強化学習を実践していく上でシミュレータが必要なことがわかり、シミュレータとしてはUnityが便利だということがわかり、さらにUnity ML-Agentsを使うとPythonからUnityを動作させることが分かりました。
そして参考文献を探したところ目的にはまった下記の書籍を見つけましたがバージョンが古いせいでしょうか、まったく動作させることができずしばらく放置していました。
しかしなんとか動作させることができるようになったので備忘録としてまとめておきます。

Pythonで学ぶ強化学習 -入門から実践まで- サンプルコード
【手順1】Unityインストール
書籍(P.41)にしたがってUnityをインストールします。
私の環境ではUnityのバージョンは2017.3.1f1 (64-bit)を使用しました。
【手順2】Unity ML-Agents v0.4.0bダウンロード
サポートサイトに記載されていますが、下記のリンクからUnity ML-Agents v0.4.0bをダウンロードします。
https://github.com/Unity-Technologies/ml-agents/tree/0.4.0b
※2019/11/16現在の最新バージョンは0.11なのでかなり古いバージョンです。
【手順3】TensorFlowSharpプラグインダウンロード
書籍(P.42)にしたがってTensorFlowSharpプラグインをダウンロードをインストールします。
【手順4】Pythonインストール
書籍(P.43)にしたがってPythonをインストールし、仮想環境を構築します。
Pythonバージョンは3.6で問題ありません。
【手順5】Pythonパッケージインストール
書籍(P.44)に該当する箇所ですが、【手順2】でダウンロードしたファイルを使ってPythonパッケージをインストールします。
ダウンロードしたものの中にpythonフォルダがありますのでそのフォルダに移動してインストールコマンドを実行します。
1 | cd (ダウンロードした中のpythonフォルダ) |
【手順6】Numpyバージョン変更
ここが一番はまったポイントでした。
Numpyのバージョンは1.17.4がインストールされていたのですがこれを1.14.5に落とします。
1 | pip uninstall numpy |
(動作確認時に配列関連エラーでExceptionが発生していたのでnumpyのバージョンを疑い、結果動作させることができるようになりました。)
【手順7】プロジェクト設定
書籍(P.47~P.49)にしたがってプロジェクトの設定を行います。
【手順8】Unity Editorで動作確認
書籍(P.50~P.52)のexeを作っての実行はうまくいかないのであきらめました。
書籍(P.63)「Unity Editor上での学習」の方を実行したところ問題なく動作確認できました。
以上で一通り書籍に書かれているサンプルを実行させることができるようになります。
もしこれでもうまくいかない場合のため、動作確認ができた環境のライブラリバージョン一覧を書いておきますので、参考にして頂ければと思います。
1 | > pip list |
私と同じように動作確認をあきらめてしまった方の一助になれば幸いです。
経験の蓄積と活用のバランス Epsion-Greedey法
経験の蓄積と活用のトレードオフのバランスをとる手法としてEpsilon-Greedy法を実装します。
何枚かのコインから1枚を選んで、投げた時表が出れば報酬が得られるゲームを考えます。
各コインの表が出る確率はバラバラです。
必要なパッケージをインポートします。
1 | import random |
コイントスゲームの実装を行います。
head_probsは配列のパラメータで各コインの表が出る確率を指定します。
max_episode_stepsはコイントスを行う回数で、この回数の実行して表がでた回数が報酬となります。
1 | class CoinToss(): |
エージェントを作成します。
policy関数で、epsilonの確率でランダムにコインを選択し(探索)、それ以外の確率で各コインの期待値にそってコインを選択します(活用)。
play関数は、コイントスを行う処理です。
1 | class EpsilonGreedyAgent(): |
5枚のコインを用意し、コイントスの回数を変えながら、各エピソードにおける1回のコイントスあたりの報酬を記録していきます。
1 | if __name__ == "__main__": |
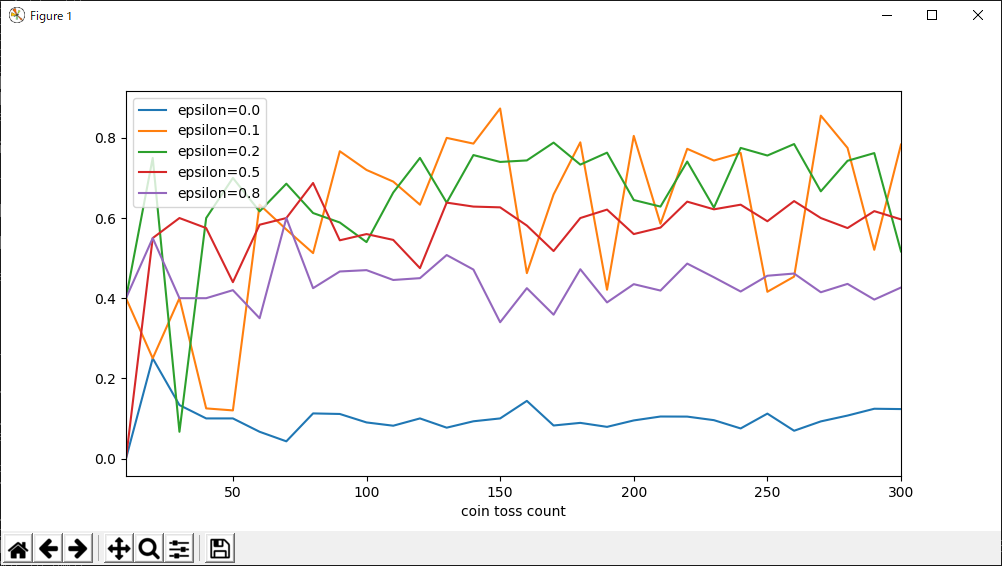
epsilon=0.1と0.2ではコイントスの回数とともに報酬が向上していることが分かります。
参考
Pythonで学ぶ強化学習 -入門から実践まで- サンプルコード
価値の定義と算出 Bellman Equation
価値を再帰的かつ期待値で表現する手法をBellman Equationと呼びます。(Valueベース)
Bellman Equationを使えば各状態の価値が計算可能となります。
まず価値を返す関数を定義します。
1 | def V(s, gamma=0.99): |
報酬関数を定義します。
エピソード終了のとき”happy_end”であれば1を返し、”bad_end”であれば-1を返します。
エピソードが終了していなければ0を返します。
1 | def R(s): |
全ての行動でV(s)を計算し値が最大になる価値を返します。
評価vの計算式は確率遷移×遷移先の価値となります。
upかdownかを繰り返していき5回行動したら終了となります。
1 | def max_V_on_next_state(s): |
遷移関数を定義します。
- 引数sには”state”や”state_up_up”、”state_down_down”などが受け渡されます。
- 引数aは”up”か”down”が設定されます。
- エピソード完了時は1要素が返り、途中の場合は2要素が返ります。
1 | def transit_func(s, a): |
実際に価値V(s)の計算を行ってみます。
1 | if __name__ == "__main__": |
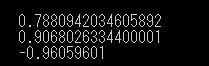
upの数が多い方が評価されます。
参考
Pythonで学ぶ強化学習 -入門から実践まで- サンプルコード
マルコフ決定過程(MDP)
マルコフ決定過程(MDP)に従う環境を構築します。
マルコフ決定過程(MDP)は次のようなルールに従います。
- 遷移先の状態は直前の状態とそこでの行動のみに依存する。
- 報酬は直前の状態と遷移先に依存する。
今回は次のような迷路を解く環境を実装します。
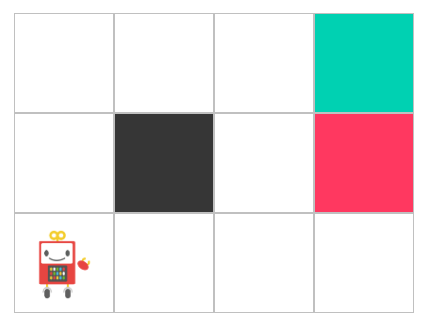
まずは必要なパッケージをインポートします。
1 | import random |
状態を表すクラスを定義します。
縦位置をrow、横位置をcolumnで表します。
1 | class State(): |
行動を表すクラスを定義します。
行動は上下左右への移動4種類です。
1 | class Action(Enum): |
環境の実体となるクラスを定義します。
迷路の定義を2次元配列のgridで受け取ります。
gridの要素は次のような意味となります。
| 値 | 意味 |
|---|---|
| 0 | 移動可能な場所を表します。 |
| -1 | ダメージを受ける場所でゲーム終了となります。 |
| 1 | 報酬を得られる場所でゲーム終了となります。 |
| 9 | 壁を意味し移動することができない場所です。 |
default_rewardは基本の報酬となり、この変数をマイナスにすることで意味なく行動することを防ぎ、早くゴールに向かうことを促します。
1 | class Environment(): |
遷移関数を定義します。
選択した行動にはmove_prob(80%)の行動確率を設定し、反対の行動には0%の行動確率を設定します。
残りの2方向の移動には10%の行動確率を設定します。
(トータルの行動確率は100%になります。)
1 | def transit_func(self, state, action): |
行動できる場所(状態)かどうかを判定する関数を定義します。
1 | def can_action_at(self, state): |
ある状態である行動をすると、次にどの状態になるかを返す関数を定義します。
迷路の範囲外への移動を防いだり、壁にぶつかったかどうかはこの関数内で判断します。
1 | def _move(self, state, action): |
報酬関数を定義します。
ある状態で報酬が得られるかどうか、ダメージを受けるかどうかを判定します。
ゲームが終了するかどうかもこの報酬関数で判定します。
1 | def reward_func(self, state): |
エージェントの位置を初期化する関数を定義します。
ゲーム開始時や、ゲームが終わり再度ゲームを開始する場合に使用します。
1 | def reset(self): |
行動を行う関数を定義します。
行動を受け取り、遷移関数から遷移先を算出し、さらに報酬関数から即時報酬を取得します。
1 | def step(self, action): |
遷移関数を定義します。
行動を受け取り、遷移関数を使って行動確率を取得します。
行動確率から実際にどう行動するかどうかを最終決定します。(np.random.choice関数を使用)
決定した行動より遷移先と報酬、終了したかどうかの結果が導きだされます。
1 | def transit(self, state, action): |
エージェントを定義します。
エージェントのpolicyは状態を受け取って行動を決める関数ですが、今回は単純にランダム行動をとるようにしています。
1 | class Agent(): |
環境内でエージェントを動作させるコードを実装します。
迷路の定義(grid)を行い、それをもとにして環境(Environment)作成します。
作成した環境をエージェントに渡して、そのエージェントを行動させることでゲームが実行されます。
1 | def main(): |
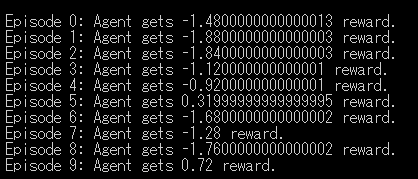
単純なランダム行動ですが、10ゲーム行い10回分の報酬を取得できることを確認できます。
参考
Pythonで学ぶ強化学習 -入門から実践まで- サンプルコード
進化戦略と遺伝的アルゴリズム
ニューラルネットワークの学習では勾配法が使われることが一般的ですが、勾配法とは違うアプローチとして「進化戦略」と「遺伝的アルゴリズム」があります。
進化戦略
パラメータを複数生成し、各パラメータを使った場合のモデルを評価します。
評価がよいものに近いパラメータをさらに生成し、評価を行うというプロセスを繰り返します。
(多くの候補から優秀なものを絞り込むというアプローチです)
遺伝的アルゴリズム
進化戦略と基本は同じですが、評価が高かったパラメータ同士を混ぜる(交叉)、ランダムなパラメータを入れる(突然変異)という操作を行います。
模倣学習
模倣学習では、専門家や上手な人の行動を記録しておいてそれと近い行動をとるようにエージェントを学習させます。
少ないデータで望ましい行動を短時間で学習させることができる模倣学習はとても重要な学習手法です。
模倣学習には2つの問題があります。
- 状態数が多い場合、上手な人の行動をとりきるのが困難になる。
- 行動を記録するのが難しい状態がある。
模倣学習の方法として次の4つがあります。
1.Forward Training
各タイムステップの個別戦略を作っておいてそれをつなぎ合わせて全体戦略とします。
単純な教師あり学習より実際の状態遷移分布に近いデータで各戦略を学習させることができます。
2.SMILe
複数の戦略を混合していく手法です。
最初の戦略は上手な人の行動だけから学習し、その後は学習した戦略を混ぜていきます。
3.DAgger
戦略ではなくデータを混ぜ合わせていき、そこから学習して戦略を作成していきます。
具体的には各ステップで得られた状態とその状態における上手な人の行動のペアを学習データに足していきます。
4.GAIL
上手な人の模倣を見破られないようにする手法です。
模倣する側と模倣を見破る側の2つのモデルが存在し、一方は模倣を行いもう一方は鑑定を行う設定で学習を行います。(敵対的学習)
探索の概要
探索
現在の状態を開始点として、数手先をどう展開するかを先読みし、展開先の状態を評価します。
その状態評価をもとに現在の状態での最良の一手を選ぶ手法です。
探索では状態の展開を表すのにゲーム木でモデル化します。
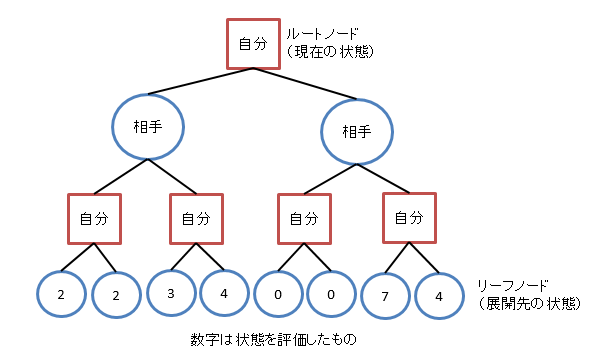
完全ゲーム木
ゲームの開始から選択できるすべての手を含んだゲーム木です。
これがあれば絶対に負けない戦略を立てることができますが、完全ゲーム木のノード数は膨大なため計算が不可能なことがほとんどです。
部分ゲーム木
現在の状態から時間内に探索できる分だけを含んだゲーム木です。
有効だと思われるノードは深く探索し、有効でないノードは途中で探索を打ち切ります。
強さはいかに効率が高い部分ゲーム木を手に入れられるかということにかかってきます。
ニューロンとニューラルネットワーク
ニューロン
ニューロンは人間の脳内にある神経細胞のことです。
深層学習でのニューロンは、人間脳内の神経細胞を模したものです。
このニューロンは重みパラメータと閾値(バイアス)を持っています。
- 重みパラメータ
ニューロン同士のつながりの強さを表します。 - 閾値(バイアス)
脳細胞の感度のようなものになります。
入力信号と重みパラメータを掛け合わせたものが閾値を超えた時に次のニューロンへ信号を送ります。(発火)
深層強化学習が行われることで、上記2つのパラメータが調整されていきます。
ニューラルネットワーク
ニューロンを複数並べたものを層といいます。
層を積み重ねたものがニューラルネットワークとなります。
- 入力層
最初にある層で入力を受け付けます。
入力データの数がニューロン数となります。 - 出力層
最後にある層で出力を行います。
出力する数(答えの数)がニューロン数となります。 - 隠れ層
入力層と出力層の間にある層です。
複数作成することが可能で、4層以上のニューラルネットワークがディープニューラルネットワークと呼ばれます。(入力層×1、隠れ層×2、出力層×1)
コンピュータの能力向上や、インターネットの広がりで学習データが容易に収集できるようになり深層強化学習は広く普及しました。
深層学習 ニューラルネットワークで回帰
ニューラルネットワークで数値データの予測を行う推定モデルを作成します。
住宅情報から価格を予測します。
まずは必要なパッケージをインポートします。
1 | # パッケージのインポート |
データセットの準備を行います。
各データの内容は次の通りです。
| 変数名 | 内容 |
|---|---|
| train_data | 訓練データの配列 |
| train_labels | 訓練ラベルの配列 |
| test_data | テストデータの配列 |
| test_labels | テストラベルの配列 |
1 | # データセットの準備 |

データセットのシェイプを確認します。
1 | # データセットのシェイプの確認 |

訓練データと訓練ラベルは404件、テストデータとテストラベルは102件です。
データの13は住宅情報の種類数です。
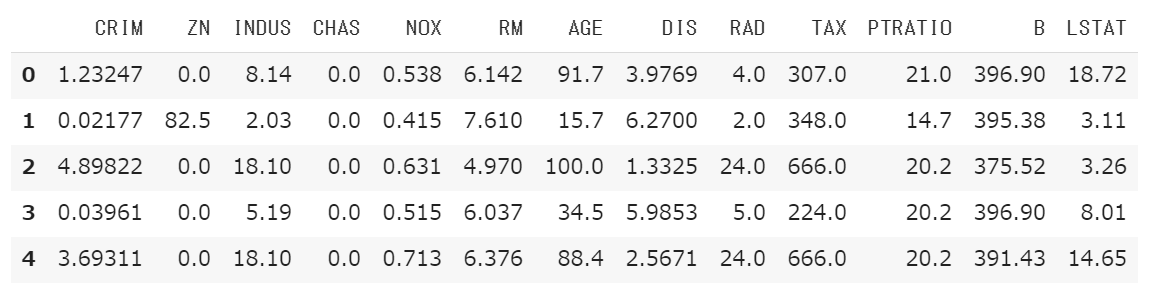
訓練データの先頭10件を表示します。
1 | # データセットのデータの確認 |
訓練ラベルの先頭10件を表示します。
1 | # データセットのラベルの確認 |
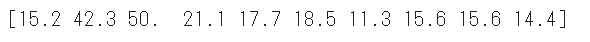
学習前の準備として、訓練データと訓練ラベルをシャッフルします。
似たデータを連続して学習すると偏りが生じてしまうのを防ぐためです。
1 | # データセットのシャッフルの前処理 |
訓練データとテストデータの正規化を行います。
データを一定の方法で変換し同じ単位で比較しやすくするためです。
具体的には平均0、分散1で正規化を行います。
1 | # データセットの正規化の前処理 |
データセットのデータが平均0、分散1になっていることを確認します。
1 | # データセットの前処理後のデータの確認 |

モデルを作成します。今回は全結合層を3つ重ねた簡単なモデルとなります。
1 | # モデルの作成 |
ニューラルネットワークモデルのコンパイルを行います。
- 損失関数 mse
平均二乗誤差 Mean Squared Error - 実際の値と予測値との誤差の二乗を平均したものです。
0に近いほど予測精度が高いことになります。 - 最適化関数 Adam
lrは学習率です。 - 評価指標 mae
平均絶対誤差 Mean Absolute Error - 実際の値と予測値との絶対値を平均したものです。
0に近いほど予測精度が高いことになります。
1 | # コンパイル |
EarlyStoppingの準備を行います。
任意のエポック数改善がないと学習を停止します。
1 | # EarlyStoppingの準備 |
学習を行います。callbacksにEarlyStoppingを指定しています。
1 | # 学習 |
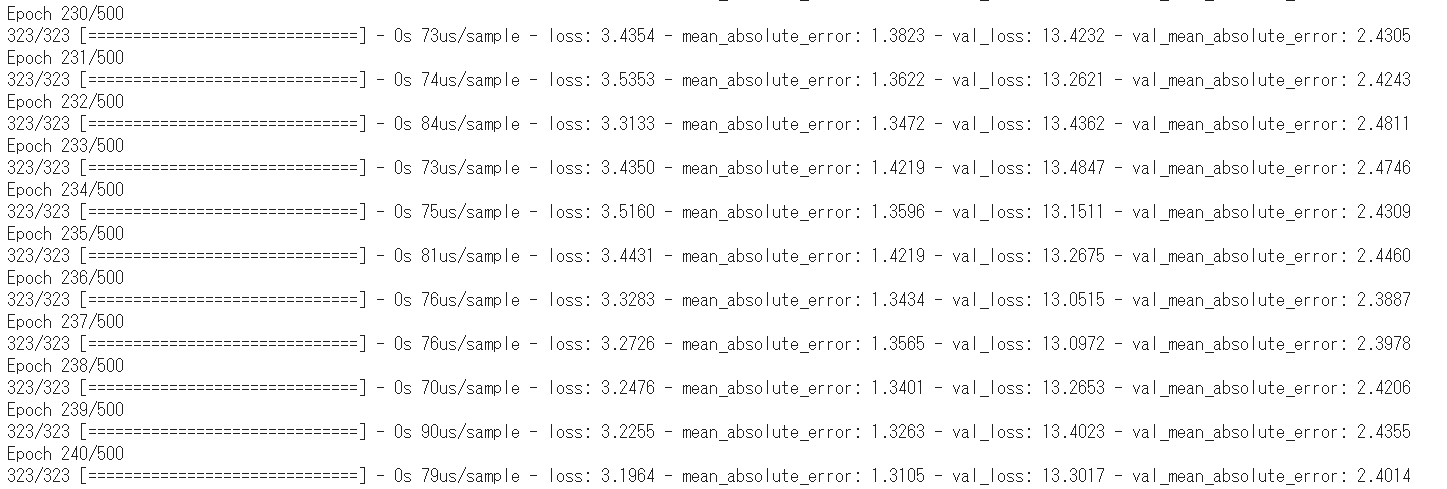
学習中に出力される情報の意味は次の通りです。
| 情報 | 説明 |
|---|---|
| loss | 訓練データの誤差です。0に近いほどよい結果となります。 |
| mean_absolute_error | 訓練データの平均絶対誤差です。0に近いほどよい結果となります。 |
| val_loss | 検証データの誤差です。0に近いほどよい結果となります。 |
| val_mean_absolute_error | 検証データの平均絶対誤差です。0に近いほどよい結果となります。 |
上記のデータうち、訓練データの平均絶対誤差(mae)と検証データの平均絶対誤差(val_mae)をグラフ表示します。
1 | # グラフの表示 |
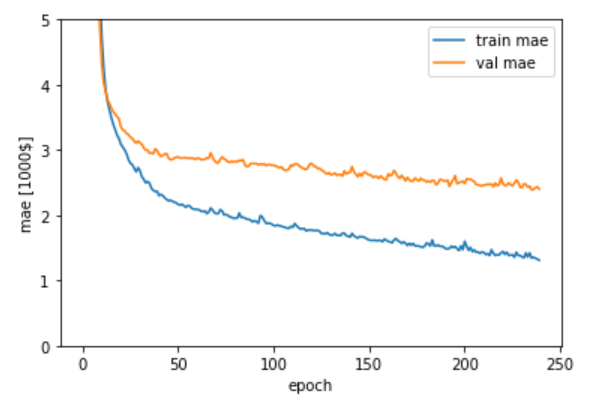
テストデータとテストラベルを推定モデルに渡して評価を行い、平均絶対誤差を算出します。
1 | # 評価 |

平均絶対誤差は2.655となりました。
テストデータの先頭10件の推論を行い、予測結果を出力します。
1 | # 推論する値段の表示 |

実際の価格に近い価格が推論されているような気がします。
(Google Colaboratoryで動作確認しています。)
参考
AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門 サポートページ
深層学習 ニューラルネットワークで分類
手書き数字を分類するためにニューラルネットワークを作成し、実際の数字を推論するモデルを作ります。
まずは必要なパッケージをインポートします。
1 | # パッケージのインポート |
データセットの準備を行います。
各データの内容は次の通りです。
| 変数名 | 内容 |
|---|---|
| train_images | 訓練画像の配列 |
| train_labels | 訓練ラベルの配列 |
| test_images | テスト画像の配列 |
| test_labels | テストラベルの配列 |
1 | # データセットの準備 |

データセットのシェイプを確認します。
1 | # データセットのシェイプの確認 |

訓練画像データは60000×画像サイズ(28×28)です。
訓練ラベルデータは60000の1次元配列となります。
データセットの画像を確認するために先頭の10件を表示します。
1 | # データセットの画像の確認 |

データセットのラベルを確認するために先頭の10件を表示します。
1 | # データセットのラベルの確認 |
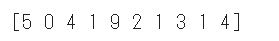
学習を開始する事前準備として、データセットをニューラルネットワークに適した形に変換します。
具体的には、画像データを28×28の2次元配列から1次元配列(786)に変換します。
1 | # データセットの画像の前処理 |

ラベルデータに関しても、ニューラルネットワークに適した形に変換します。
具体的にはone-hot表現に変えます。
one-hot表現とは、ある1要素が1でほかの要素が0である配列です。
ラベルが8の場合は[0, 0, 0, 0, 0, 0, 0, 0, 1, 0]という配列になります。
1 | # データセットのラベルの前処理 |

ニューラルネットワークのモデルを作成します。
入力層のシェイプは画像データに合わせて786で、出力層はラベルデータに合わせて10とします。
ユニット数と隠れ層の数は自由に決められますが今回はユニット数256と隠れ層128としました。
層とユニット数を増やすと複雑な特徴をとらえることができるようになる半面、学習時間が多くかかるようになってしまいます。
またユニット数が多くなると重要性の低い特徴を抽出して過学習になってしまう可能性があります。
Dropoutは過学習を防いでモデルの精度をあげるための手法となります。
任意の層のユニットをランダムに無効にして特定ニューロンへの依存を防ぎ汎化性能を上げます。
活性化関数は結合層の後に適用する関数で層からの出力に対して特定の関数を経由し最終的な出力値を決めます。活性化関数を使用することで線形分離不可能なデータも分類することができるようになります。
1 | # モデルの作成 |
ニューラルネットワークのモデルをコンパイルします。
- 損失関数 [loss]
モデルの予測値と正解データの誤差を計算する関数です。 - 最適化関数 [optimizer]
損失関数の結果が0に近づくように重みパラメータとバイアスを最適化する関数です。 - 評価指標 [metrics]
モデル性能を測定するための指標です。測定結果は、学習を行うfit()の戻り値に格納されます。
1 | # コンパイル |
訓練画像と訓練モデルを使って学習を実行します。
1 | # 学習 |

学習中に出力される情報の意味は次の通りです。
| 情報 | 説明 |
|---|---|
| loss | 訓練データの誤差です。0に近いほどよい結果となります。 |
| acc | 訓練データの正解率です。1に近いほどよい結果となります。 |
| val_loss | 検証データの誤差です。0に近いほどよい結果となります。 |
| val_acc | 検証データの正解率です。1に近いほどよい結果となります。 |
上記のデータうち、訓練データの正解率(acc)と検証データの正解率(val_acc)をグラフ表示します。
1 | # グラフの表示 |
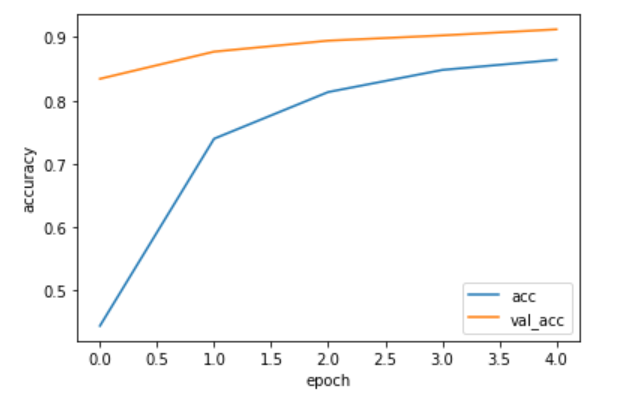
テスト画像とテストラベルをモデルに渡して評価を行います。
1 | # 評価 |

正解率は91.0%となりました。
先頭10件のテスト画像の推論を行い、画像データと予測結果を合わせて表示します。
1 | # 推論する画像の表示 |
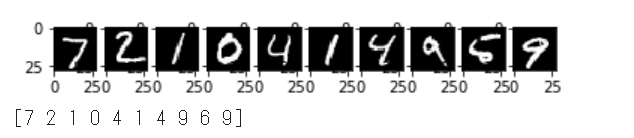
90%の正解率であることが確認できます。
(Google Colaboratoryで動作確認しています。)
参考
AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門 サポートページ