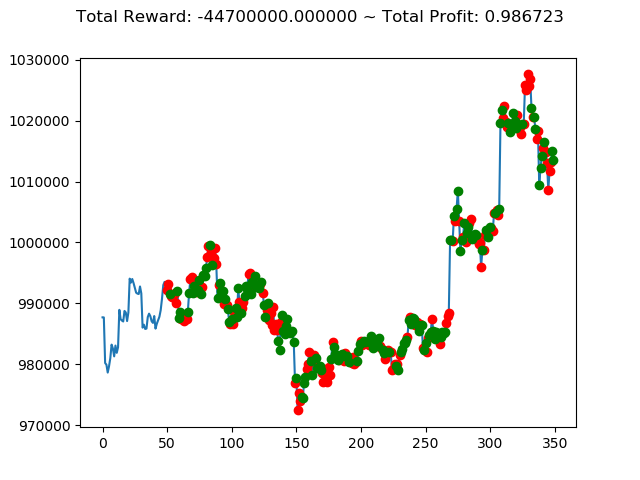
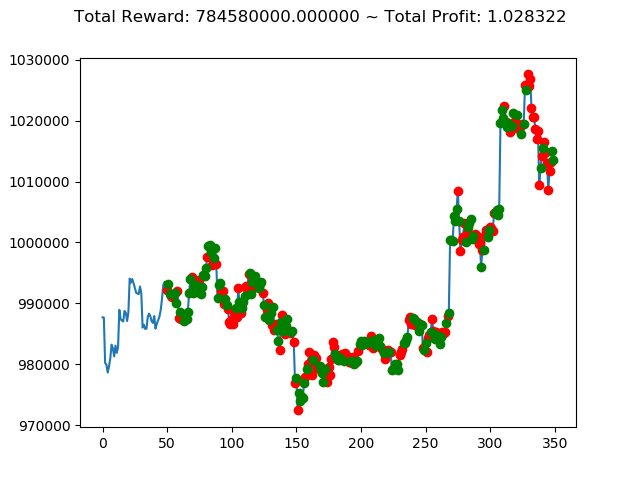
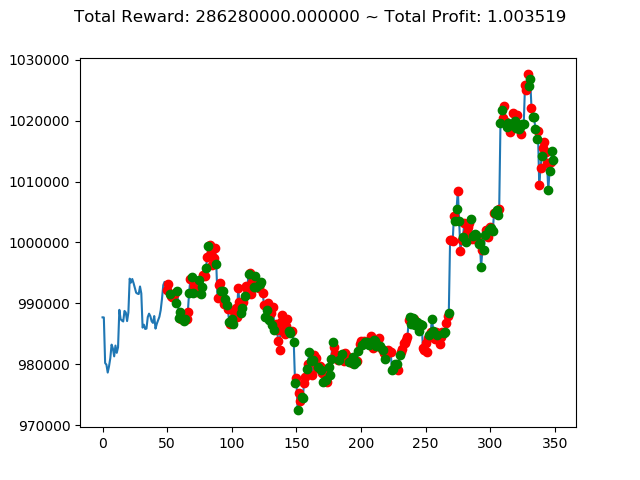
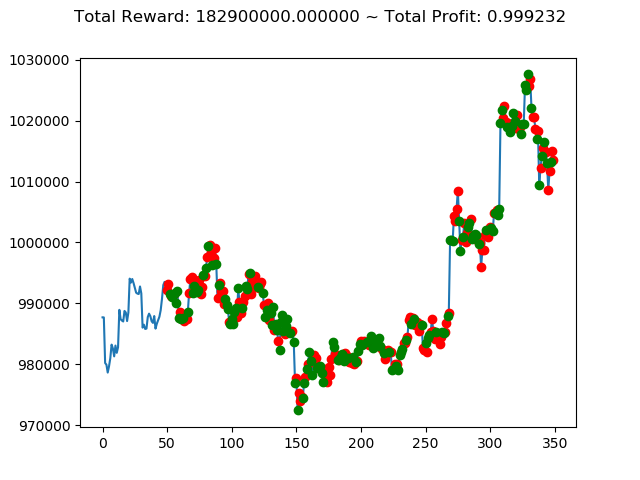
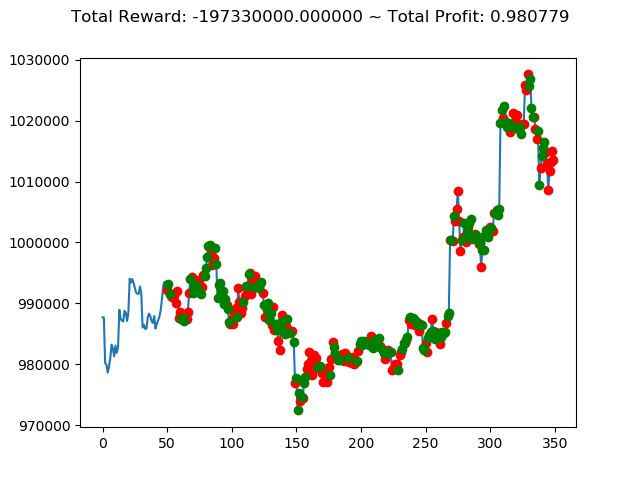
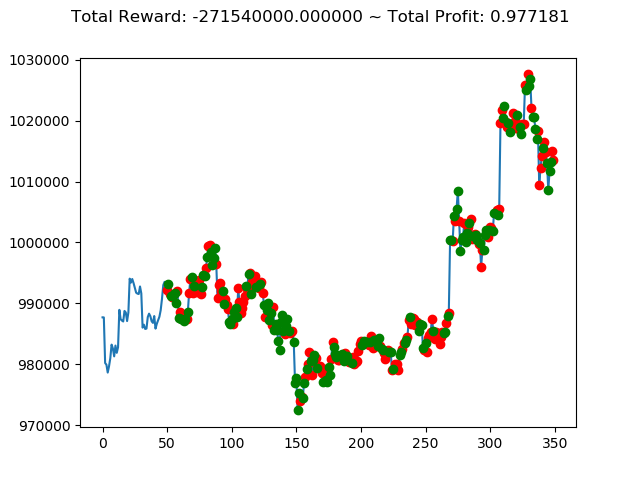
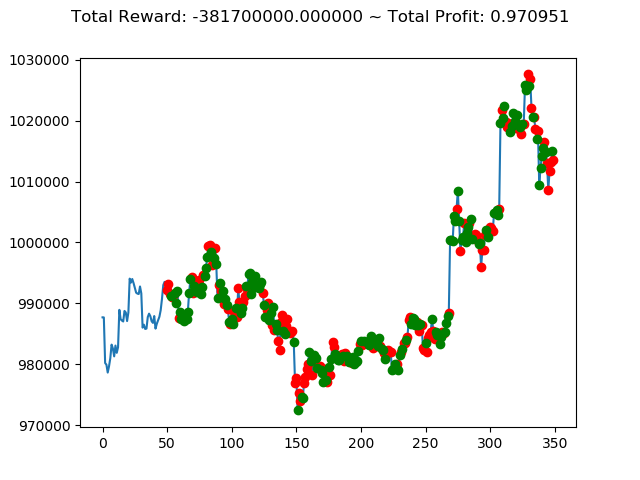
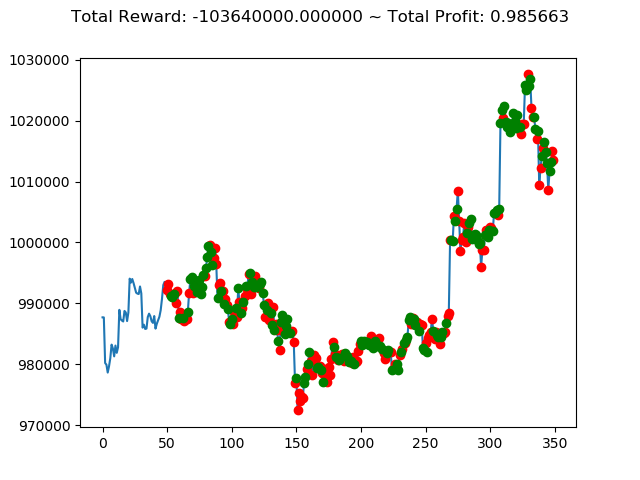
学習済みモデルを使い、期間を変えて検証してみます。
学習済みモデルを使っての投資シミュレーション
今回は学習を行わないので、学習に関するパラメータは不要となります。
検証データは200データ分後ろに移動したものにします。
前前回の処理で、学習済みモデル trading_model0.zip ~ trading_model9.zip が作成されているのでそれを読み込みます。
- 検証データ
[2020-07-20 12:00 ~ 2020-08-02 02:00] 1時間足データ
学習済みモデルを読み込んで、投資シミュレーションを行うコードは次のようになります。
1 | import os, gym |
50行目 で検証データの位置を200データ分後ろに移動しています。
10回投資シミュレーションを実行
上記コードを実行すると次のような結果になりました。
[コンソール出力]
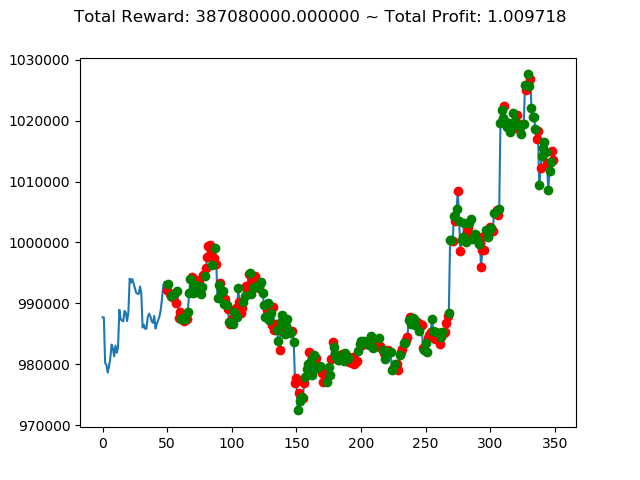
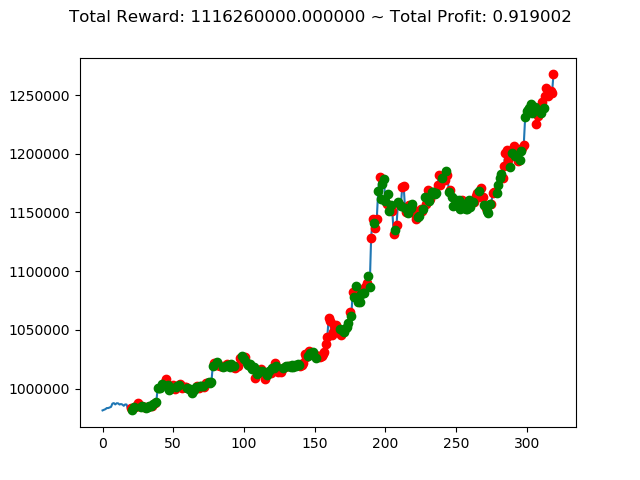
1 | info: {'total_reward': 1116260000.0, 'total_profit': 0.9190015581136497, 'position': 0} |
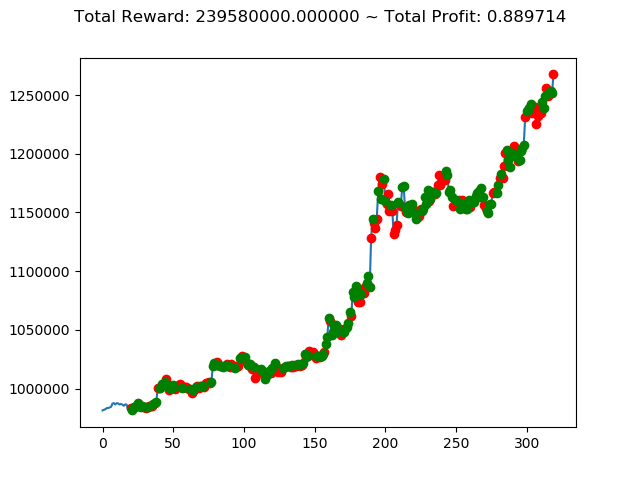
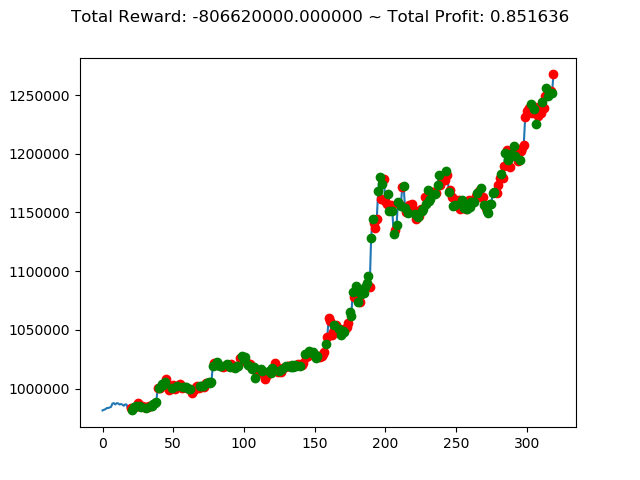
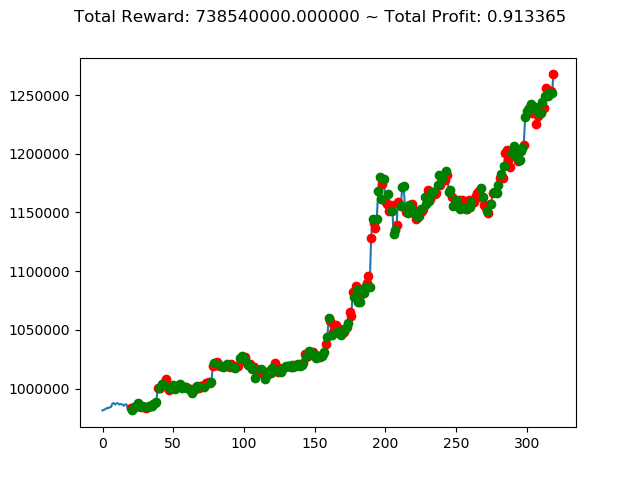
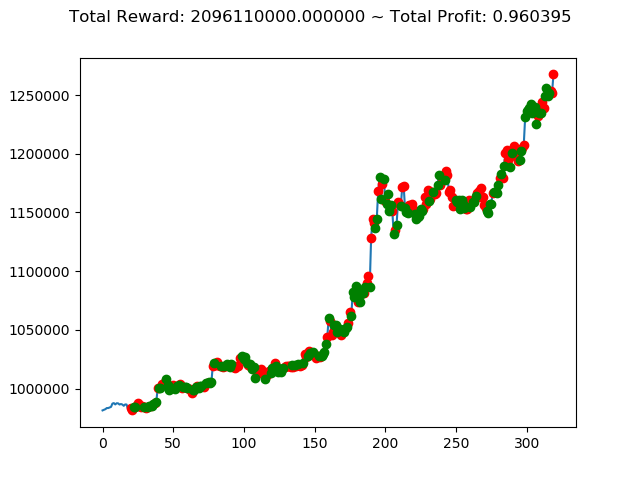
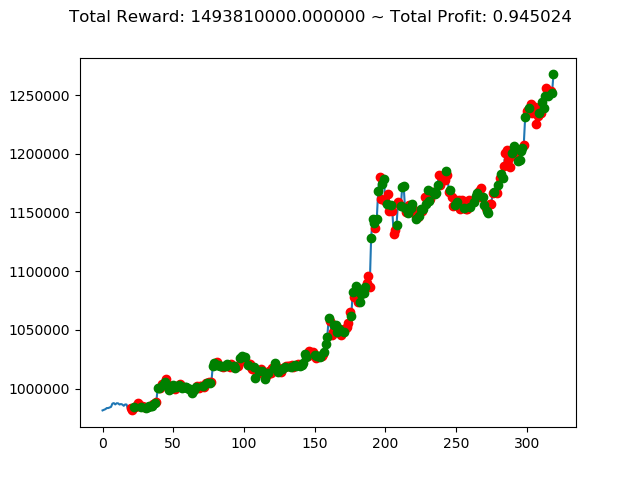
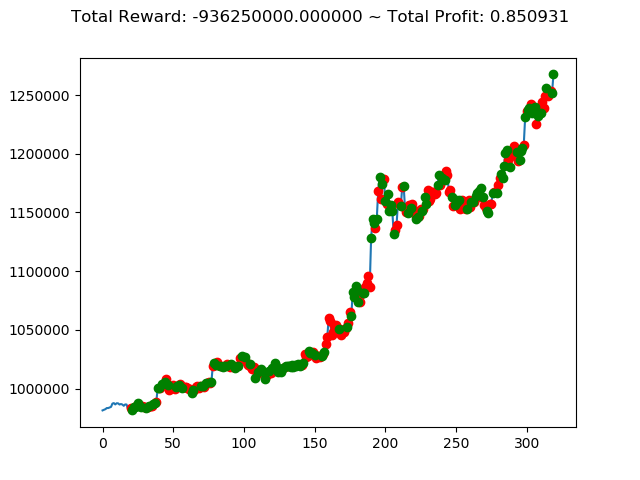
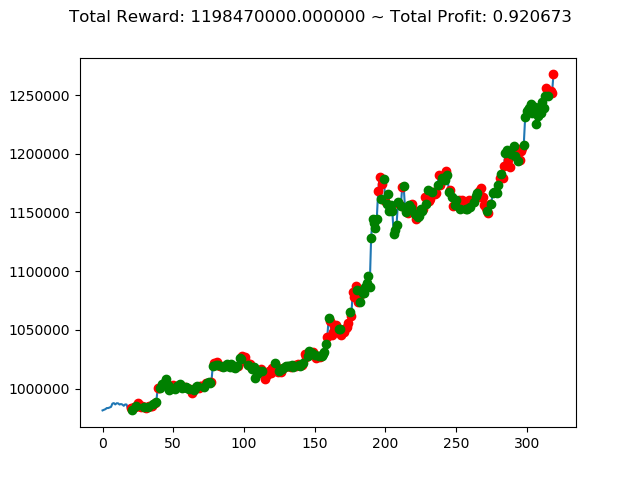
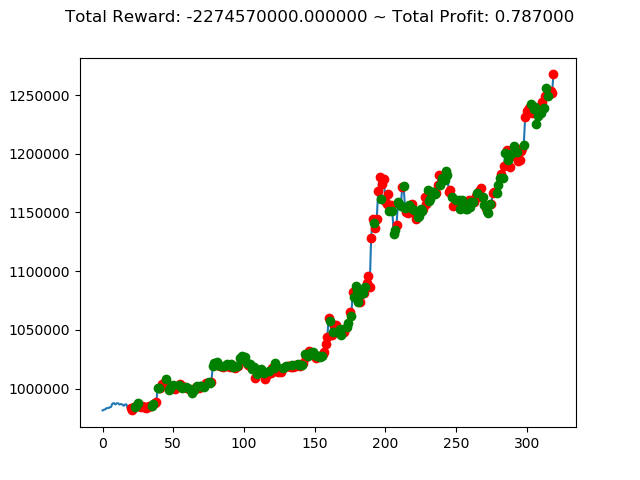
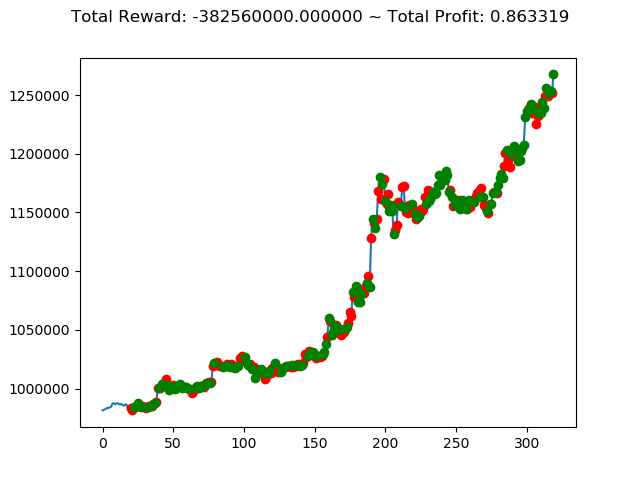
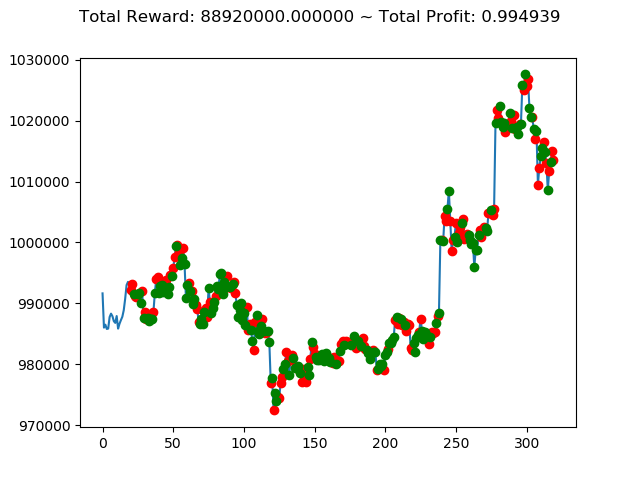
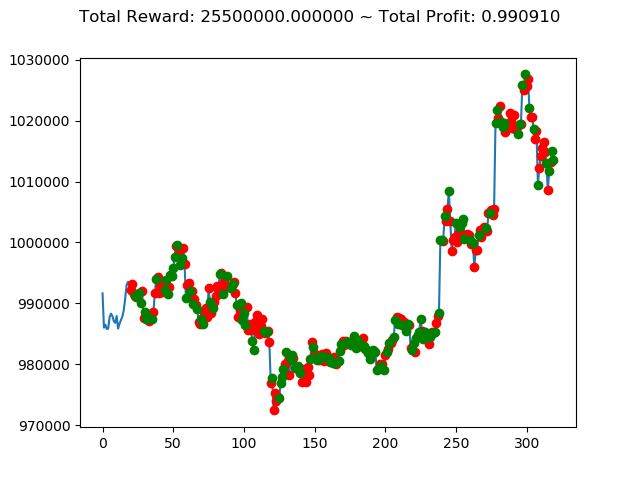
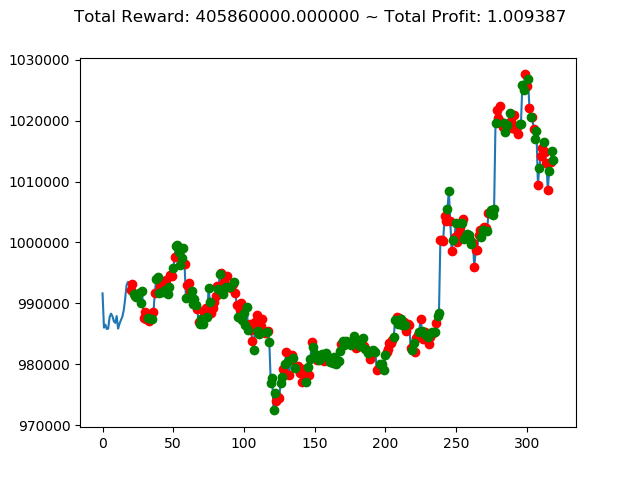
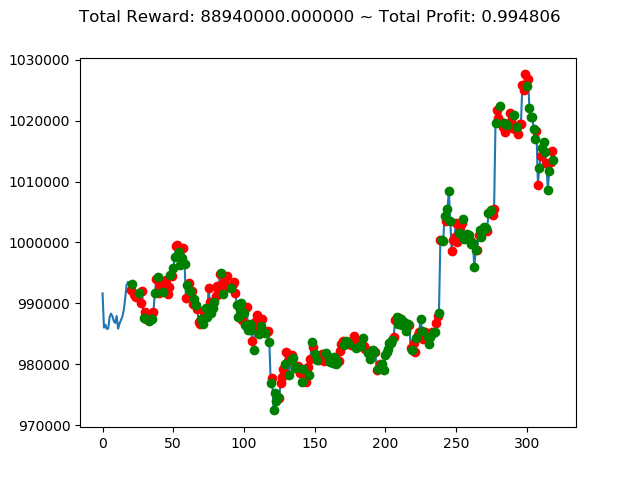
前回の結果(トータル報酬)と今回の結果(トータル報酬)を表にまとめてみます。
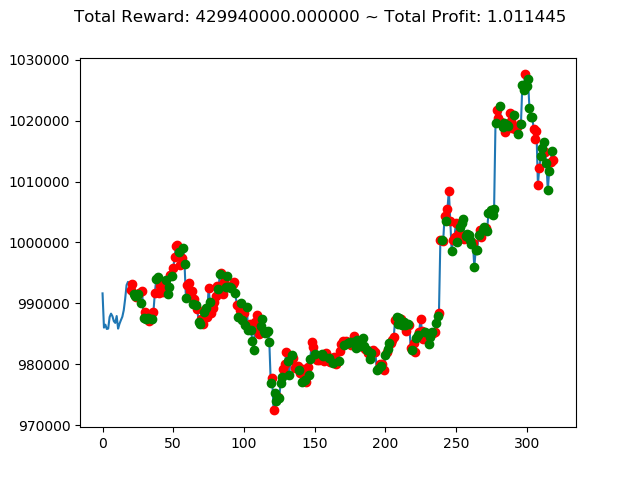
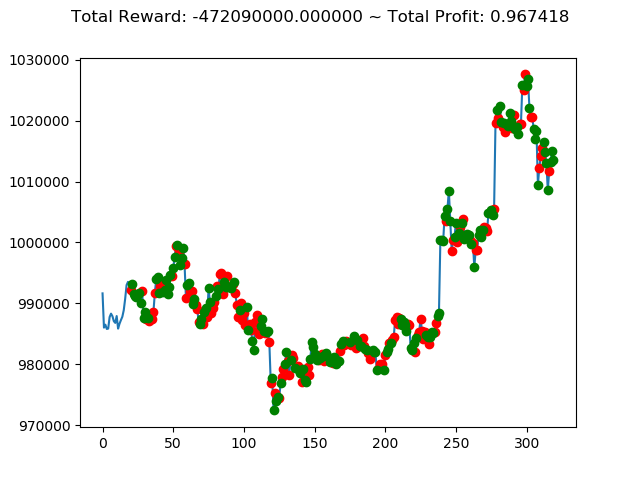
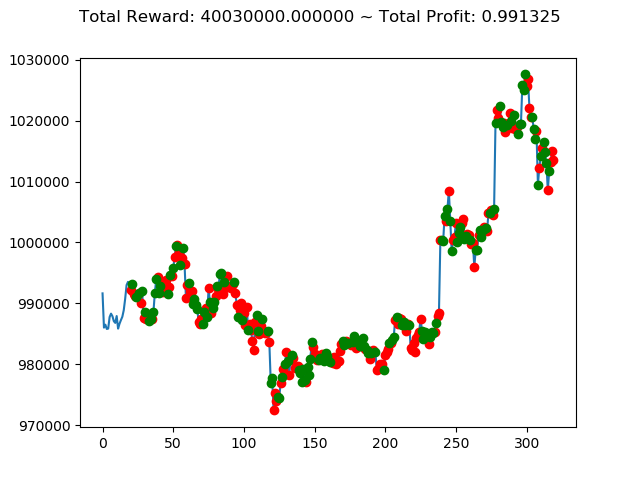
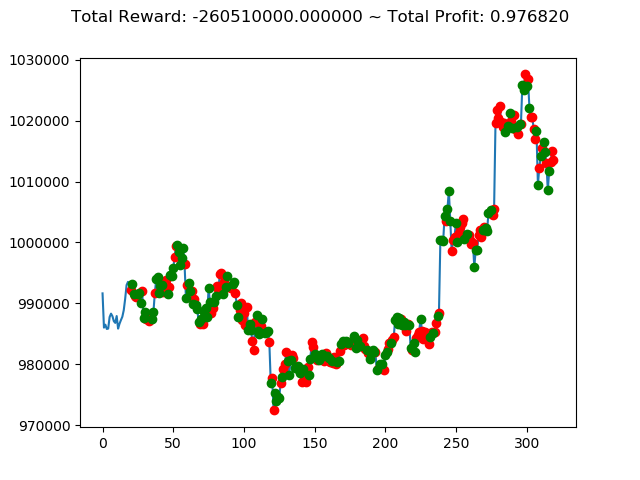
| No. | トータル報酬(前前回) | トータル報酬(前回) | トータル報酬(今回) |
|---|---|---|---|
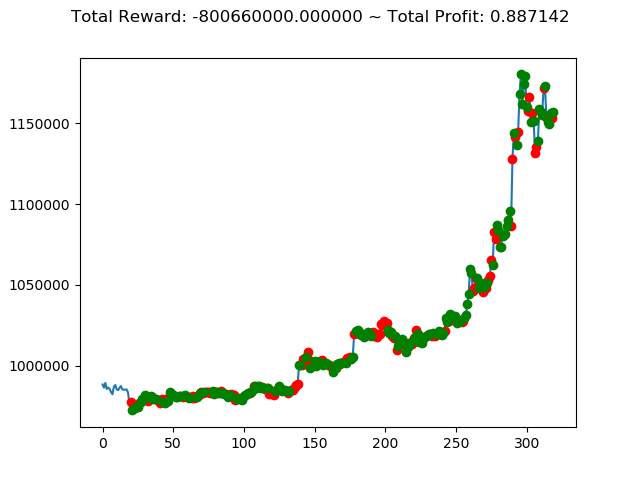
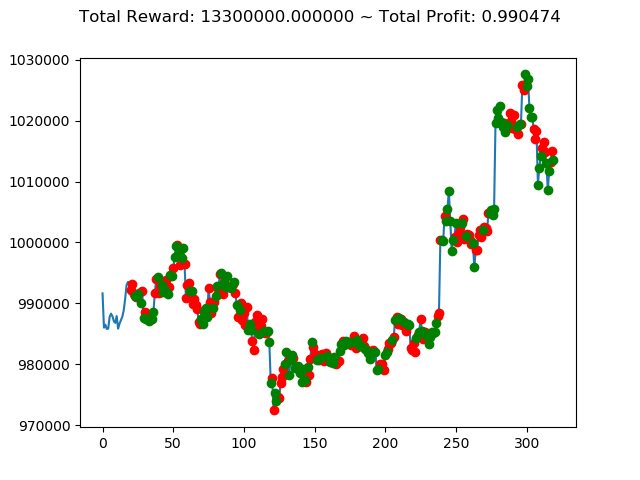
| ① | 13,300,000円 | -800,660,000円 | 1,116,260,000円 |
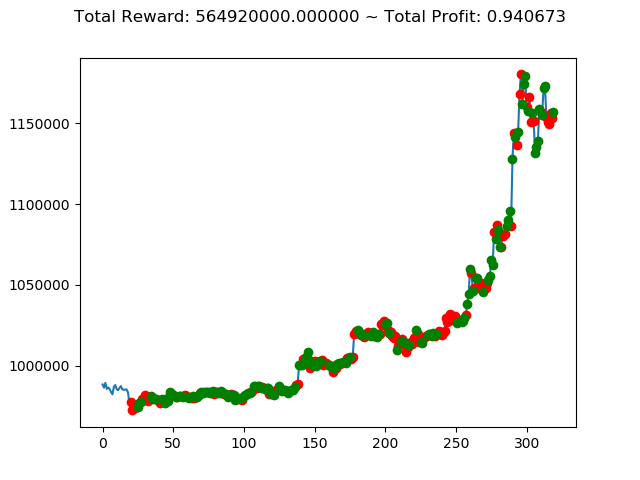
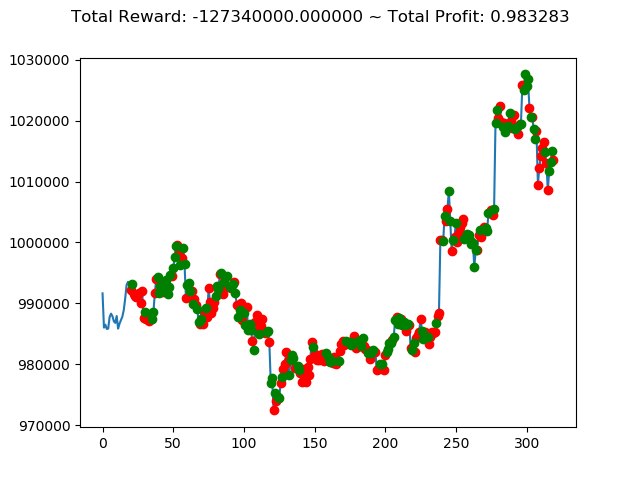
| ② | -127,340,000円 | 564,920,000円 | 239,580,000円 |
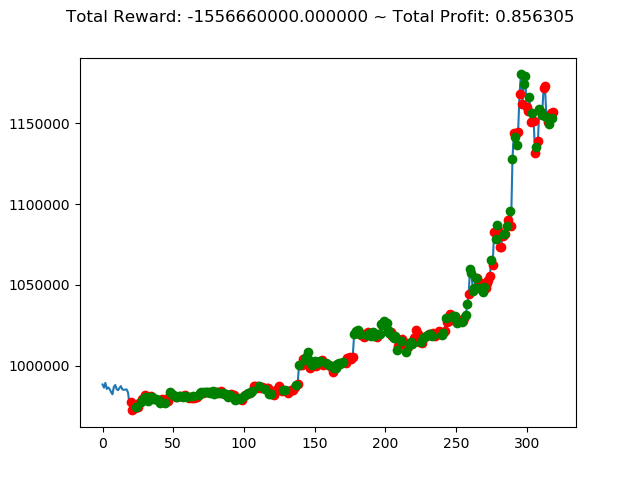
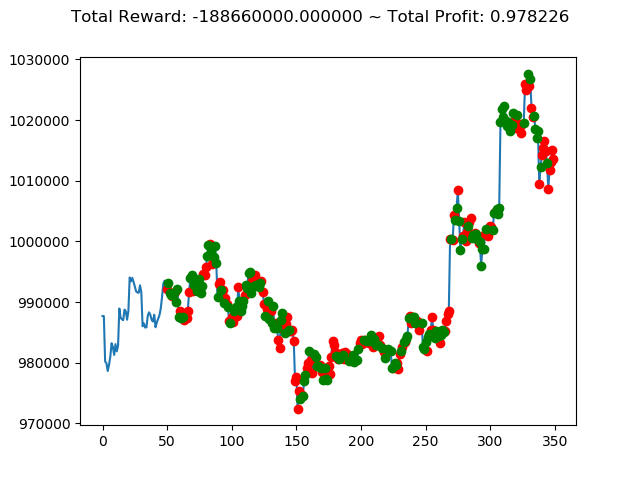
| ③ | 429,940,000円 | -1,556,660,000円 | -806,620,000円 |
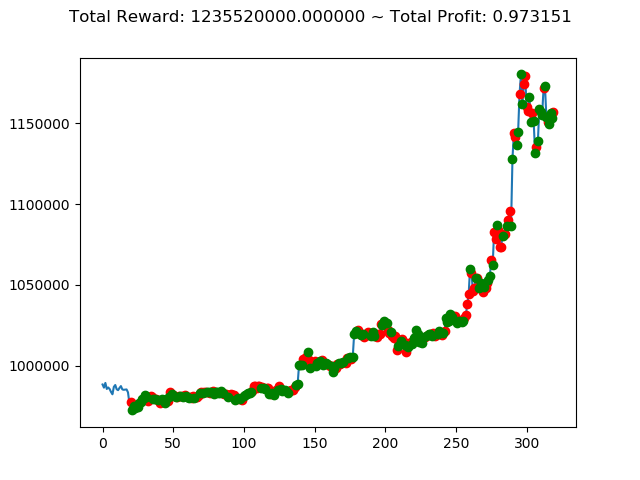
| ④ | -472,090,000円 | 1,235,520,000円 | 738,540,000円 |
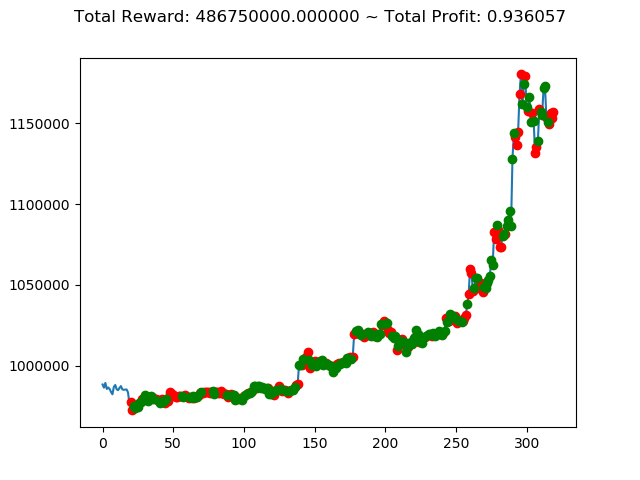
| ⑤ | 40,030,000円 | 486,750,000円 | 2,096,110,000円 |
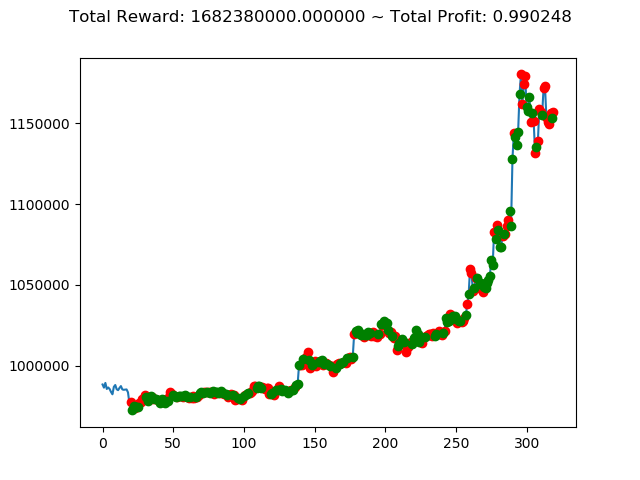
| ⑥ | -260,510,000円 | 1,682,380,000円 | 1,493,810,000円 |
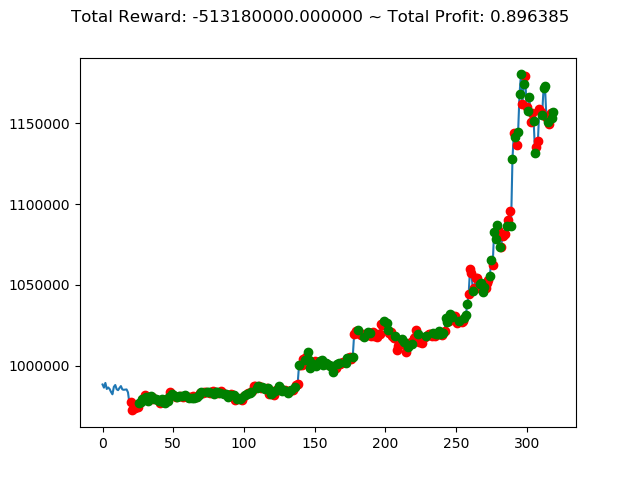
| ⑦ | 88,920,000円 | -513,180,000円 | -936,250,000円 |
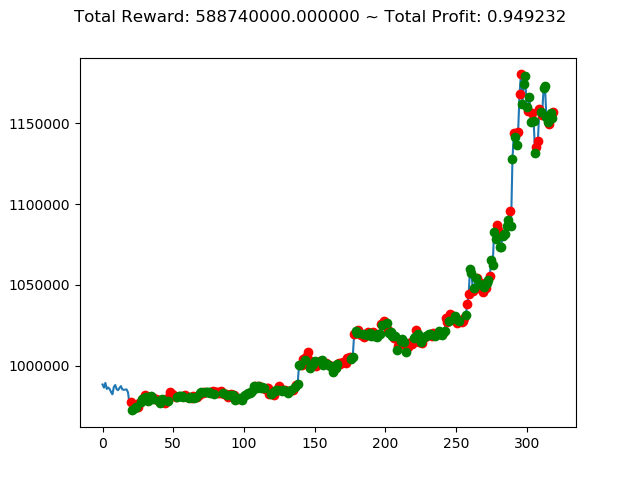
| ⑧ | 25,500,000円 | 588,740,000円 | 1,198,470,000円 |
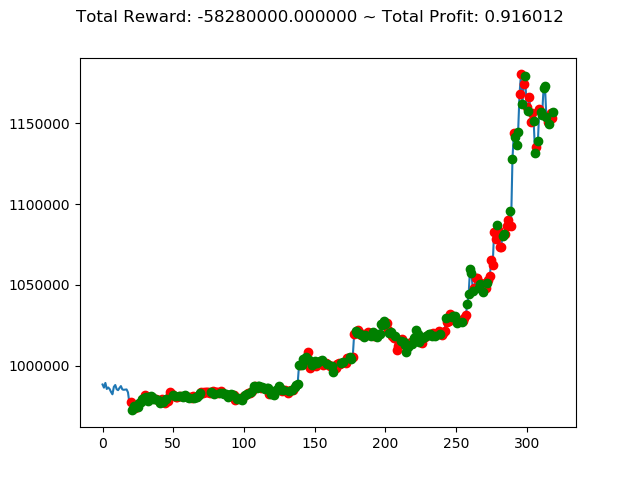
| ⑨ | 405,860,000円 | -58,280,000円 | -2,274,570,000円 |
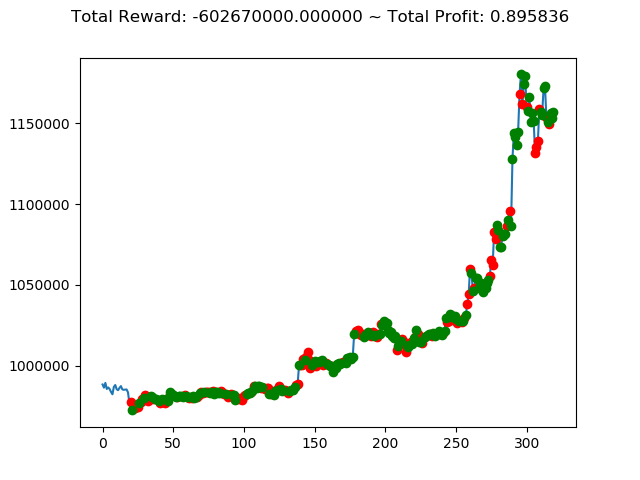
| ⑩ | 88,940,000円 | -602,670,000円 | -382,560,000円 |
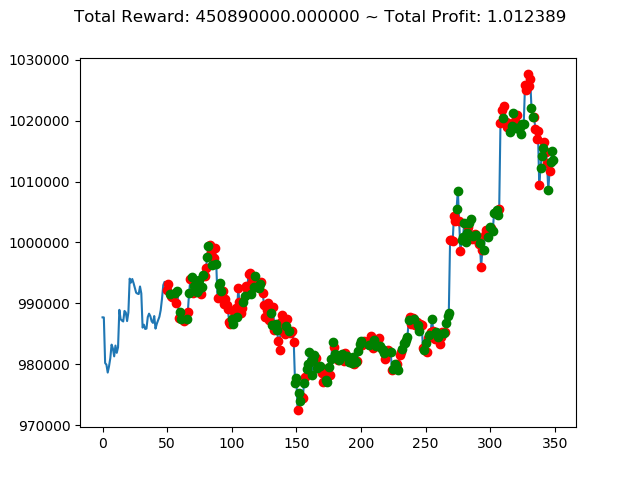
No⑤とNo⑧は3連続でプラス報酬となっています。今後の検証も期待できそうです。
最適な学習済みモデルを作成するために
これまでいろいろな検証を行ってきましたが、次のような手順で好成績を残すことができることが分かりました。
- パラメータを変えつつ、何回も強化学習を行う。
注意すべき点は、同じパラメータと同じ学習データであったとしても、強化学習を実行するたびに学習済みモデルは異なる。(おそらく強化学習の初期値が毎回異なるためだと推測される。) - 学習済みモデルを使って、複数パターンの検証を行い十分な成績を残せる学習済みモデルを選別する。