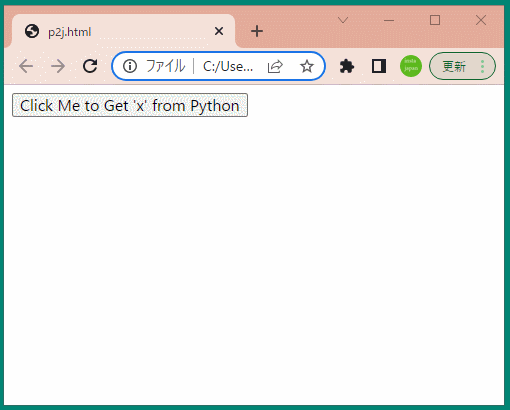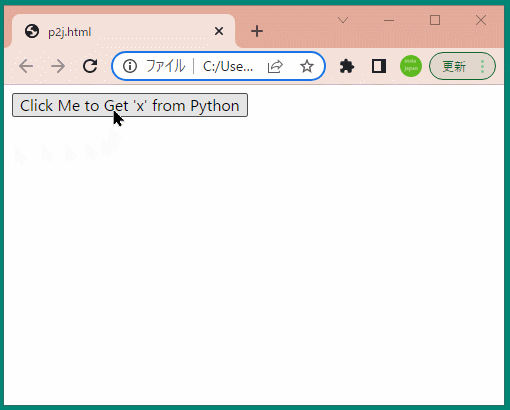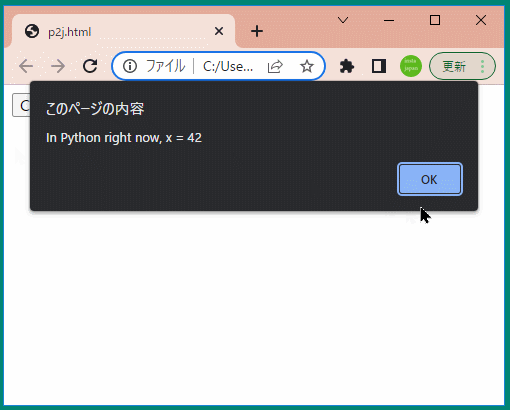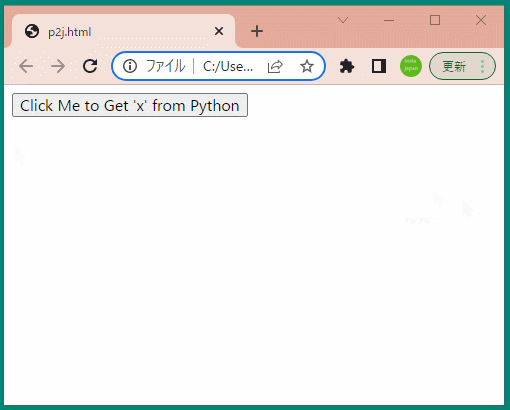
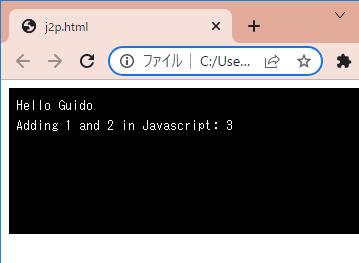
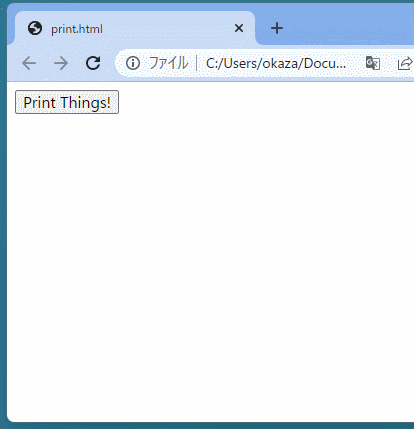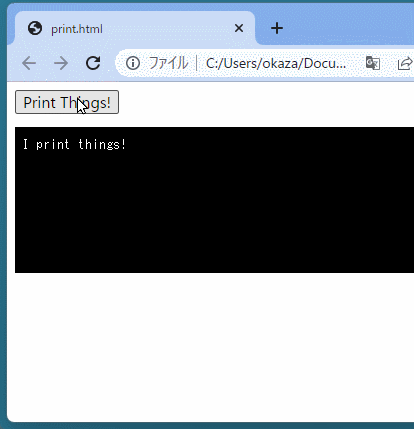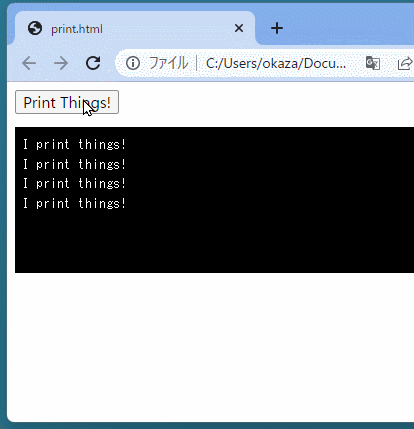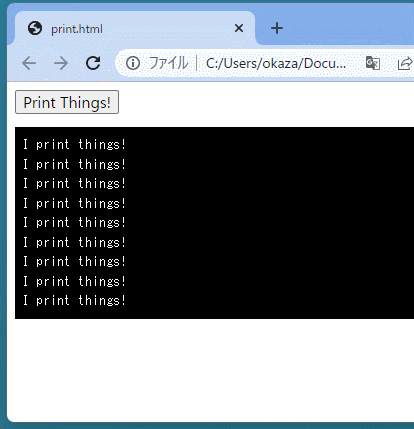
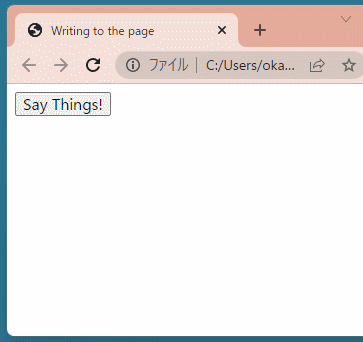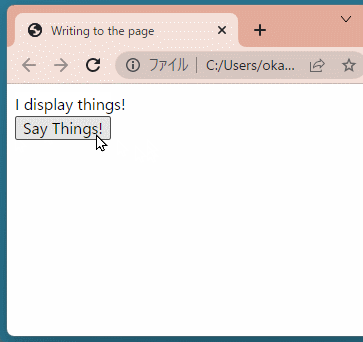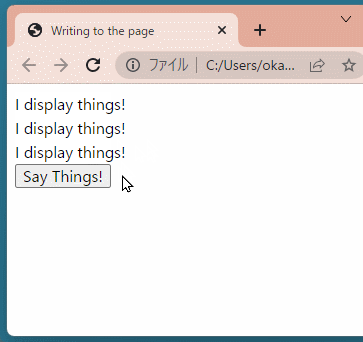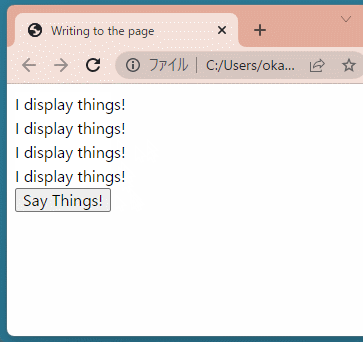
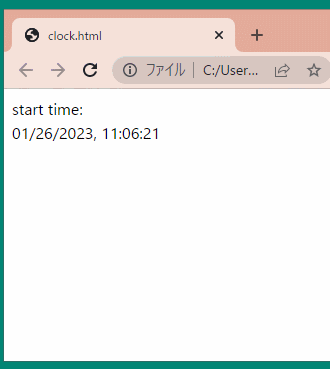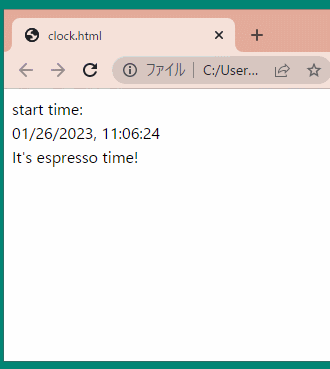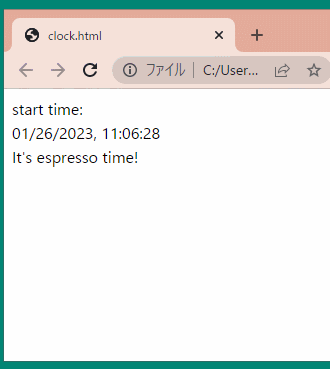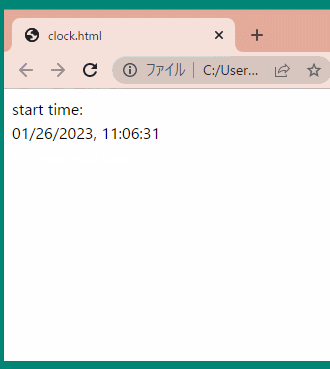
<buttononclick="showX()">Click Me to Get 'x' from Python</button> <script> functionshowX(){ alert(`In Python right now, x = ${pyscript.runtime.globals.get('x')}`) } </script>
<html> <head> <title>Writing to the page</title> <linkrel="stylesheet"href="https://pyscript.net/latest/pyscript.css" /> <scriptdefersrc="https://pyscript.net/latest/pyscript.js"></script> </head>
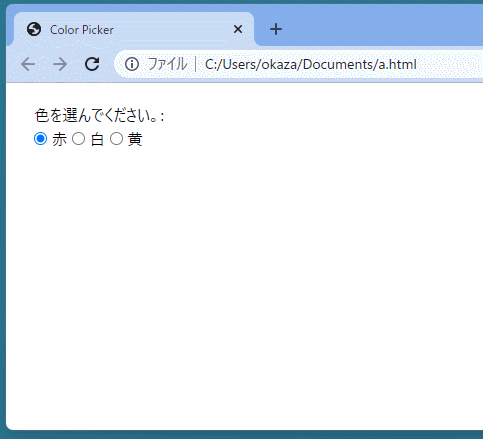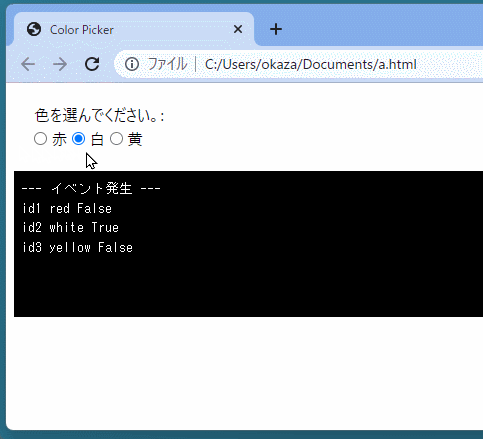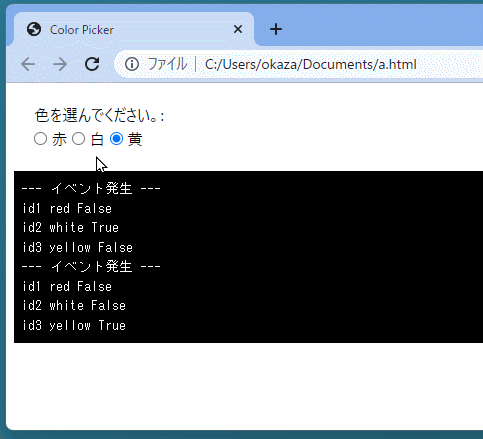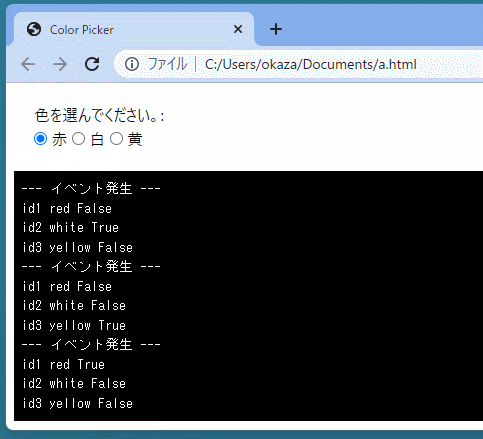
def select_color(event): print('--- イベント発生 ---') for ele in color_elements: print(ele.id, ele.value, ele.checked)
color_elements = js.document.getElementsByName("color") ele_proxy = create_proxy(select_color) for ele in color_elements: if ele.value == "red": ele.checked = True ele.addEventListener("change", ele_proxy) </py-script>