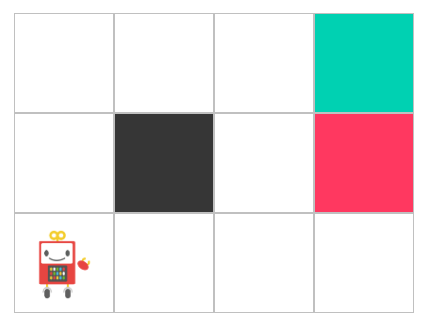
def__init__(self, grid, move_prob=0.8): # grid is 2d-array. Its values are treated as an attribute. # Kinds of attribute is following. # 0: ordinary cell # -1: damage cell (game end) # 1: reward cell (game end) # 9: block cell (can't locate agent) self.grid = grid self.agent_state = State()
# Default reward is minus. Just like a poison swamp. # It means the agent has to reach the goal fast! self.default_reward = -0.04
# Agent can move to a selected direction in move_prob. # It means the agent will move different direction # in (1 - move_prob). self.move_prob = move_prob self.reset()
@property defstates(self): states = [] for row inrange(self.row_length): for column inrange(self.column_length): # Block cells are not included to the state. ifself.grid[row][column] != 9: states.append(State(row, column)) return states
# Check whether a state is out of the grid. ifnot (0 <= next_state.row < self.row_length): next_state = state ifnot (0 <= next_state.column < self.column_length): next_state = state
# Check whether the agent bumped a block cell. ifself.grid[next_state.row][next_state.column] == 9: next_state = state
# Check an attribute of next state. attribute = self.grid[state.row][state.column] if attribute == 1: # Get reward! and the game ends. reward = 1 done = True elif attribute == -1: # Get damage! and the game ends. reward = -1 done = True