前回記事にてはじめてKaggleコンペの1つタイタニック(Titanic)に結果を提出(Submit)してみました。
結果としては正解率75%ほどで十分な結果とは言えなかったので、手法を少し変えて成績を向上させたいと思います。
今回はアルゴリズムをLightGBMからSVMに変更してみます。
SVMは以前、アヤメの品種を分類するときに使用しました。
Python scikit-learn - 機械学習でアヤメの品種を分類する - https://ailog.site/2020/04/21/0421/
データ読み込み
まずは、Kaggleに準備されているタイタニックの訓練データを読み込みます。
[ソース]
1
2
3
4
| import numpy as np
import pandas as pd
df_train = pd.read_csv('/kaggle/input/titanic/train.csv')
|
データの前処理(不要列の削除・欠損処理・カテゴリ変数の変換)を行う処理を関数化します。
LightGBMとは違ってSVMでは欠損値があると学習できないので、欠損値が1つもなくなるように気を付けます。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # データ前処理
def preprocessing(df):
# 不要な列の削除
df.drop(['Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 欠損値処理
df['Age'] = df['Age'].fillna(df['Age'].median())
df['Fare'] = df['Fare'].fillna(df['Fare'].median())
df['Embarked'] = df['Embarked'].fillna('S')
# カテゴリ変数の変換
df = pd.get_dummies(df, columns=['Sex', 'Embarked'])
return df
|
データを正解ラベルとそれ以外に分けて、学習を行います。
今回はとりあえず1度だけ学習を行い、学習済みモデルを1つだけ作成しました。
[ソース]
1
2
3
4
5
6
7
8
| x_titanic = df_train.drop(['Survived'], axis=1)
y_titanic = df_train['Survived']
from sklearn import svm
# データの学習
clf = svm.SVC()
clf.fit(preprocessing(x_titanic), y_titanic)
|
検証データを読み込み、予測を行います。
予測したデータをコンペ提出用にcsvファイル出力します。
[ソース]
1
2
3
4
5
6
7
8
| # データを予測
df_test = pd.read_csv('/kaggle/input/titanic/test.csv')
pre = clf.predict(preprocessing(df_test))
# 予測結果をファイルに出力
result = pd.DataFrame(df_test['PassengerId'])
result['Survived'] = pre
result.to_csv('svm_result.csv', index=False)
|
出力したsvm_result.csvを提出した結果は次の通りです。
[提出結果]
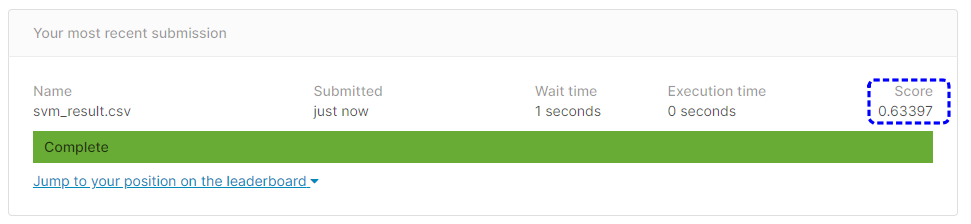
提出結果は63.397%という正解率になりました。
LightGBMの時よりだいぶ正解率が下がってしまいました。。。