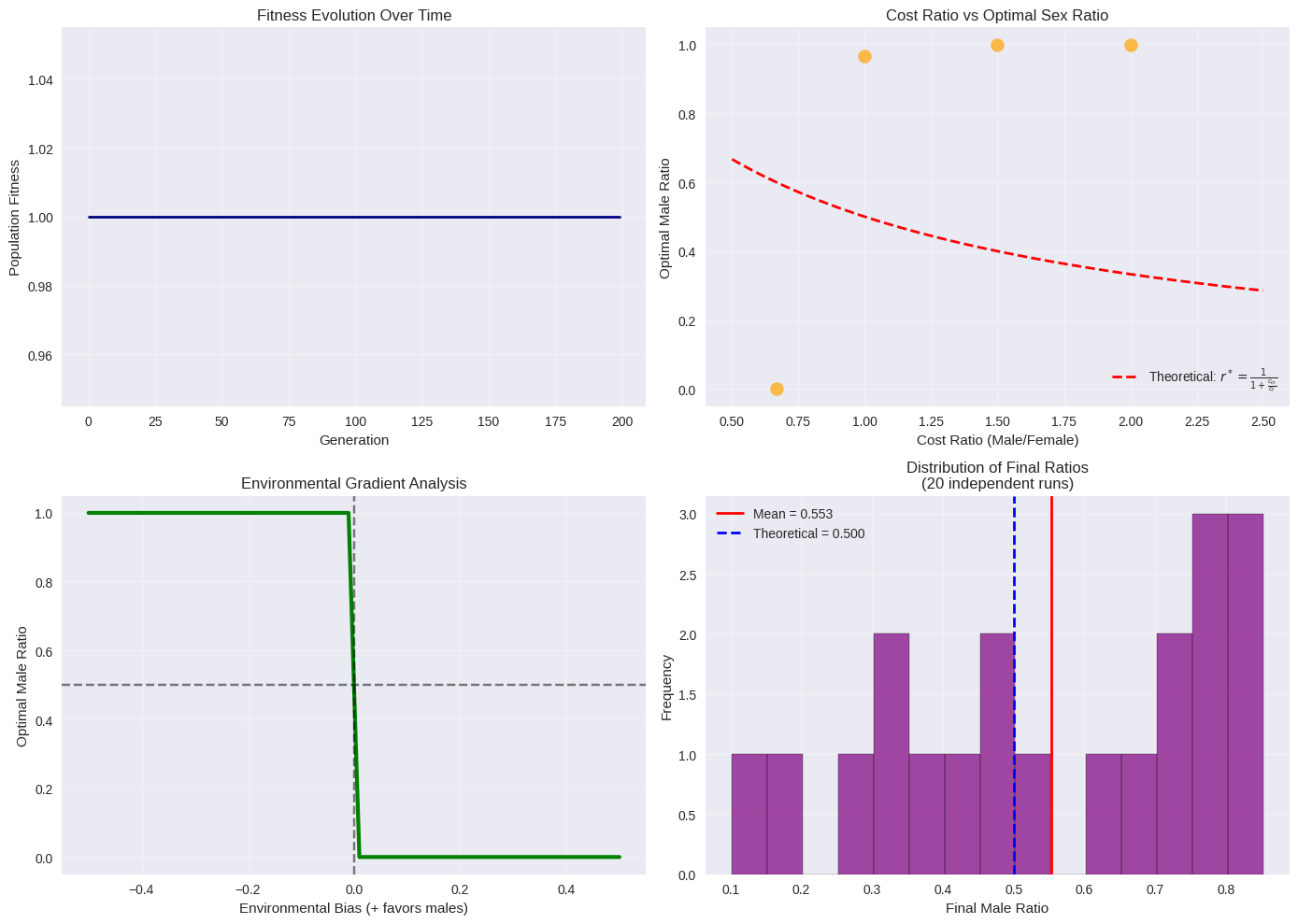
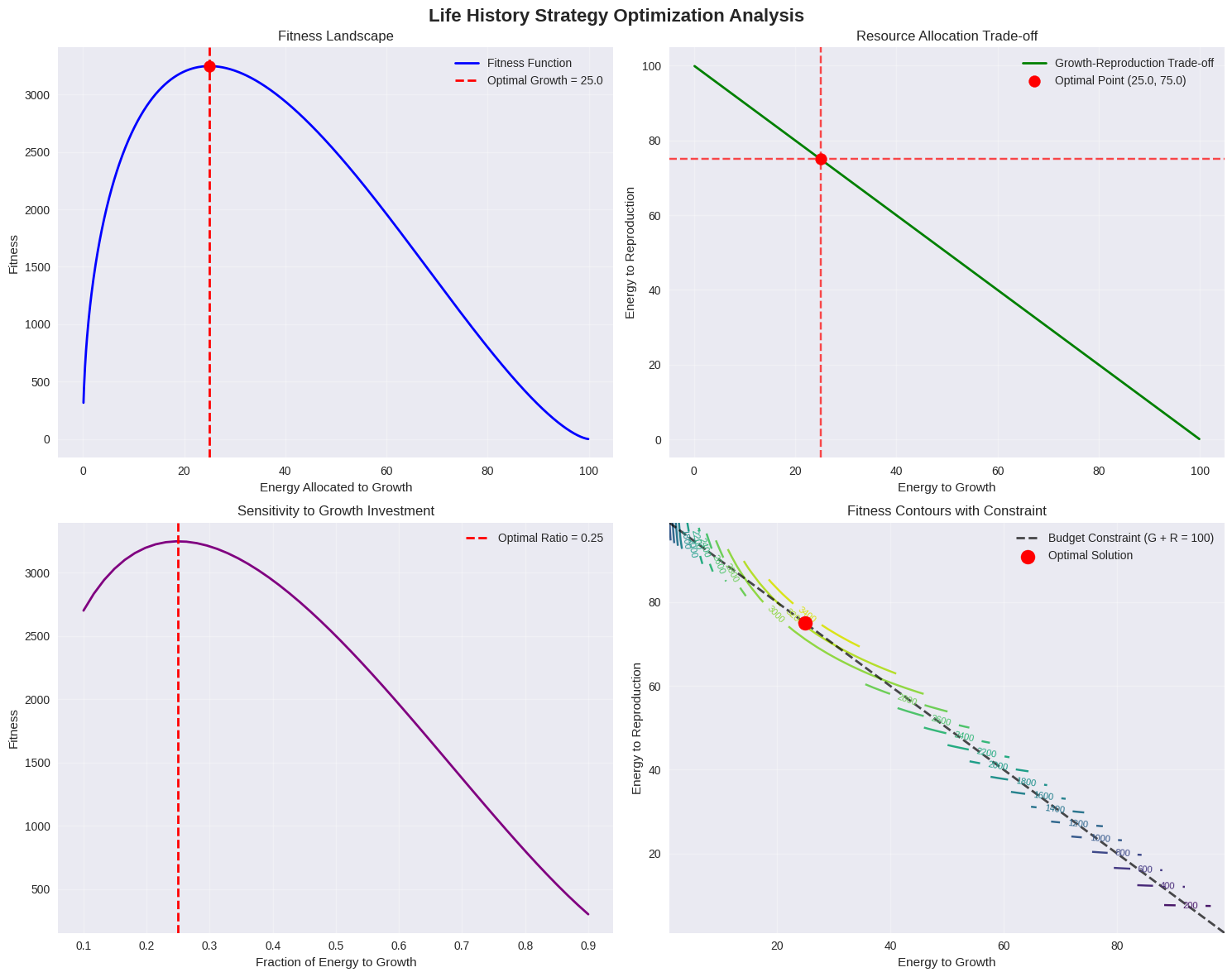
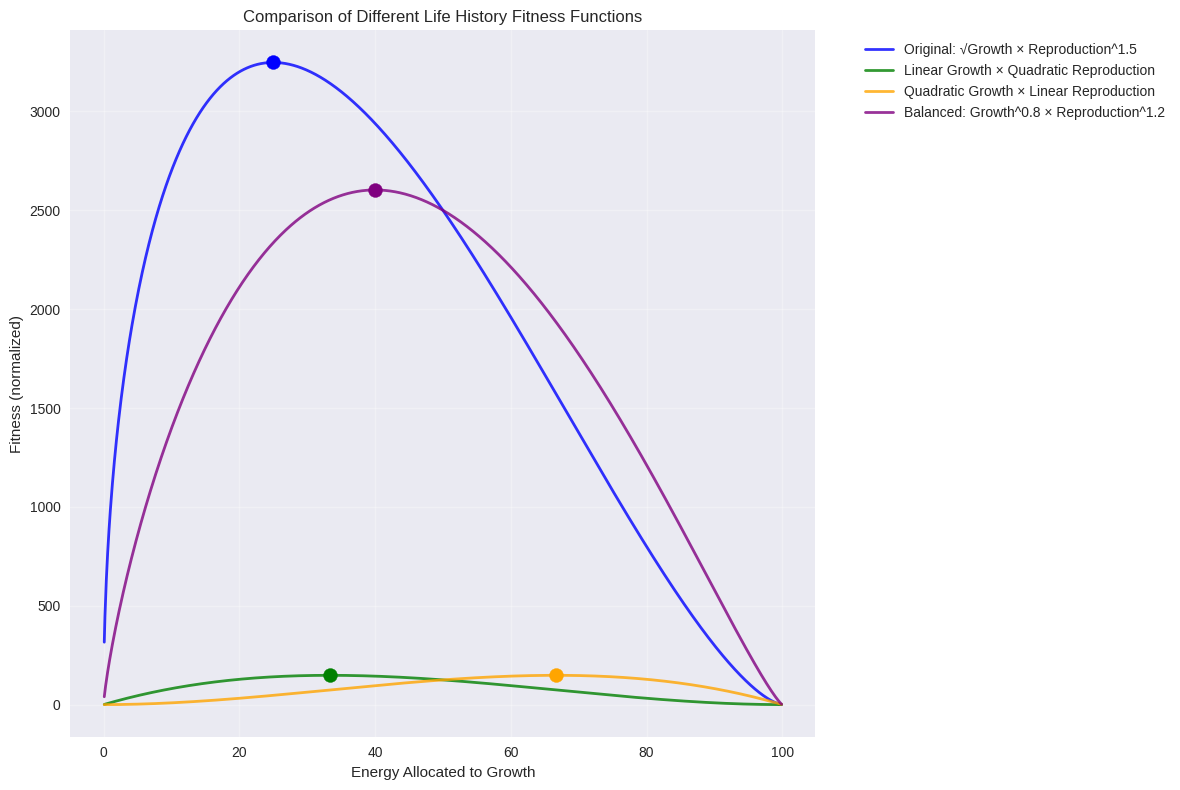
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
| import numpy as np
import matplotlib.pyplot as plt
from scipy import sparse
from scipy.sparse.linalg import spsolve
import seaborn as sns
class BoneStructureOptimizer:
"""
A class to optimize bone structure using topology optimization principles.
This simulates the internal structure of a bone cross-section under loading.
"""
def __init__(self, nelx=60, nely=40, volfrac=0.4, penal=3, rmin=1.5):
"""
Initialize the optimizer parameters.
Parameters:
nelx, nely: Number of elements in x and y directions
volfrac: Volume fraction (amount of material to use)
penal: Penalization power for intermediate densities
rmin: Filter radius for mesh-independency
"""
self.nelx = nelx
self.nely = nely
self.volfrac = volfrac
self.penal = penal
self.rmin = rmin
self.E0 = 17e9
self.Emin = 1e-9
self.nu = 0.3
def lk(self):
"""
Element stiffness matrix for 4-node quadrilateral element.
This represents the mechanical properties of a small bone element.
"""
E = 1.0
nu = self.nu
k = np.array([
1/2-nu/6, 1/8+nu/8, -1/4-nu/12, -1/8+3*nu/8,
-1/4+nu/12, -1/8-nu/8, nu/6, 1/8-3*nu/8
])
KE = E/(1-nu**2) * np.array([
[k[0], k[1], k[2], k[3], k[4], k[5], k[6], k[7]],
[k[1], k[0], k[7], k[6], k[5], k[4], k[3], k[2]],
[k[2], k[7], k[0], k[5], k[6], k[3], k[4], k[1]],
[k[3], k[6], k[5], k[0], k[7], k[2], k[1], k[4]],
[k[4], k[5], k[6], k[7], k[0], k[1], k[2], k[3]],
[k[5], k[4], k[3], k[2], k[1], k[0], k[7], k[6]],
[k[6], k[3], k[4], k[1], k[2], k[7], k[0], k[5]],
[k[7], k[2], k[1], k[4], k[3], k[6], k[5], k[0]]
])
return KE
def create_loads_and_supports(self):
"""
Define loading and boundary conditions similar to a loaded bone.
Simulates compression loading on top with fixed support at bottom.
"""
ndof = 2 * (self.nelx + 1) * (self.nely + 1)
F = np.zeros((ndof, 1))
load_magnitude = 1000
for i in range(self.nelx + 1):
node = i * (self.nely + 1) + self.nely
F[2 * node + 1] = -load_magnitude / (self.nelx + 1)
fixeddofs = []
for i in range(self.nelx + 1):
node = i * (self.nely + 1)
fixeddofs.extend([2 * node, 2 * node + 1])
alldofs = list(range(ndof))
freedofs = list(set(alldofs) - set(fixeddofs))
return F, freedofs, fixeddofs
def filter_sensitivity(self, x, dc):
"""
Apply sensitivity filter to ensure mesh-independent solutions.
This prevents checkerboard patterns in the optimized structure.
"""
dcf = np.zeros((self.nely, self.nelx))
for i in range(self.nelx):
for j in range(self.nely):
sum_fac = 0.0
for k in range(max(i - int(self.rmin), 0),
min(i + int(self.rmin) + 1, self.nelx)):
for l in range(max(j - int(self.rmin), 0),
min(j + int(self.rmin) + 1, self.nely)):
fac = self.rmin - np.sqrt((i - k)**2 + (j - l)**2)
sum_fac += max(0, fac)
dcf[j, i] += max(0, fac) * x[l, k] * dc[l, k]
dcf[j, i] = dcf[j, i] / (x[j, i] * sum_fac)
return dcf
def optimize(self, max_iterations=100):
"""
Main optimization loop using the Method of Moving Asymptotes (MMA) approach.
This mimics how bone adapts its structure based on mechanical loading.
"""
print("Starting bone structure optimization...")
print(f"Domain size: {self.nelx} x {self.nely} elements")
print(f"Target volume fraction: {self.volfrac}")
print(f"Material properties: E = {self.E0/1e9:.1f} GPa, ν = {self.nu}")
print("-" * 50)
x = self.volfrac * np.ones((self.nely, self.nelx))
xold = x.copy()
KE = self.lk()
F, freedofs, fixeddofs = self.create_loads_and_supports()
history = {'compliance': [], 'volume': [], 'change': []}
for iteration in range(max_iterations):
K, U, compliance = self.fe_analysis(x, KE, F, freedofs)
dc = self.sensitivity_analysis(x, KE, U)
dc = self.filter_sensitivity(x, dc)
x = self.update_design_variables(x, dc)
volume = np.sum(x) / (self.nelx * self.nely)
change = np.max(np.abs(x - xold))
history['compliance'].append(compliance)
history['volume'].append(volume)
history['change'].append(change)
if iteration % 10 == 0:
print(f"Iteration {iteration:3d}: Compliance = {compliance:.3e}, "
f"Volume = {volume:.3f}, Change = {change:.3f}")
if change < 0.01:
print(f"\nConverged after {iteration + 1} iterations!")
break
xold = x.copy()
print(f"Final compliance: {compliance:.3e}")
print(f"Final volume fraction: {volume:.3f}")
return x, history, U
def fe_analysis(self, x, KE, F, freedofs):
"""
Finite element analysis to compute displacements and compliance.
This solves the equilibrium equation: K*U = F
"""
ndof = 2 * (self.nelx + 1) * (self.nely + 1)
K = sparse.lil_matrix((ndof, ndof))
U = np.zeros((ndof, 1))
for elx in range(self.nelx):
for ely in range(self.nely):
n1 = (self.nely + 1) * elx + ely
n2 = (self.nely + 1) * (elx + 1) + ely
edof = np.array([2*n1, 2*n1+1, 2*n2, 2*n2+1,
2*n2+2, 2*n2+3, 2*n1+2, 2*n1+3])
density = x[ely, elx]
Ke = (self.Emin + density**self.penal * (self.E0 - self.Emin)) / self.E0 * KE
for i in range(8):
for j in range(8):
K[edof[i], edof[j]] += Ke[i, j]
K = K.tocsr()
U[freedofs] = spsolve(K[freedofs, :][:, freedofs], F[freedofs]).reshape(-1, 1)
compliance = float(F.T @ U)
return K, U, compliance
def sensitivity_analysis(self, x, KE, U):
"""
Compute sensitivity of compliance with respect to design variables.
This tells us how changing the density affects the structural performance.
"""
dc = np.zeros((self.nely, self.nelx))
for elx in range(self.nelx):
for ely in range(self.nely):
n1 = (self.nely + 1) * elx + ely
n2 = (self.nely + 1) * (elx + 1) + ely
edof = np.array([2*n1, 2*n1+1, 2*n2, 2*n2+1,
2*n2+2, 2*n2+3, 2*n1+2, 2*n1+3])
Ue = U[edof]
dc[ely, elx] = -self.penal * x[ely, elx]**(self.penal-1) * \
(self.E0 - self.Emin) / self.E0 * Ue.T @ KE @ Ue
return dc
def update_design_variables(self, x, dc):
"""
Update design variables using optimality criteria method.
This is inspired by how bone remodeling responds to mechanical stimulus.
"""
l1, l2 = 0, 100000
move = 0.2
while (l2 - l1) / (l1 + l2) > 1e-3:
lmid = 0.5 * (l2 + l1)
xnew = np.maximum(0.001, np.maximum(x - move,
np.minimum(1.0, np.minimum(x + move,
x * np.sqrt(-dc / lmid)))))
if np.sum(xnew) > self.volfrac * self.nelx * self.nely:
l1 = lmid
else:
l2 = lmid
return xnew
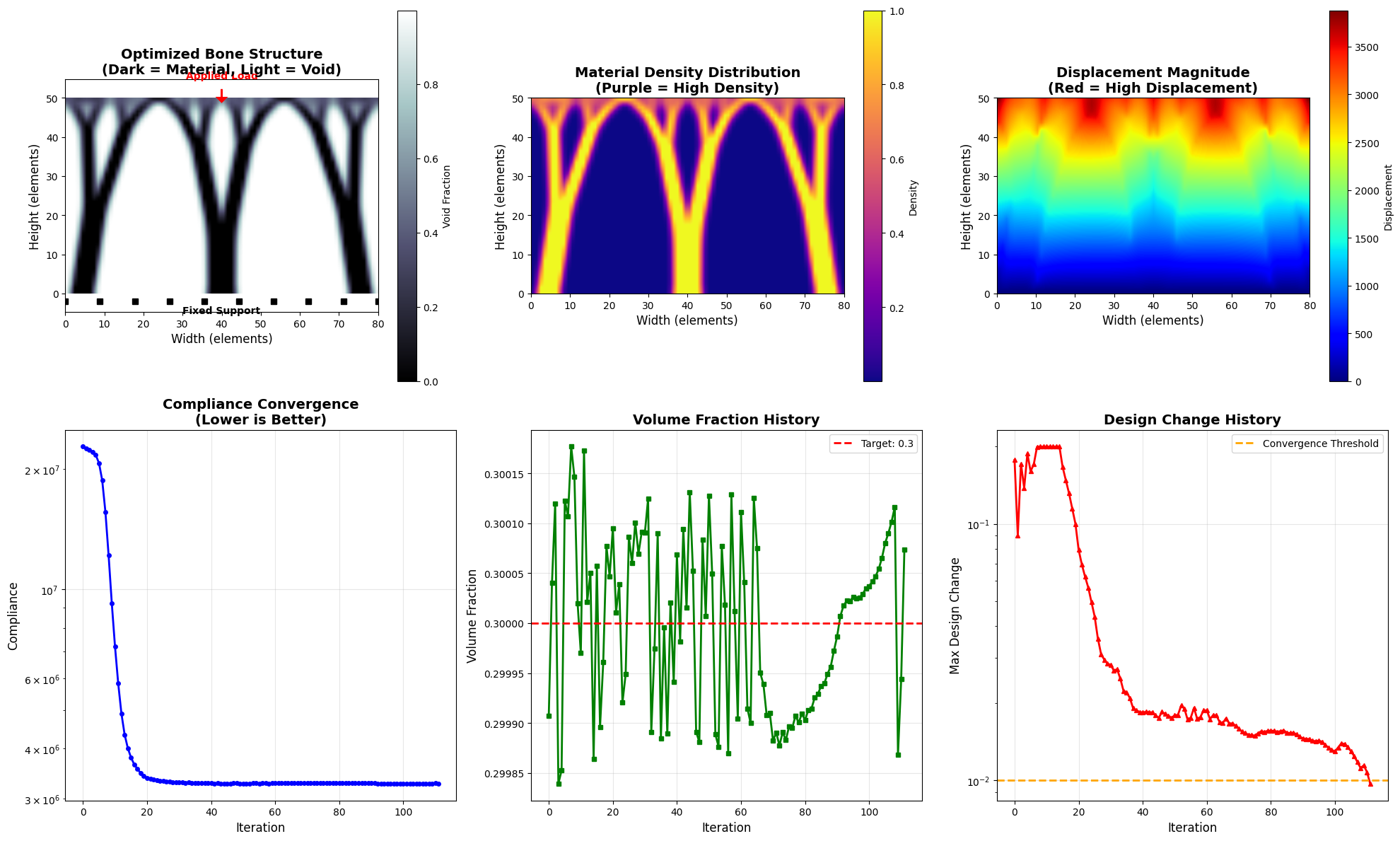
def visualize_results(self, x, history, U, save_plots=True):
"""
Create comprehensive visualizations of the optimization results.
"""
plt.style.use('default')
sns.set_palette("viridis")
fig = plt.figure(figsize=(20, 12))
ax1 = plt.subplot(2, 3, 1)
im1 = ax1.imshow(1 - x, cmap='bone', interpolation='bilinear',
origin='lower', extent=[0, self.nelx, 0, self.nely])
ax1.set_title('Optimized Bone Structure\n(Dark = Material, Light = Void)',
fontsize=14, fontweight='bold')
ax1.set_xlabel('Width (elements)', fontsize=12)
ax1.set_ylabel('Height (elements)', fontsize=12)
plt.colorbar(im1, ax=ax1, label='Void Fraction')
ax1.arrow(self.nelx/2, self.nely+2, 0, -2, head_width=2,
head_length=1, fc='red', ec='red', linewidth=2)
ax1.text(self.nelx/2, self.nely+5, 'Applied Load', ha='center',
fontsize=10, color='red', fontweight='bold')
support_x = np.linspace(0, self.nelx, 10)
support_y = np.ones_like(support_x) * (-2)
ax1.plot(support_x, support_y, 'ks', markersize=6)
ax1.text(self.nelx/2, -5, 'Fixed Support', ha='center',
fontsize=10, color='black', fontweight='bold')
ax2 = plt.subplot(2, 3, 2)
im2 = ax2.imshow(x, cmap='plasma', interpolation='bilinear',
origin='lower', extent=[0, self.nelx, 0, self.nely])
ax2.set_title('Material Density Distribution\n(Purple = High Density)',
fontsize=14, fontweight='bold')
ax2.set_xlabel('Width (elements)', fontsize=12)
ax2.set_ylabel('Height (elements)', fontsize=12)
plt.colorbar(im2, ax=ax2, label='Density')
ax3 = plt.subplot(2, 3, 3)
U_reshaped = np.zeros((self.nely + 1, self.nelx + 1))
for i in range(self.nelx + 1):
for j in range(self.nely + 1):
node = i * (self.nely + 1) + j
disp_mag = np.sqrt(U[2*node]**2 + U[2*node+1]**2)
U_reshaped[j, i] = disp_mag
im3 = ax3.imshow(U_reshaped, cmap='jet', interpolation='bilinear',
origin='lower', extent=[0, self.nelx, 0, self.nely])
ax3.set_title('Displacement Magnitude\n(Red = High Displacement)',
fontsize=14, fontweight='bold')
ax3.set_xlabel('Width (elements)', fontsize=12)
ax3.set_ylabel('Height (elements)', fontsize=12)
plt.colorbar(im3, ax=ax3, label='Displacement')
ax4 = plt.subplot(2, 3, 4)
iterations = range(len(history['compliance']))
ax4.plot(iterations, history['compliance'], 'b-', linewidth=2, marker='o', markersize=4)
ax4.set_title('Compliance Convergence\n(Lower is Better)', fontsize=14, fontweight='bold')
ax4.set_xlabel('Iteration', fontsize=12)
ax4.set_ylabel('Compliance', fontsize=12)
ax4.grid(True, alpha=0.3)
ax4.set_yscale('log')
ax5 = plt.subplot(2, 3, 5)
ax5.plot(iterations, history['volume'], 'g-', linewidth=2, marker='s', markersize=4)
ax5.axhline(y=self.volfrac, color='r', linestyle='--', linewidth=2,
label=f'Target: {self.volfrac}')
ax5.set_title('Volume Fraction History', fontsize=14, fontweight='bold')
ax5.set_xlabel('Iteration', fontsize=12)
ax5.set_ylabel('Volume Fraction', fontsize=12)
ax5.grid(True, alpha=0.3)
ax5.legend()
ax6 = plt.subplot(2, 3, 6)
ax6.semilogy(iterations, history['change'], 'r-', linewidth=2, marker='^', markersize=4)
ax6.axhline(y=0.01, color='orange', linestyle='--', linewidth=2,
label='Convergence Threshold')
ax6.set_title('Design Change History', fontsize=14, fontweight='bold')
ax6.set_xlabel('Iteration', fontsize=12)
ax6.set_ylabel('Max Design Change', fontsize=12)
ax6.grid(True, alpha=0.3)
ax6.legend()
plt.tight_layout()
plt.show()
self.plot_cross_sections(x)
self.plot_performance_metrics(history)
return fig
def plot_cross_sections(self, x):
"""
Plot cross-sectional views of the optimized structure.
"""
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
mid_y = self.nely // 2
horizontal_section = x[mid_y, :]
ax1.plot(range(self.nelx), horizontal_section, 'b-', linewidth=3, marker='o')
ax1.set_title(f'Horizontal Cross-Section (y = {mid_y})', fontsize=14, fontweight='bold')
ax1.set_xlabel('X Position (elements)', fontsize=12)
ax1.set_ylabel('Material Density', fontsize=12)
ax1.grid(True, alpha=0.3)
ax1.set_ylim(0, 1)
mid_x = self.nelx // 2
vertical_section = x[:, mid_x]
ax2.plot(vertical_section, range(self.nely), 'r-', linewidth=3, marker='s')
ax2.set_title(f'Vertical Cross-Section (x = {mid_x})', fontsize=14, fontweight='bold')
ax2.set_xlabel('Material Density', fontsize=12)
ax2.set_ylabel('Y Position (elements)', fontsize=12)
ax2.grid(True, alpha=0.3)
ax2.set_xlim(0, 1)
plt.tight_layout()
plt.show()
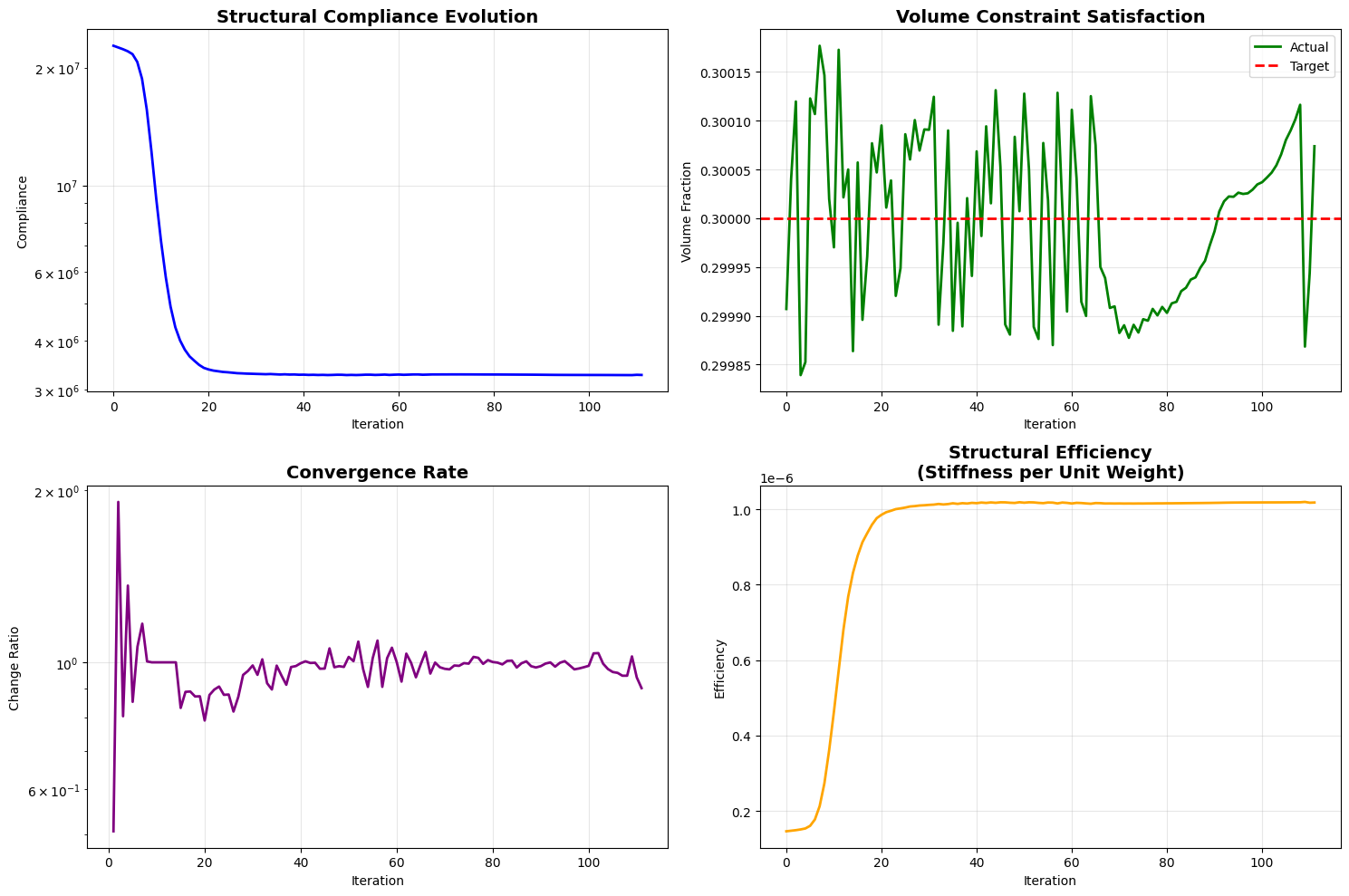
def plot_performance_metrics(self, history):
"""
Plot detailed performance metrics.
"""
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(15, 10))
iterations = range(len(history['compliance']))
ax1.plot(iterations, history['compliance'], 'b-', linewidth=2)
ax1.set_title('Structural Compliance Evolution', fontsize=14, fontweight='bold')
ax1.set_xlabel('Iteration')
ax1.set_ylabel('Compliance')
ax1.grid(True, alpha=0.3)
ax1.set_yscale('log')
ax2.plot(iterations, history['volume'], 'g-', linewidth=2, label='Actual')
ax2.axhline(y=self.volfrac, color='r', linestyle='--', linewidth=2, label='Target')
ax2.set_title('Volume Constraint Satisfaction', fontsize=14, fontweight='bold')
ax2.set_xlabel('Iteration')
ax2.set_ylabel('Volume Fraction')
ax2.grid(True, alpha=0.3)
ax2.legend()
if len(history['change']) > 1:
convergence_rate = np.array(history['change'][1:]) / np.array(history['change'][:-1])
ax3.semilogy(range(1, len(convergence_rate)+1), convergence_rate, 'purple', linewidth=2)
ax3.set_title('Convergence Rate', fontsize=14, fontweight='bold')
ax3.set_xlabel('Iteration')
ax3.set_ylabel('Change Ratio')
ax3.grid(True, alpha=0.3)
efficiency = 1.0 / (np.array(history['compliance']) * np.array(history['volume']))
ax4.plot(iterations, efficiency, 'orange', linewidth=2)
ax4.set_title('Structural Efficiency\n(Stiffness per Unit Weight)', fontsize=14, fontweight='bold')
ax4.set_xlabel('Iteration')
ax4.set_ylabel('Efficiency')
ax4.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print("=" * 60)
print("BONE STRUCTURE OPTIMIZATION SIMULATION")
print("=" * 60)
optimizer = BoneStructureOptimizer(nelx=80, nely=50, volfrac=0.3, penal=3, rmin=2.0)
optimal_structure, history, displacements = optimizer.optimize(max_iterations=150)
print("\n" + "=" * 60)
print("OPTIMIZATION COMPLETE - GENERATING VISUALIZATIONS")
print("=" * 60)
fig = optimizer.visualize_results(optimal_structure, history, displacements)
print("\n" + "=" * 60)
print("FINAL ANALYSIS SUMMARY")
print("=" * 60)
print(f"Material usage: {np.sum(optimal_structure)/(optimizer.nelx*optimizer.nely)*100:.1f}%")
print(f"Weight reduction: {(1-optimizer.volfrac)*100:.1f}% compared to solid structure")
print(f"Final compliance: {history['compliance'][-1]:.3e}")
print(f"Optimization converged in {len(history['compliance'])} iterations")
print("\nThis structure demonstrates how bones achieve maximum strength")
print("with minimum weight through optimized internal architecture!")
|