AnyTradingを実行してきて今更ながら気づいたのですが、実行するたびに結果が変わります。
同じ学習済みモデルを使って同じ検証データを使えば、結果は同じになると思いますが、現状は毎回学習を行っているのでたとえ同じ学習データを使ったとしても学習済みモデルが毎回変わるので、その学習モデルを使った検証結果も変化することに気づきました。
ということで(?)今回は、前回行った強化学習(投資シミュレーション)を、10回実行してその投資結果を確認してみます。
ビットコインデータを使っての投資シミュレーション・・・を10回行う
前回使用したパラメータは以下の通りですが、今回もこの条件で検証していきます。
- 学習アルゴリズム
PPO2 - 参照する直前データ数
50 - 学習データ
[2020-06-29 16:00 ~ 2020-07-24 17:00] 1時間足データ - 検証データ
[2020-07-24 18:00 ~ 2020-07-12 03:00] 1時間足データ
投資シミュレーションを10回行うソースコードは次のようになります。
1 | import os, gym |
毎回結果をチャート表示すると閉じるボタンを押すのが手間なので、表示はせず毎回結果を画像ファイルに保存するように修正しています。(65~66行目)
ビットコインの投資シミュレーションを10回実行
上記コードを実行すると次のような結果になりました。
[コンソール出力]
1 | info: {'total_reward': -44700000.0, 'total_profit': 0.9867232104536462, 'position': 1} |
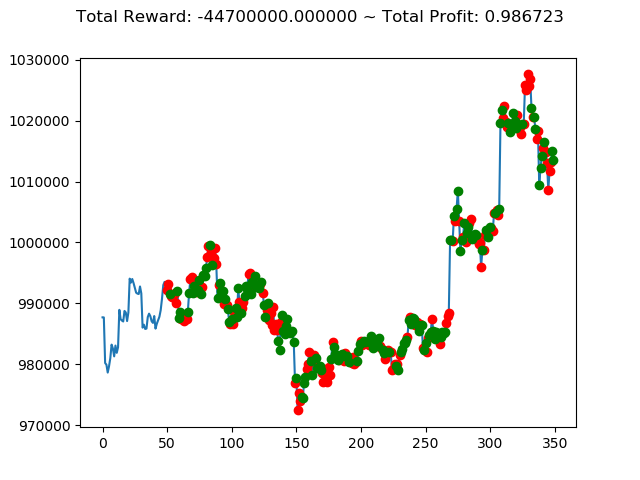
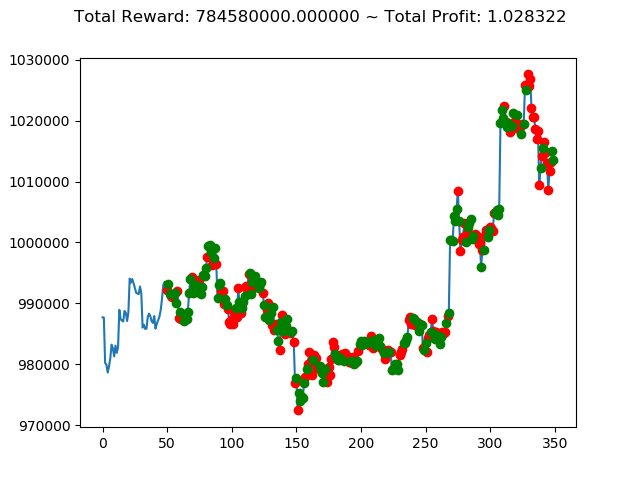
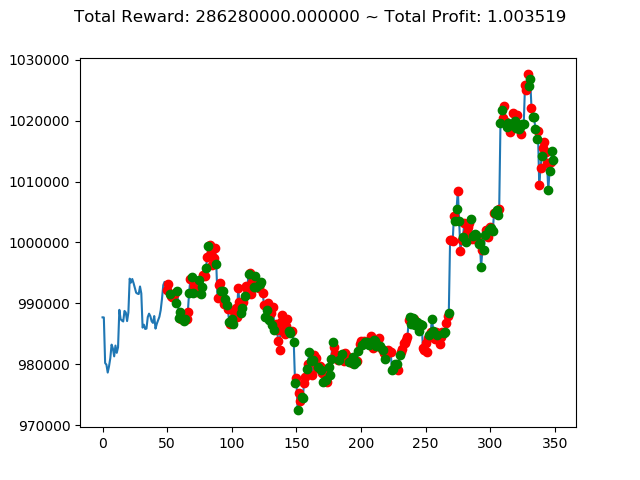
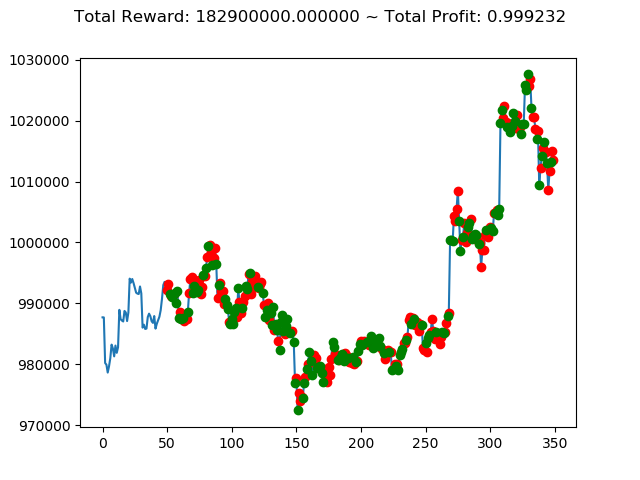
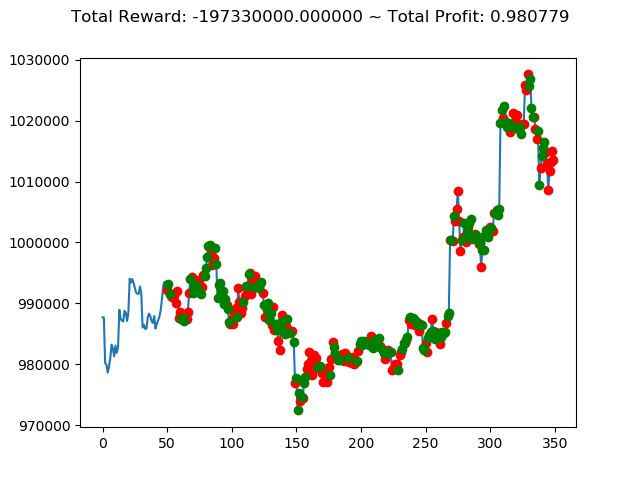
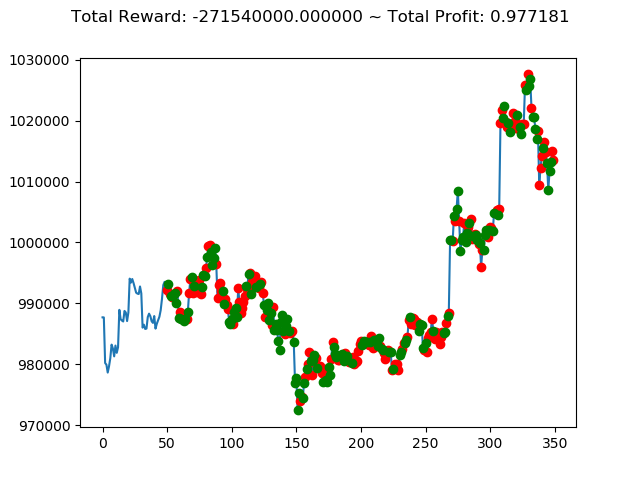
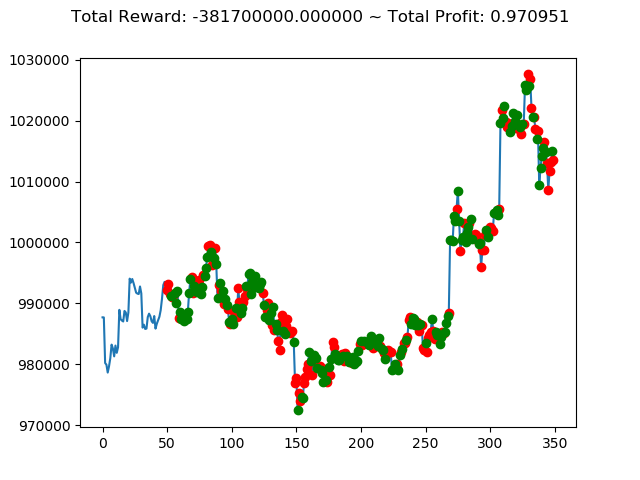
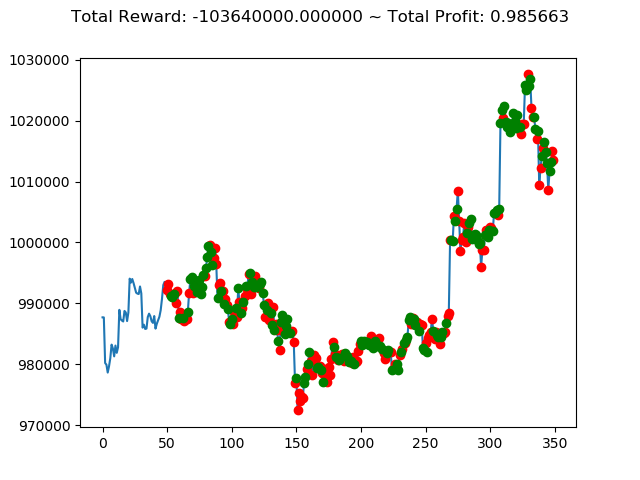
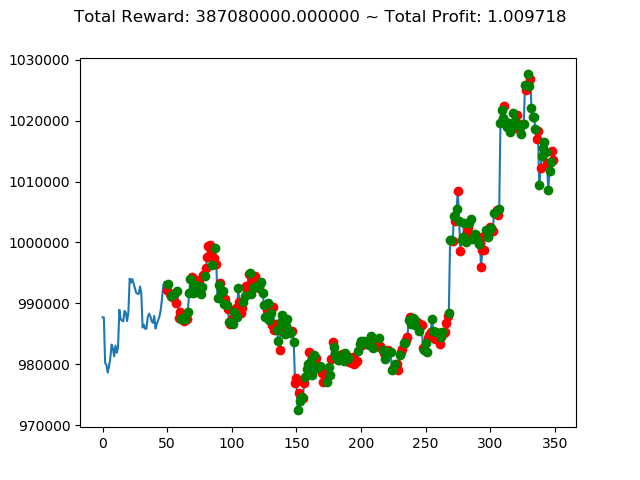
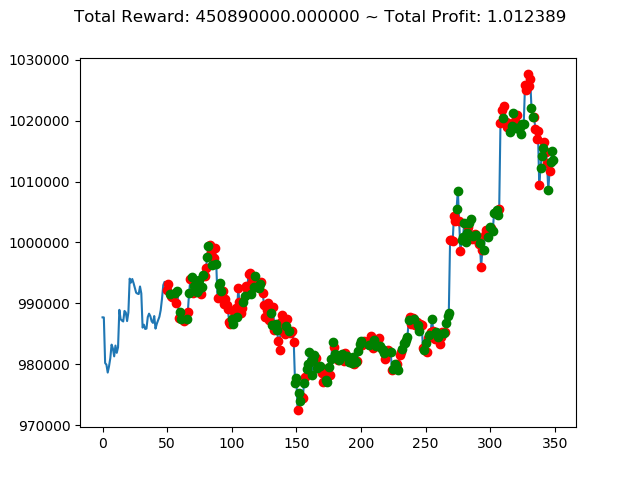
10回の投資結果としては5勝5敗となりました。
ただこの中から成績のいい学習済みモデルを抽出して、他の期間で投資を行ったらどうなるのか・・・・ということを今後検証していこうと思います。