前回試したホールドアウト法は、簡単にモデルの性能評価ができるので使いやすいのですがvalidセットを学習に使えていないという欠点があります。
精度が必要な場合には、この問題を解決したk分割交差検証を使うのが一般的です。
データの読み込みと前処理
前回と同様に、タイタニックのデータセットを読み込み、前処理(不要列の削除・欠損値処理・カテゴリ変数の変換)を行っておきます。
[ソース]
1 | import pandas as pd |
[出力結果]
分割交差検証
k分割交差検証のk=3の場合の3分割交差検証を行います。
fold1、fold2、fold3の合計3回の学習・検証を行います。
3分割したデータはtrainセット(訓練用)に2回、validセット(検証用)に1回ずつ使われます。
学習を3回行うので学習済みモデルも3つできます。3つの予測結果ができますので、最後にそれらを1つにまとめています。
[ソース]
1 | import lightgbm as lgb |
[出力結果]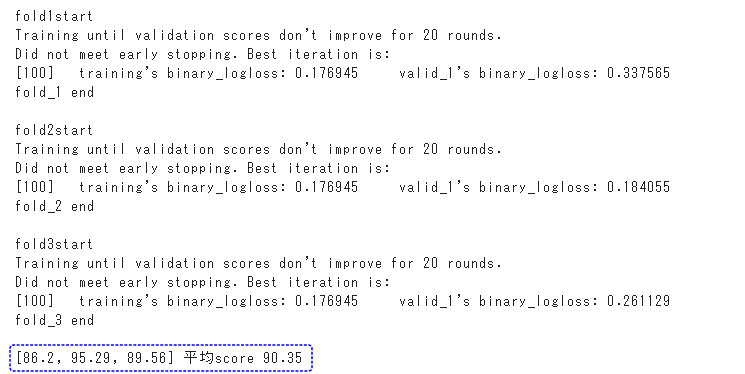
正解率は90.35%となりました。
なかなかの好成績になったのではないでしょうか。
(実行環境としてGoogleさんのColaboratoryを使用ています。)