価値を再帰的かつ期待値で表現する手法をBellman Equationと呼びます。(Valueベース)
まず価値を返す関数を定義します。
1 2 3 def V (s, gamma=0.99 ): V = R(s) + gamma * max_V_on_next_state(s) return V
報酬関数を定義します。
1 2 3 4 5 6 7 def R (s ): if s == "happy_end" : return 1 elif s == "bad_end" : return -1 else : return 0
全ての行動でV(s)を計算し値が最大になる価値を返します。
upかdownかを繰り返していき5回行動したら終了となります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def max_V_on_next_state (s ): if s in ["happy_end" , "bad_end" ]: return 0 actions = ["up" , "down" ] values = [] for a in actions: transition_probs = transit_func(s, a) v = 0 for next_state in transition_probs: prob = transition_probs[next_state] v += prob * V(next_state) values.append(v) return max (values)
遷移関数を定義します。
引数sには”state”や”state_up_up”、”state_down_down”などが受け渡されます。
引数aは”up”か”down”が設定されます。
エピソード完了時は1要素が返り、途中の場合は2要素が返ります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def transit_func (s, a ): actions = s.split("_" )[1 :] LIMIT_GAME_COUNT = 5 HAPPY_END_BORDER = 4 MOVE_PROB = 0.9 def next_state (state, action ): return "_" .join([state, action]) if len (actions) == LIMIT_GAME_COUNT: up_count = sum ([1 if a == "up" else 0 for a in actions]) state = "happy_end" if up_count >= HAPPY_END_BORDER else "bad_end" prob = 1.0 return {state: prob} else : opposite = "up" if a == "down" else "down" return { next_state(s, a): MOVE_PROB, next_state(s, opposite): 1 - MOVE_PROB }
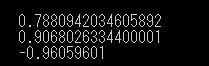
実際に価値V(s)の計算を行ってみます。
1 2 3 4 if __name__ == "__main__" : print (V("state" )) print (V("state_up_up" )) print (V("state_down_down" ))
upの数が多い方が評価されます。
参考
Pythonで学ぶ強化学習 -入門から実践まで- サンプルコード