今回は、学習中のログをファイル出力し取得報酬がどのように変化していくのかをグラフ化して確認してみます。
ログファイル出力
前回学習を行ったソース(train3.py)を変更して、取得報酬をログファイルに出力します。
変更箇所はソースコメントで# 追加としています。
[ソース]
1 | # 警告を非表示 |
コンソールに出力される実行ログには平均エピソード長(ep_len_mean)と平均報酬(ep_reward_mean)が追加で表示されるようになります。
[結果]
--------------------------------------- | approxkl | 9.941752e-05 | | clipfrac | 0.0 | | ep_len_mean | 248 |←平均エピソード長 | ep_reward_mean | -148 |←平均報酬 | explained_variance | -0.00303 | | fps | 1391 | | n_updates | 4 | | policy_entropy | 1.375106 | | policy_loss | -0.00035295845 | | serial_timesteps | 512 | | time_elapsed | 0.58 | | total_timesteps | 512 | | value_loss | 573.96643 | --------------------------------------- -------------------------------------- | approxkl | 2.3577812e-05 | | clipfrac | 0.0 | | ep_len_mean | 248 | | ep_reward_mean | -148 | | explained_variance | 0.00585 | | fps | 1301 | | n_updates | 5 | | policy_entropy | 1.3737429 | | policy_loss | 3.933697e-05 | | serial_timesteps | 640 | | time_elapsed | 0.673 | | total_timesteps | 640 | | value_loss | 110.2445 | -------------------------------------- -------------------------------------- | approxkl | 5.579695e-06 | | clipfrac | 0.0 | | ep_len_mean | 186 | | ep_reward_mean | -85.2 | | explained_variance | 0.00289 | | fps | 1362 | | n_updates | 6 | | policy_entropy | 1.372483 | | policy_loss | 4.9524475e-05 | | serial_timesteps | 768 | | time_elapsed | 0.771 | | total_timesteps | 768 | | value_loss | 568.43945 | -------------------------------------- : (略) : -------------------------------------- | approxkl | 6.53077e-08 | | clipfrac | 0.0 | | ep_len_mean | 9 | | ep_reward_mean | 92 | | explained_variance | 1 | | fps | 1298 | | n_updates | 998 | | policy_entropy | 0.010556959 | | policy_loss | -8.293893e-05 | | serial_timesteps | 127744 | | time_elapsed | 94.1 | | total_timesteps | 127744 | | value_loss | 2.708827e-07 | -------------------------------------- ------------------------------------- | approxkl | 0.0059474623 | | clipfrac | 0.01171875 | | ep_len_mean | 9.02 | | ep_reward_mean | 92 | | explained_variance | 0.998 | | fps | 1311 | | n_updates | 999 | | policy_entropy | 0.0095445085 | | policy_loss | -0.014048491 | | serial_timesteps | 127872 | | time_elapsed | 94.2 | | total_timesteps | 127872 | | value_loss | 0.026215255 | ------------------------------------- -------------------------------------- | approxkl | 5.6422698e-09 | | clipfrac | 0.0 | | ep_len_mean | 9.02 |←平均エピソード長 | ep_reward_mean | 92 |←平均報酬 | explained_variance | 1 | | fps | 1291 | | n_updates | 1000 | | policy_entropy | 0.007281434 | | policy_loss | -6.94443e-05 | | serial_timesteps | 128000 | | time_elapsed | 94.3 | | total_timesteps | 128000 | | value_loss | 0.0016018704 | --------------------------------------
最終的には平均報酬が92で安定していることがわかります。
また、logフォルダが作成されその中にmonitor.csvファイルが出力されます。
「r,l,t」はそれぞれ「報酬、エピソード長、経過時間」を意味しています。
1 | #{"t_start": 1621889575.6633413, "env_id": null} |
グラフ化
monitor.csvを読み込み、報酬をグラフ化します。
[ソース]
1 | import pandas as pd |
[結果]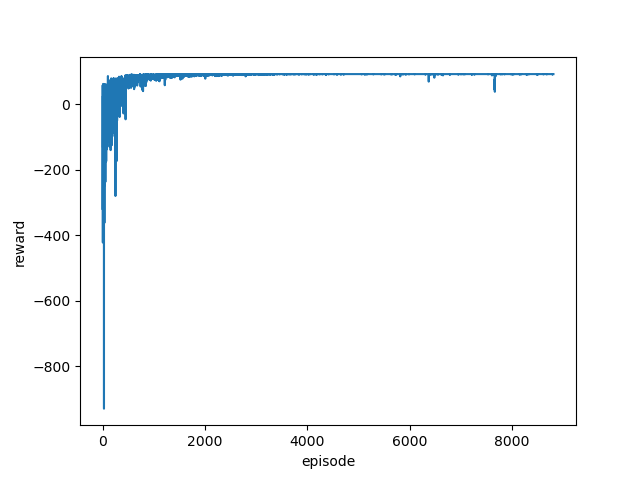
学習はじめはマイナス報酬が大きくなっていますが、学習が進むにつれマイナス報酬が減っていき最終的にはプラス報酬で安定していることが見て取れます。
次回は、カスタムGym環境(env3.py)で定義したマップをもう少し複雑にしても、きちんと学習できるのかどうかを見ていきたいと思います。