LightGBMというアルゴリズムを使って、タイタニックの生存予測を行います。
LightGBMは、マイクロソフトが開発したアルゴリズムで次のような特徴があります。
- 決定木ベースの勾配ブースティングを行う
- 精度が高い
- 非常に高速
- 欠損値の補完が不要
- 特徴のスケーリング(例えば最小値0、最大値1に正規化すること)が不要
前処理
前処理(Preprocessing)では、与えられたデータセットに対してアルゴリズムを用いて予測ができる形式に変換するまでの処理を行います。
具体的には、下記の処理があげられます。
- 欠損値の対応
- 外れ値の検出・処理
- ダミー変数の作成
- 連続データの離散化
- 特徴量選択
前処理の仕方によって、予測結果が大きく変わってきますのでとても重要であり、多くの時間を費やす作業となります。
今回は、タイタニックのデータセットに対して、不要列の削除・欠損値処理・カテゴリ変数の変換を行います。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import pandas as pd
import seaborn as sns
titanic = sns.load_dataset('titanic')
# 不要な列の削除
titanic.drop(['class', 'who', 'adult_male', 'deck', 'embark_town', 'alive', 'alone'], axis=1, inplace=True)
# 欠損値処理
#titanic.isnull().sum()
titanic['age'] = titanic['age'].fillna(titanic['age'].median())
titanic['embarked'] = titanic['embarked'].fillna('S')
# カテゴリ変数の変換
titanic = pd.get_dummies(titanic, columns=['sex', 'embarked'])
x_titanic = titanic.drop(['survived'], axis=1)
y_titanic = titanic['survived']
x_titanic
|
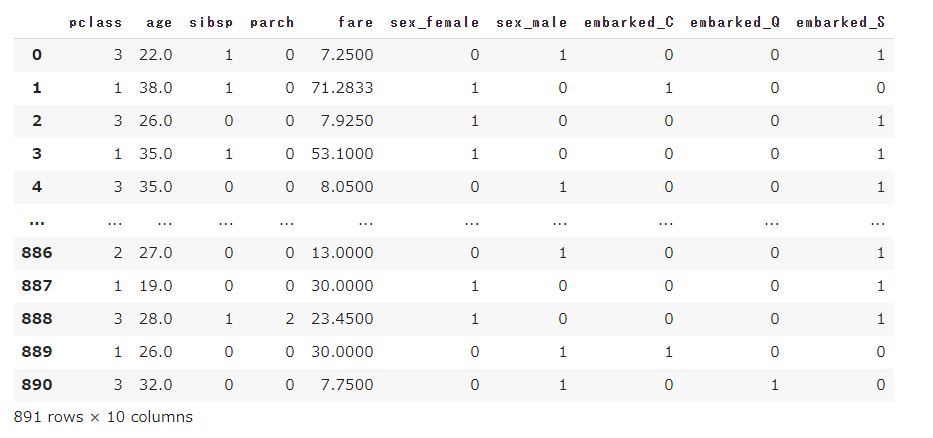
ホールドアウト法での学習
scikit-learnのtrain_test_split関数を用いて、データセットを67%対33%の割合でtrainセット(訓練用)とvalidセット(検証用)に分割し学習を行います。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# x_titanicとy_titanicをtraintとvalidに分割
train_x, valid_x, train_y, valid_y = train_test_split(x_titanic, y_titanic, test_size=0.33, random_state=0)
# lgb.Datasetでtrainとvalidを作っておく
lgb_train = lgb.Dataset(train_x, train_y)
lgb_eval = lgb.Dataset(valid_x, valid_y)
# パラメータを定義
lgbm_params = {'objective': 'binary'}
# lgb.trainで学習
evals_result = {}
gbm = lgb.train(params=lgbm_params,
train_set=lgb_train,
valid_sets=[lgb_train, lgb_eval],
early_stopping_rounds=20,
evals_result=evals_result,
verbose_eval=10)
|
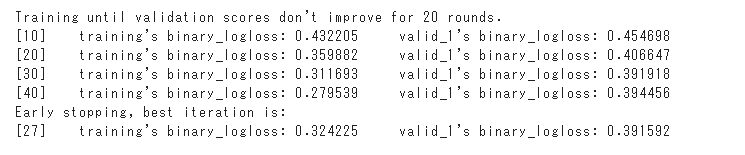
27roundでlossが最低となり、学習が終了しています。
生存予測
学習したモデルが、validセット(検証用データ)に対してどのくらい予測性能があるか確認します。
1
2
3
| # valid_xについて推論
oof = (gbm.predict(valid_x) > 0.5).astype(int)
print('score', round(accuracy_score(valid_y, oof) * 100, 2))
|

約82.7%の正解率で予測できました。
学習の状況が、eval_resultsに格納されているので学習曲線を表示してみます。
1
2
3
4
5
| import matplotlib.pyplot as plt
plt.plot(evals_result['training']['binary_logloss'], label='train_loss')
plt.plot(evals_result['valid_1']['binary_logloss'], label='valid_loss')
plt.legend()
|
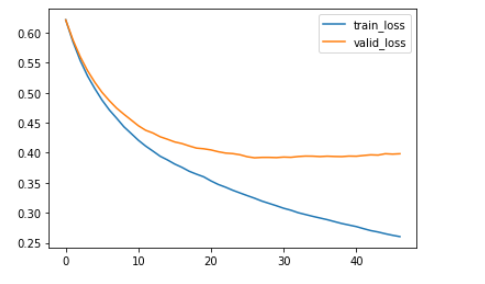
train(訓練)のロスは下がり続けていますが、valid(検証)のロスは20roundあたりから下がりにくくなっています。
ロスが最も少なくなるのが27roundであり、推論はこの27roundで行われます。
predict関数のnum_iterationでroundを指定することができますが、指定しない場合はbestのroundが使われます。
(実行環境としてGoogleさんのColaboratoryを使用ています。)