1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
| import dash
import dash_bio as dashbio
import dash_html_components as html
app = dash.Dash(__name__)
app.layout = html.Div(
[
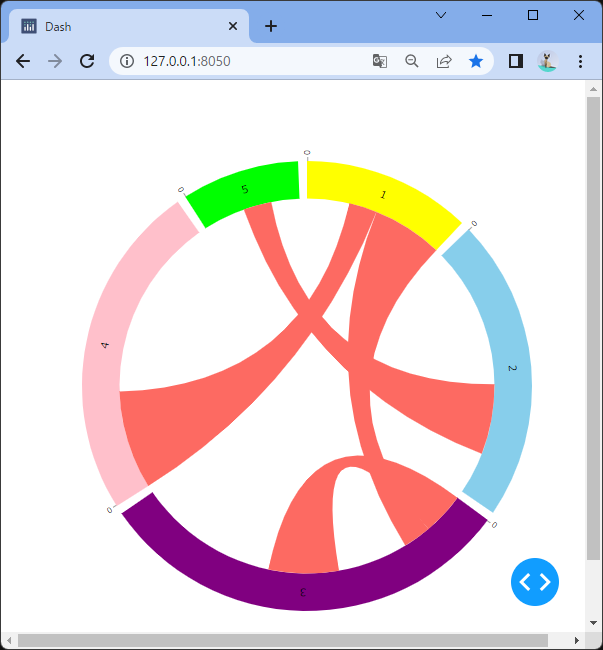
dashbio.Circos(
layout=[
{'id':'1', 'label':'1', 'color':'yellow', 'len':100},
{'id':'2', 'label':'2', 'color':'skyblue','len':180},
{'id':'3', 'label':'3', 'color':'purple', 'len':250},
{'id':'4', 'label':'4', 'color':'pink', 'len':200},
{'id':'5', 'label':'5', 'color':'lime', 'len': 70}
],
tracks=[
{
'type': 'CHORDS',
'data':[
{
'source':{'id':'1', 'start':50, 'end':100},
'target':{'id':'3', 'start':30, 'end':50},
},
{
'source':{'id':'1', 'start':30, 'end':50},
'target':{'id':'4', 'start': 0, 'end':70},
},
{
'source':{'id':'2', 'start':100, 'end':150},
'target':{'id':'5', 'start': 30, 'end': 50},
},
{
'source':{'id':'3', 'start':100, 'end':150},
'target':{'id':'3', 'start': 0, 'end': 30},
}
],
'opacity':0.8,
'color':{'name':'color'},
'config':{
'tooltipContent':{
'source':'source',
'sourceID':'id',
'target':'target',
'targetID':'id',
'targetEnd':'end'
}
}
}
]
)
]
)
if __name__ == '__main__':
app.run_server(debug=True)
|