今回はアルゴリズムに決定木を使ってみます。
決定木とは、ツリー状に条件分岐を繰り返すことによって分類するクラスを予測するモデルです。
枝分かれ部分の条件は、データの変数を使って作ります。
データ読み込みと前処理
Kaggleに準備されているタイタニックの訓練データを読み込みます。
データの前処理(不要列の削除・欠損処理・カテゴリ変数の変換)と、正解ラベルとそれ以外にデータを分けるところまで一気に実行します。
[ソース]
1 | import numpy as np |
決定木アルゴリズムで学習・推測
決定木アルゴリズムを準備します。
学習・推測を行う前に、分割交差検証を使ってどのくらいの正答率になるか調べてみます。
[ソース]
1 | from sklearn import svm, metrics, model_selection |
[出力]
平均正解率は78.34%とそこそこの結果というところでしょうか。
決定木アルゴリズムで学習を行い、データを予測し提出用のCSVファイルを作成します。
[ソース]
1 | # 学習する |
予測結果を提出します。
[提出結果]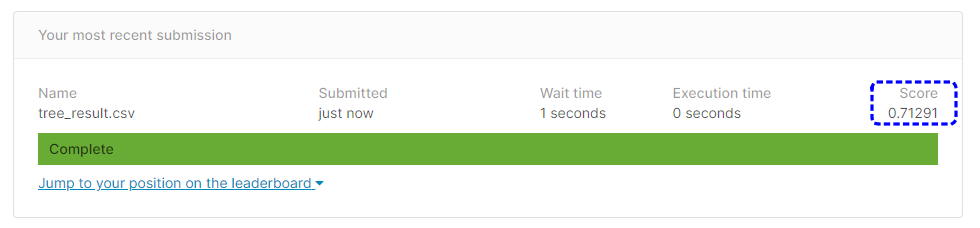
提出結果は71.291%という正解率になりました。
前回記事のSVMの時よりはましになりましたが、7割程度の正解率ではイマイチですね。