これまでデータの前処理を行うときに、カテゴリー変数についてはOne-Hotエンコーディングを行っていました。
しかし【LightGBMのドキュメント】によると、カテゴリー変数はOne-Hotエンコーディングするよりも0から始まる連続した整数に変換するほうが優れたパフォーマンスを発揮するとのことでした。
今回はOne-Hotエンコーディングの代わりに、カテゴリー変数を整数に変換してタイタニック・コンペに提出してみます。
データ読み込みと前処理
まずはいつも通りタイタニックのデータセットを読み込みます。
[ソース]
1
2
3
4
| import numpy as np
import pandas as pd
df_train = pd.read_csv('/kaggle/input/titanic/train.csv')
|
今回のポイントであるデータ前処理ですが、LightGBMで学習・推測するためには下記の5変数を変換する必要があります。
- Name
- Sex
- Ticket
- Cabin
- Embarked
このうち生存率に関係のなさそうなNameとTicketとCabinは単純に削除します。
そしてSexとEmbarkedを整数に変換したいのですが、一番カンタンそうな方法はデータ型をcategory型に変えることでした。
こうすることによって、自動でカテゴリーを変換した整数として扱ってくれるので、自分で0や1などの整数に置き換える必要がなくとてもラクチンでした。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # データ前処理
def preprocessing(df):
# 不要な列の削除
df.drop(['Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# カテゴリ変数の変換
# df = pd.get_dummies(df, columns=['Sex', 'Embarked'])
df['Sex'] = df['Sex'].astype('category')
df['Embarked'] = df['Embarked'].astype('category')
return df
x_titanic = preprocessing(df_train.drop(['Survived'], axis=1))
y_titanic = df_train['Survived']
|
データの前処理が終わりましたら、以前実行した時と同じようにLightGBMを使って学習を行います。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| import lightgbm as lgb
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
# 3分割交差検証を指定しインスタンス化する
kf = KFold(n_splits=3, shuffle=True)
# スコアとモデルを格納するリスト
score_list = []
models = []
for fold_, (train_index, valid_index) in enumerate(kf.split(x_titanic, y_titanic)):
print(f'fold{fold_ + 1}start')
train_x = x_titanic.iloc[train_index]
valid_x = x_titanic.iloc[valid_index]
train_y = y_titanic.iloc[train_index]
valid_y = y_titanic.iloc[valid_index]
# lab.Datasetを使って、trainとvalidを作っておく
lgb_train = lgb.Dataset(train_x, train_y)
lgb_valid = lgb.Dataset(valid_x, valid_y)
# パラメータを定義
lgbm_params = {'objective': 'binary'}
# lgb.trainで学習
evals_result = {}
gbm = lgb.train(params=lgbm_params,
train_set=lgb_train,
valid_sets=[lgb_train, lgb_valid],
early_stopping_rounds=20,
evals_result=evals_result,
verbose_eval=-1) # 学習の状態を表示しない
# valid_xについて推論
oof = (gbm.predict(valid_x) > 0.5).astype(int)
score_list.append(round(accuracy_score(valid_y, oof) * 100, 2))
# 学習が終わったモデルをリストに入れておく
models.append(gbm)
print(f'fold_{fold_ + 1} end\n')
print(score_list, '平均score', round(np.mean(score_list), 2))
|
[出力]
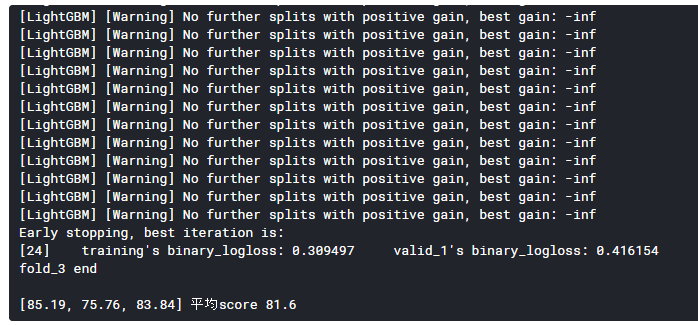
平均正解率は81.6%とそこそこの結果というところでしょうか。
最後に、学習したモデルを使って、生存の推測を行い提出用のCSVファイルを出力します。
検証データに対してもデータの前処理(3行目)を行うことをお忘れなく。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| # 検証データの読み込み
df_test = pd.read_csv('/kaggle/input/titanic/test.csv')
df_test = preprocessing(df_test)
# テストデータの予測を格納する行列を作成
test_pred = np.zeros((len(df_test), 3))
for fold, gbm in enumerate(models):
test_pred[:, fold] = gbm.predict(df_test)
result = pd.DataFrame(df_test['PassengerId'])
# 平均が0.5より大きい場合,1(生存)とする
result['Survived'] = (np.mean(test_pred, axis=1) > 0.5).astype(int)
result
result.to_csv('result.csv', index=False)
|
予測結果を提出します。
[提出結果]
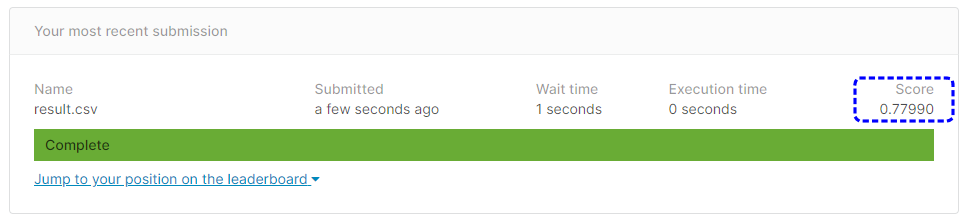
提出結果は77.99%という正解率になりました。
カテゴリ変数をOne-Hotエンコーディングしときの結果は75.59%でしたので2.4%ほど正解率が上がりました。