飲食業の需要予測
飲食業の需要予測 の例題をProphet を使用して解いてみましょう。
まず、仮想のデータセットを用意しましょう。
例えば、過去4年間のあるレストランの月間売上データを持っているとします。
以下にデータの例を示します:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 日付,売上 2022-01-01,1000 2022-02-01,1200 2022-03-01,1100 2022-04-01,1300 2022-05-01,1400 2022-06-01,1500 2022-07-01,1300 2022-08-01,1200 2022-09-01,1100 2022-10-01,1000 2022-11-01,1200 2022-12-01,1300 2023-01-01,1400 2023-02-01,1500 2023-03-01,1600 2023-04-01,1400 2023-05-01,1300 2023-06-01,1200 2023-07-01,1100 2023-08-01,1000 2023-09-01,1200 2023-10-01,1300 2023-11-01,1400 2023-12-01,1500 2024-01-01,1600 2024-02-01,1700 2024-03-01,1500 2024-04-01,1400 2024-05-01,1300 2024-06-01,1200 2024-07-01,1100 2024-08-01,1000 2024-09-01,1200 2024-10-01,1300 2024-11-01,1400 2024-12-01,1500 2025-01-01,1600 2025-02-01,1700 2025-03-01,1800 2025-04-01,1600 2025-05-01,1500 2025-06-01,1400 2025-07-01,1300 2025-08-01,1200 2025-09-01,1100 2025-10-01,1000 2025-11-01,1200 2025-12-01,1300
それでは、PythonのProphetライブラリを使用してこのデータセットで需要予測を行ってみましょう。
まず、Prophetライブラリがインストールされていない場合は、次のコマンドを使用してインストールします:
インストールが完了したら、以下のコードを使って進めます。
以下は、提供されたデータセットを使用してProphetを使った需要予測を行う例です:
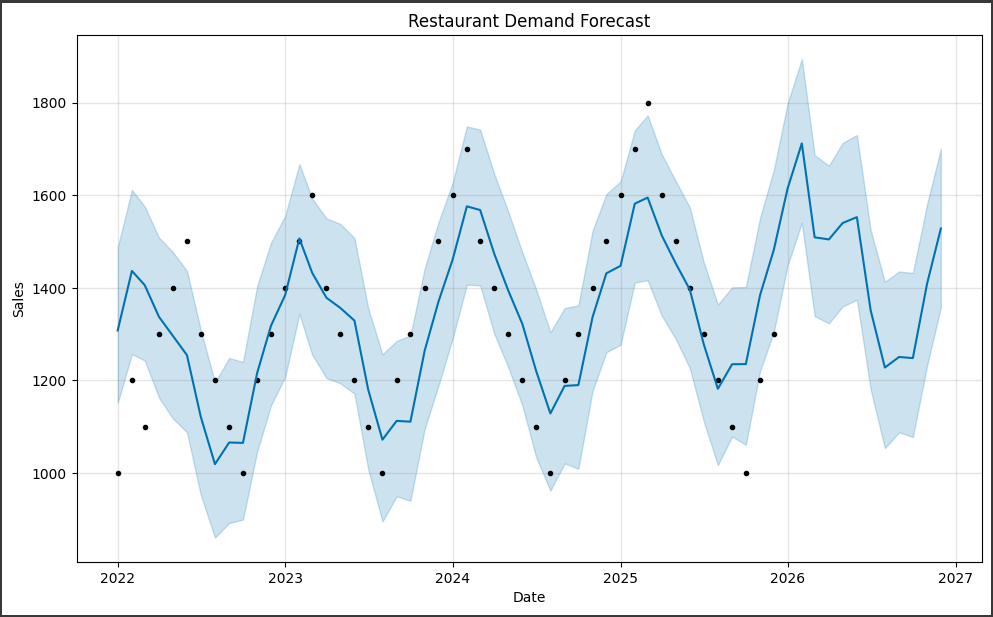
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import pandas as pdfrom prophet import Prophetimport matplotlib.pyplot as pltdata = pd.read_csv('データセットのパス.csv' ) data = data.rename(columns={'日付' : 'ds' , '売上' : 'y' }) model = Prophet() model.fit(data) future_dates = model.make_future_dataframe(periods=12 , freq='M' ) forecast = model.predict(future_dates) model.plot(forecast, xlabel='Date' , ylabel='Sales' ) plt.title('Restaurant Demand Forecast' ) plt.show()
この例では、まず必要なライブラリをインポートし、Prophetもインポートしています。
次にデータセットを読み込み、列名をProphetの予測モデルに合わせて変更しています。
その後、Prophetモデルを作成し、データにフィットさせ、予測のための未来の日付を生成します。
最後に、モデルを使用して未来の日付の売上を予測し、予測結果をグラフ化しています。
'データセットのパス.csv'の部分は、実際のデータセットファイルのパスに置き換えてください。
また、make_future_dataframeのperiodsパラメータを調整して、予測する未来の期間の数を指定することもできます。
ソースコード解説
以下、コードの各部分の詳細な説明です。
1. ライブラリのインポート: 1 2 3 import pandas as pdfrom prophet import Prophetimport matplotlib.pyplot as plt
pandas: データ操作や分析のためのPythonライブラリ。Prophet: Facebookが開発した時系列予測ライブラリ。このライブラリを使用して時系列モデルを構築し、予測を行う。matplotlib.pyplot: グラフを描画するためのPythonライブラリ。
2. データセットの読み込み: 1 data = pd.read_csv('データセットのパス.csv' )
CSV形式のデータセットを読み込み、dataという名前のDataFrame(表形式のデータ構造)に格納しています。
3. データの準備: 1 data = data.rename(columns={'日付' : 'ds' , '売上' : 'y' })
データのカラム名をProphetの予測モデルに合わせるために変更しています。'日付'カラムは時系列の日付を表し、'売上'カラムは予測する対象の数値データ(売上)を表しています。
4. Prophetモデルの作成: Prophetのモデルをインスタンス化します。
5. モデルのデータへのフィッティング(適合): dataに格納されたデータを使用して、Prophetモデルに適合させます。
6. 未来の日付の生成: 1 future_dates = model.make_future_dataframe(periods=12 , freq='M' )
予測を行うための未来の日付を生成します。periodsで指定した期間(ここでは12ヶ月)分の日付を生成し、freqで頻度を’M’(月ごと)として指定しています。
7. 予測の実行: 1 forecast = model.predict(future_dates)
未来の日付に対して予測を実行し、forecastというDataFrameに予測結果を格納します。
8. 予測結果のグラフ化: 1 2 3 model.plot(forecast, xlabel='Date' , ylabel='Sales' ) plt.title('Restaurant Demand Forecast' ) plt.show()
予測結果をグラフ化して表示します。
このコードは、Prophetを使用して時系列データの売上予測を行い、その結果を可視化する一連の手順を示しています。
結果解説
グラフの内容を詳しく説明します。
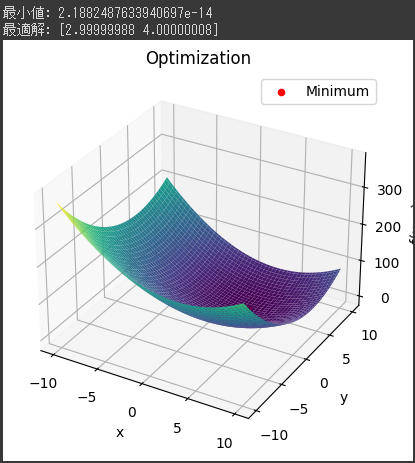
1. データポイント(黒い点): グラフ上に表示される黒い点は、実際の売上データポイントを表しています。
これらの点は、元のデータセットから取得され、予測モデルの作成に使用されました。
2. 予測値(青い線): グラフ上に表示される青い線は、Prophetモデルによって予測された売上の値を表しています。
3. 不確実性範囲(青い領域): グラフ上に表示される青い領域は、予測値の不確実性範囲を表しています。
このグラフを通じて、過去のデータからのトレンドや季節性を考慮した予測値が表示されます。
また、不確実性範囲も示されるため、予測の信頼性を評価することができます。