前回カスタム環境として、簡単なマップを作りスタート地点からゴール地点まで移動する環境を作成しました。
今回はStable BaselinesのPPO(PPO2)アルゴリズムを使って、強化学習を行いそのカスタム環境を効率よく攻略してみます。
強化学習
カスタム環境を読み込み、PPO(PPO2)アルゴリズムで学習を行います。
前前回学習した処理(train3_log.py)からの変更点は次の2点のみです。
- 9行目
読み込むカスタムGym環境をenv3からenv4に変更 - 31行目
学習済みモデルの出力ファイル名をmodel3からmodel4に変更
[ソース]
1 | # 警告を非表示 |
[結果(途中略)]
--------------------------------------- | approxkl | 0.00013371343 |(新しい方策から古い方策へのKullback-Leibler発散尺度) | clipfrac | 0.0 |(クリップ範囲ハイパーパラメータが使用される回数の割合 | explained_variance | -0.0241 |(誤差の分散) | fps | 405 |(1秒あたりのフレーム数) | n_updates | 1 |(更新回数) | policy_entropy | 1.3861077 |(方策のエントロピー) | policy_loss | -0.00052567874 |(方策の損失) | serial_timesteps | 128 |(1つの環境でのタイプステップ数) | time_elapsed | 0 |(経過時間) | total_timesteps | 128 |(全環境でのタイムステップ数) | value_loss | 111.95057 |(価値関数更新時の平均損失) --------------------------------------- -------------------------------------- | approxkl | 0.00023907197 | | clipfrac | 0.0 | | explained_variance | 0.00739 | | fps | 1362 | | n_updates | 2 | | policy_entropy | 1.3846728 | | policy_loss | -0.001835278 | | serial_timesteps | 256 | | time_elapsed | 0.316 | | total_timesteps | 256 | | value_loss | 110.1702 | -------------------------------------- -------------------------------------- | approxkl | 0.0002260478 | | clipfrac | 0.0 | | explained_variance | 0.00444 | | fps | 1320 | | n_updates | 3 | | policy_entropy | 1.3818537 | | policy_loss | -0.0009469581 | | serial_timesteps | 384 | | time_elapsed | 0.41 | | total_timesteps | 384 | | value_loss | 108.967865 | -------------------------------------- : (略) : -------------------------------------- | approxkl | 0.003960348 | | clipfrac | 0.048828125 | | ep_len_mean | 1.24e+04 |←平均エピソード長 | ep_reward_mean | -1.23e+04 |←平均報酬 | explained_variance | 0.879 | | fps | 1433 | | n_updates | 998 | | policy_entropy | 1.1028377 | | policy_loss | -0.0012131184 | | serial_timesteps | 127744 | | time_elapsed | 92.8 | | total_timesteps | 127744 | | value_loss | 3.6379788e-11 | -------------------------------------- -------------------------------------- | approxkl | 0.0034873062 | | clipfrac | 0.0 | | ep_len_mean | 1.24e+04 | | ep_reward_mean | -1.23e+04 | | explained_variance | 0.794 | | fps | 1385 | | n_updates | 999 | | policy_entropy | 1.1340904 | | policy_loss | -0.0011979407 | | serial_timesteps | 127872 | | time_elapsed | 92.9 | | total_timesteps | 127872 | | value_loss | 3.45608e-11 | -------------------------------------- --------------------------------------- | approxkl | 0.0054595554 | | clipfrac | 0.041015625 | | ep_len_mean | 1.24e+04 | | ep_reward_mean | -1.23e+04 | | explained_variance | 0.728 | | fps | 1419 | | n_updates | 1000 | | policy_entropy | 1.1066511 | | policy_loss | -0.00089572184 | | serial_timesteps | 128000 | | time_elapsed | 93 | | total_timesteps | 128000 | | value_loss | 3.6322945e-11 | ---------------------------------------
平均報酬が最後までマイナスなのが気になります・・・。
平均報酬を確認
学習したモデルを実行する前にmonitor.csvを読み込み、グラフ化して平均報酬の遷移を確認します。
(前回ソースlog_graph.pyと全く同じものです。)
[ソース]
1 | import pandas as pd |
[結果]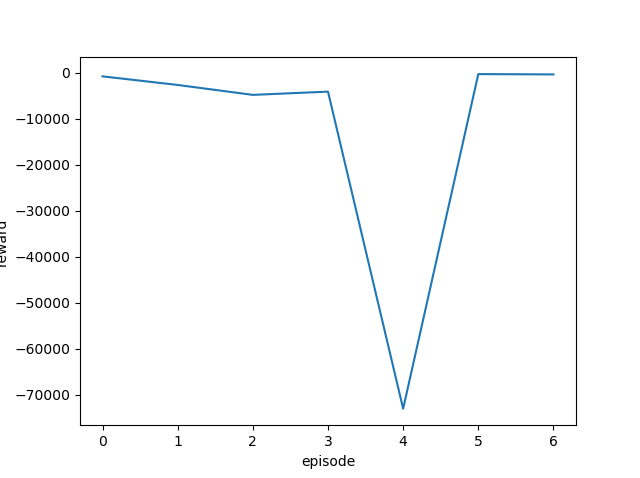
予想していたものとだいぶ違う結果となりました。
表示されているエピソードが7つしかないので結果が収束しているかどうかわかりません・・・というかきっと収束(学習)していないんでしょう。
log/monitor.csvを確認すると次のようになっていました。
[monitor.csv]
#{"t_start": 1622061308.762112, "env_id": null}
r,l,t
-754,855,1.429902
-2622,2723,3.449695
-4777,4878,7.05819
-4072,4173,10.048853
-72982,73083,63.42402
-260,361,63.682051
-332,433,63.981119
確かに結果のでているエピソードは7つしかありませんね。しかも全てマイナス報酬(rの列)となっています。
マップを少しだけ複雑にしただけなので、同じ手法で問題なく攻略してくれると予想していたのですが、何か対策を行う必要がありそうです。
(ちなみにこの学習済みモデルを読み込んで実行したところ、スタート地点から全く移動しないという状況でした😱)