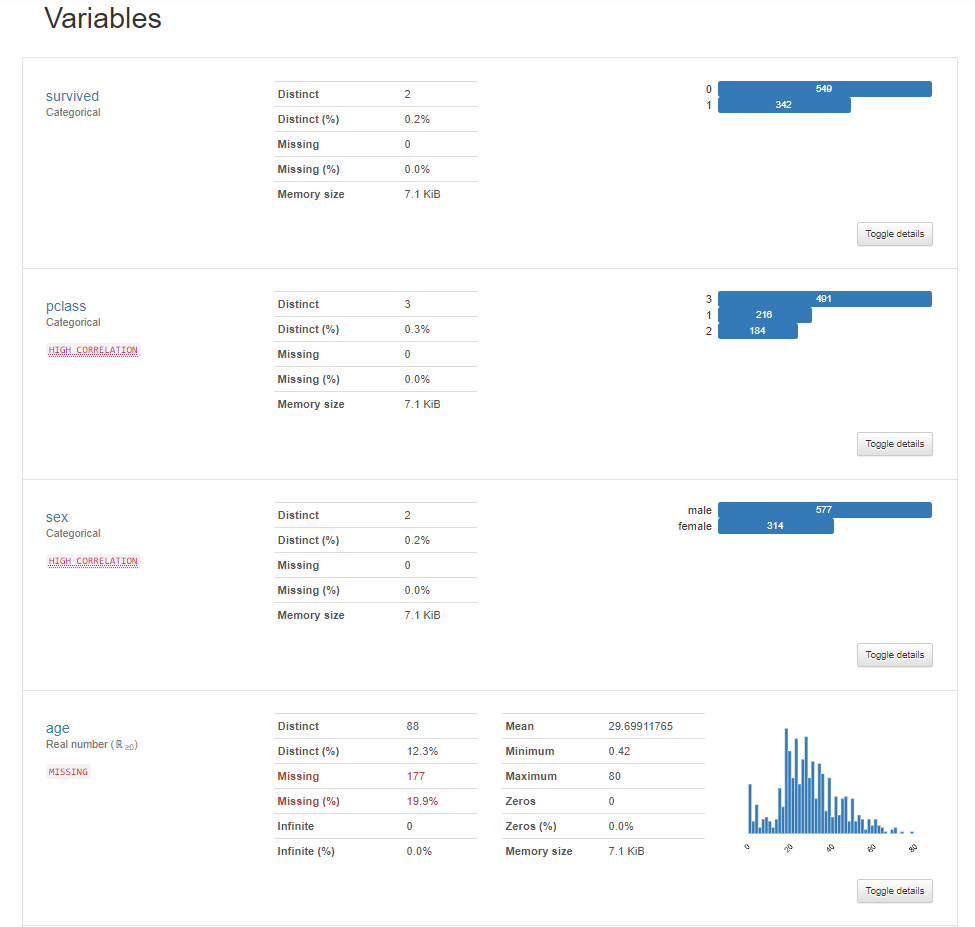
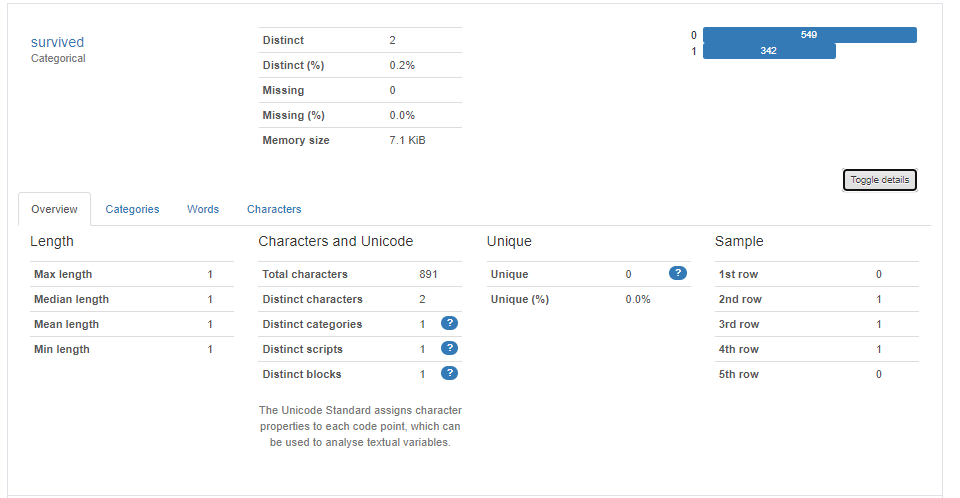
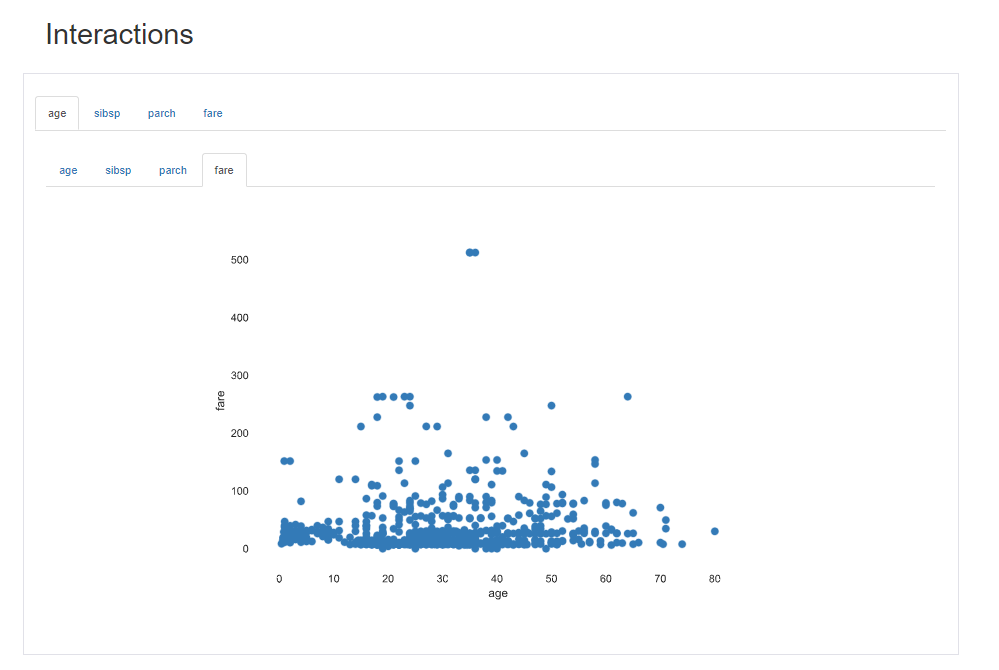
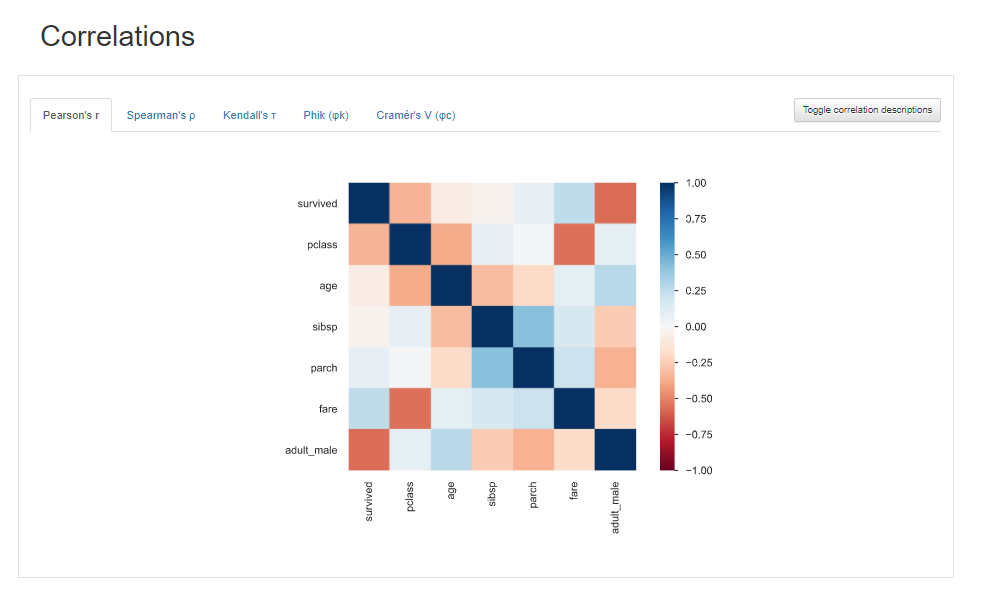
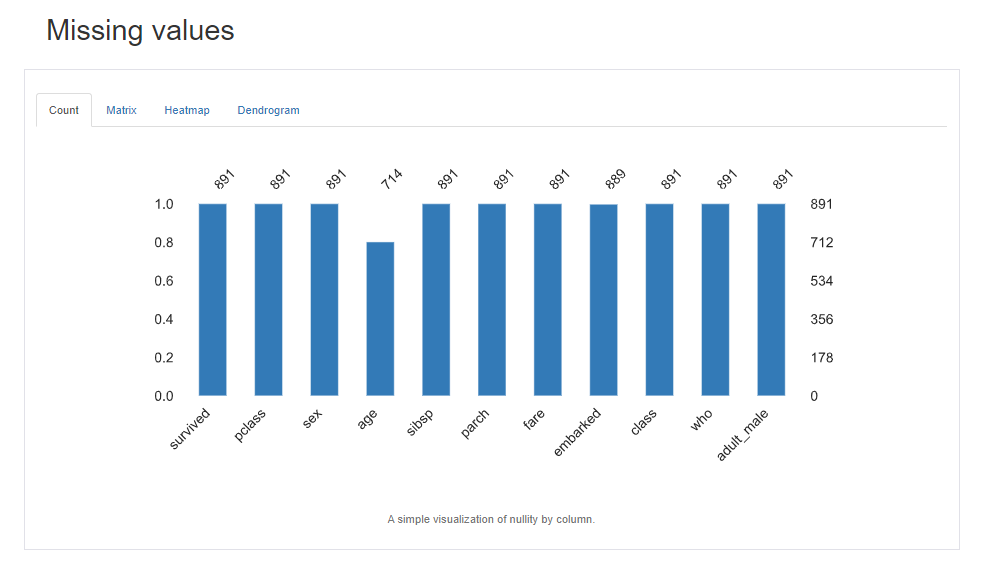
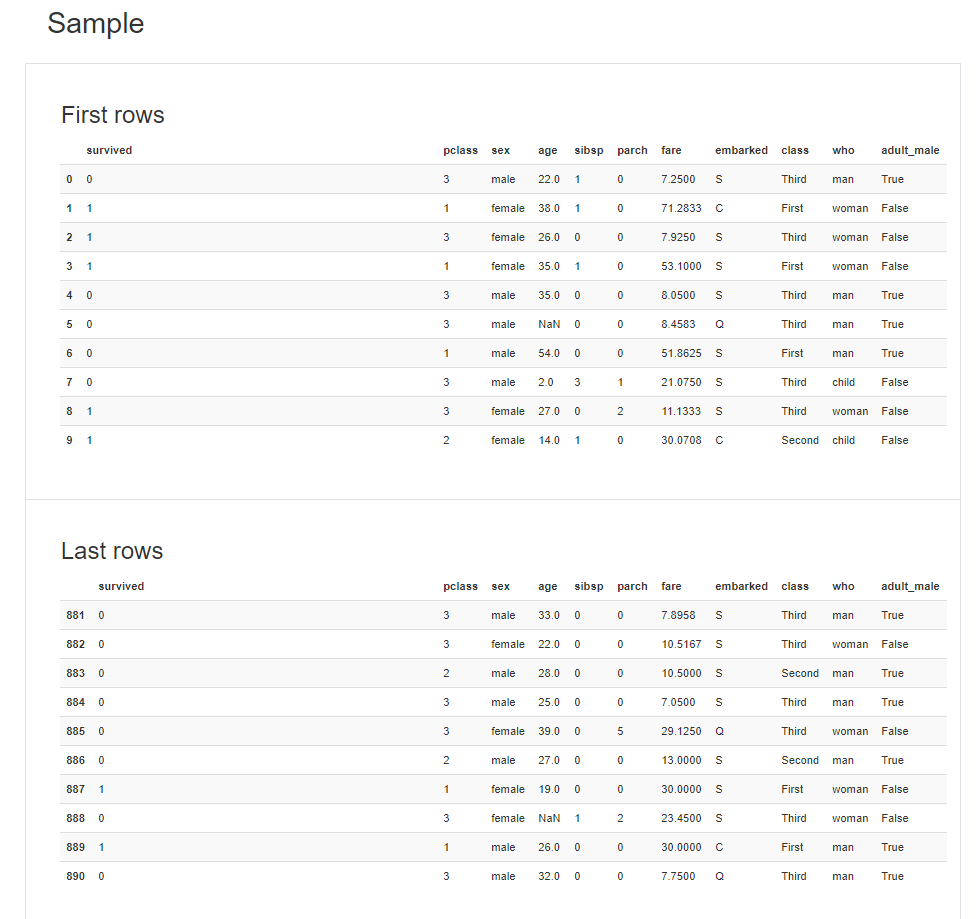
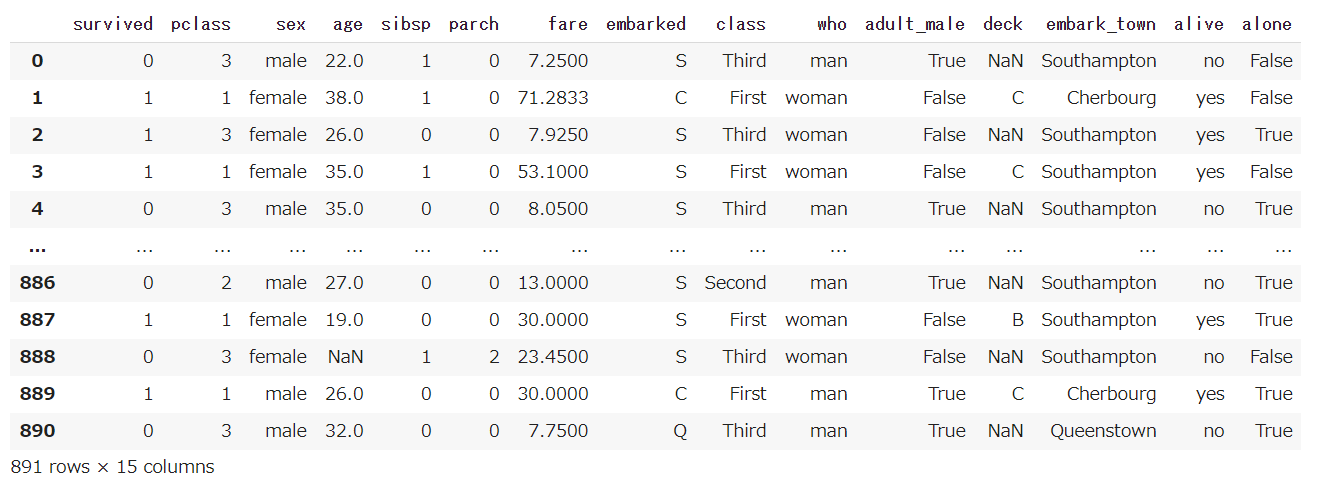
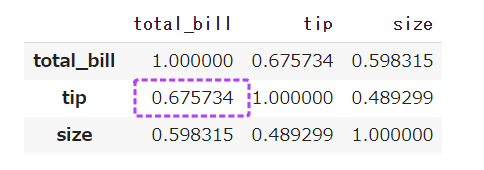
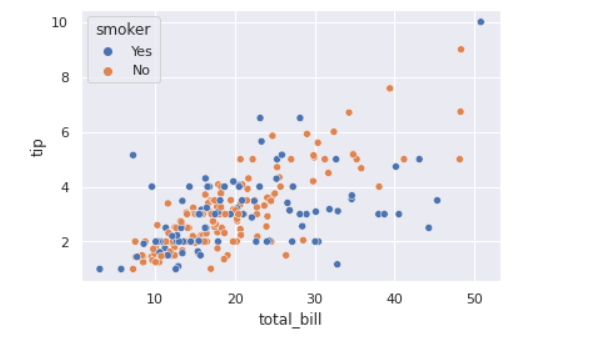
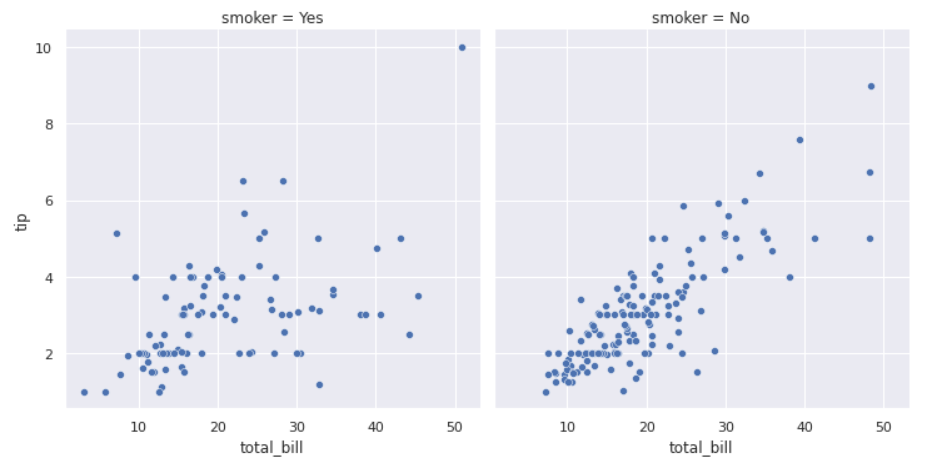
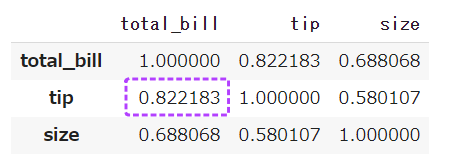
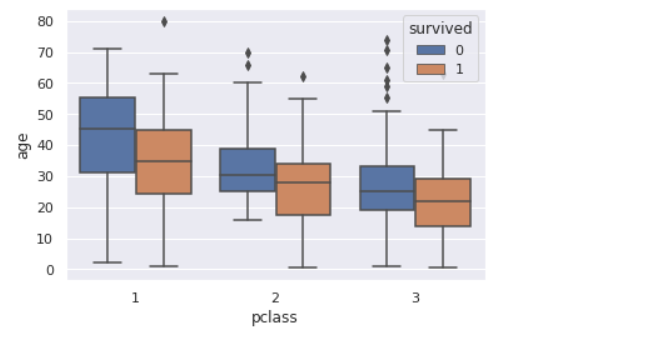
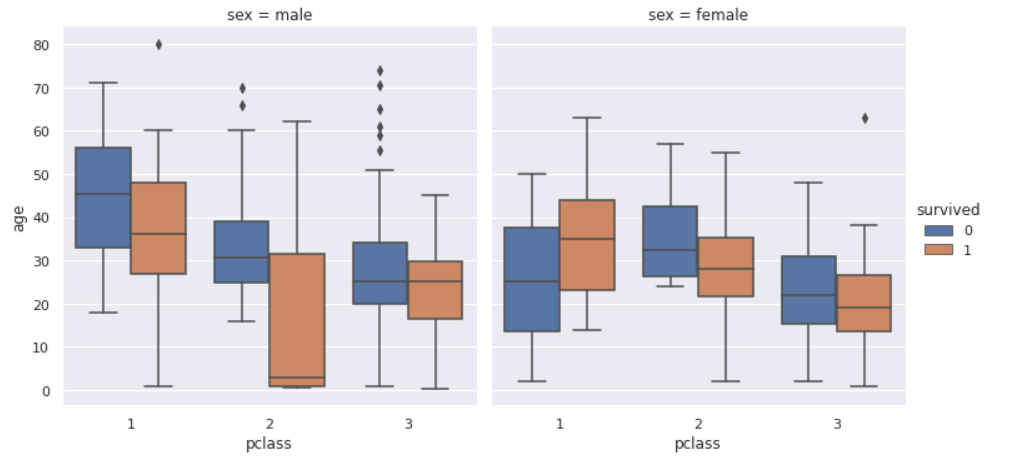
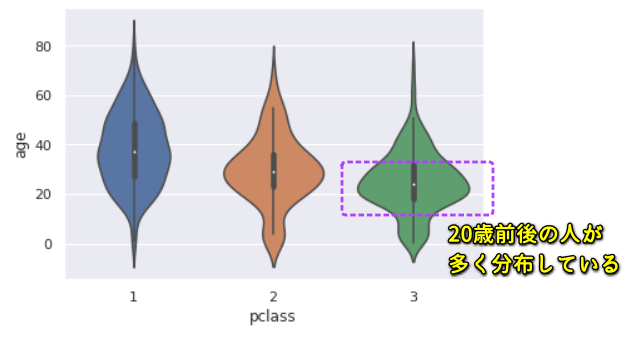
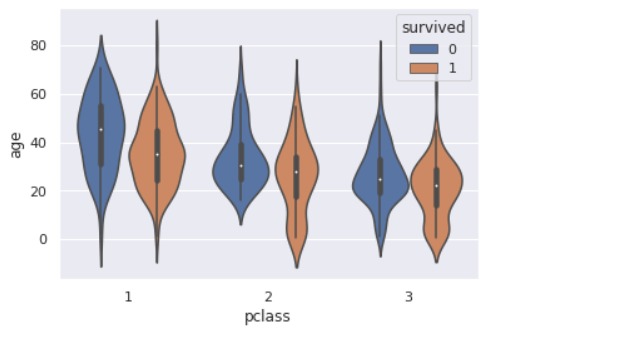
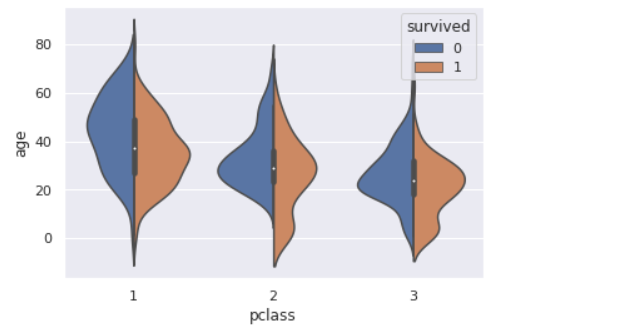
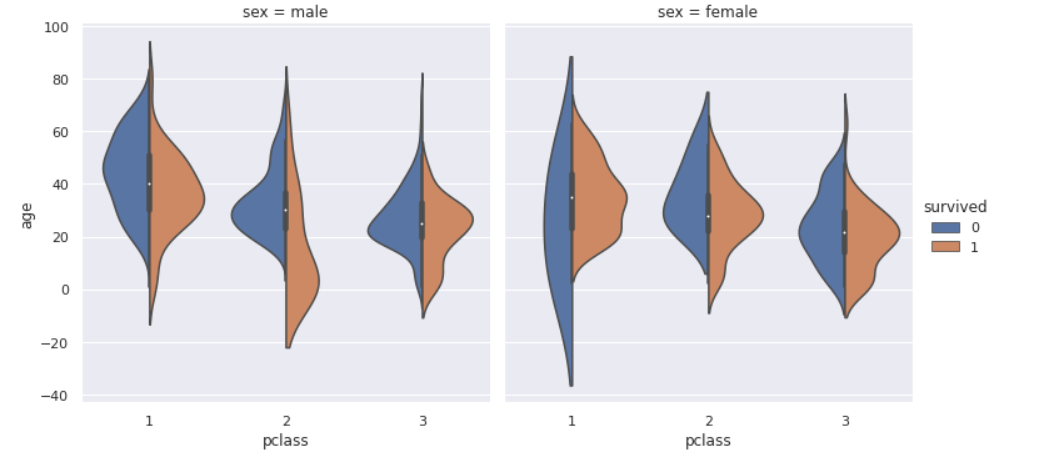
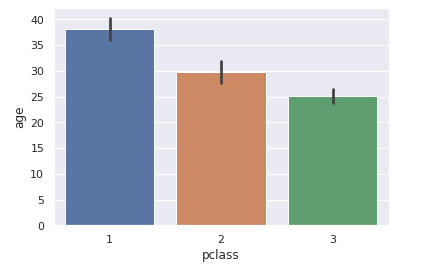
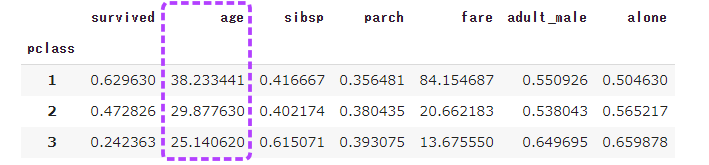
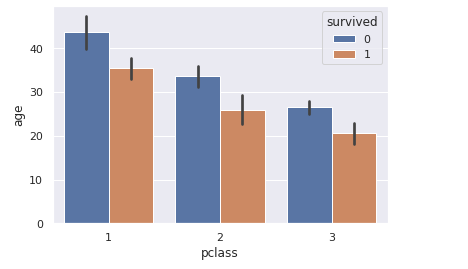
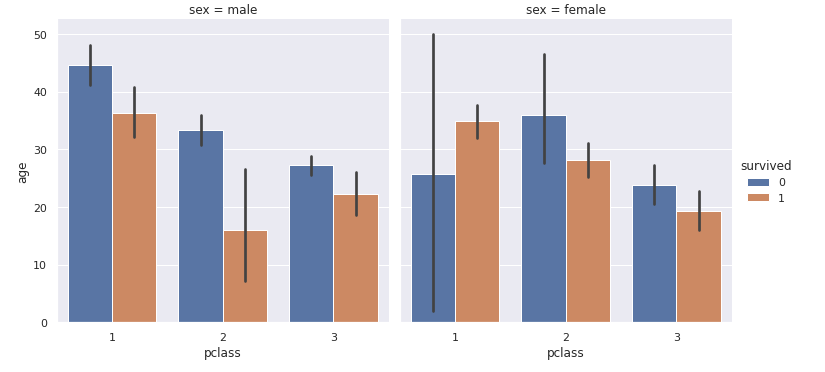
前回記事の3分割交差検証で、正解率90%となかなかの好成績となったので試しにタイタニックコンペに参加してみます。
(KaggleのNotebook環境で実行しています。)
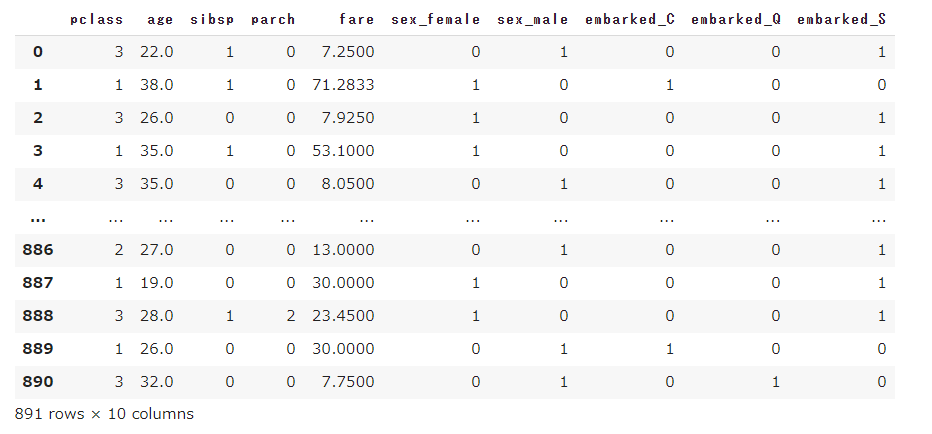
データ読み込み
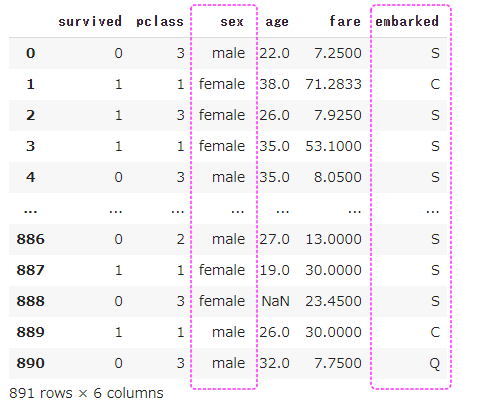
まずは、Kaggleに準備されているタイタニックの訓練データを読み込みます。
[ソース]
1 | import numpy as np |
[出力結果]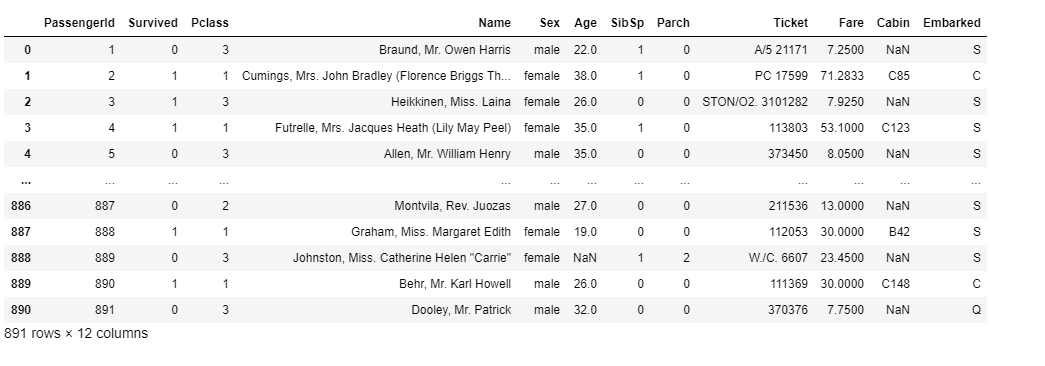
前処理
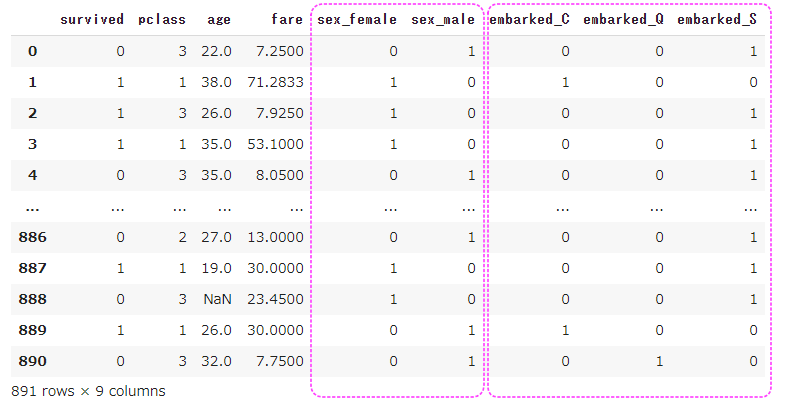
前処理として、不要列の削除・カテゴリ変数の変換を行います。
(LightGBMでは欠損値処理が不要とのことなので、今回欠損値処理は行いませんでした。)
[ソース]
1 | # 不要な列の削除 |
[出力結果]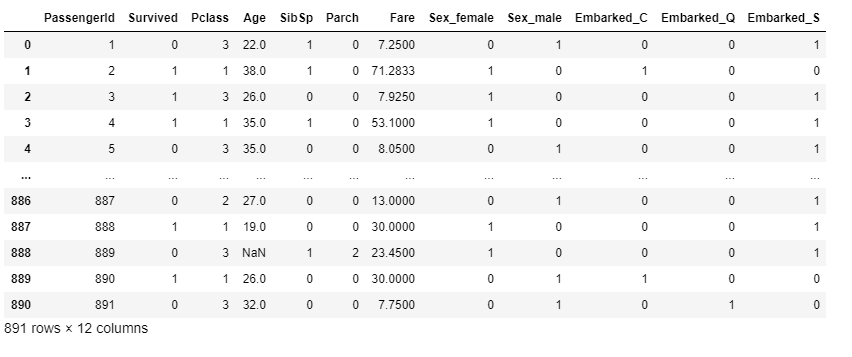
訓練データを、生存(正解ラベル)とそれ以外に分割しておきます。
[ソース]
1 | x_titanic = df_train.drop(['Survived'], axis=1) |
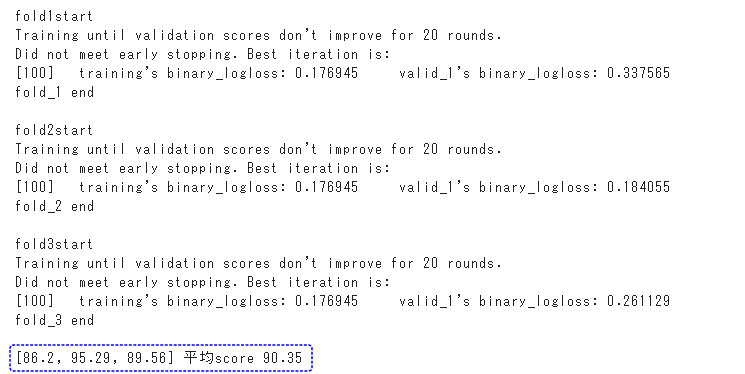
分割交差検証で学習
前回記事と同様にLightGBNアルゴリズムの3分割交差検証を使って、学習を行います。
[ソース]
1 | import lightgbm as lgb |
[出力結果]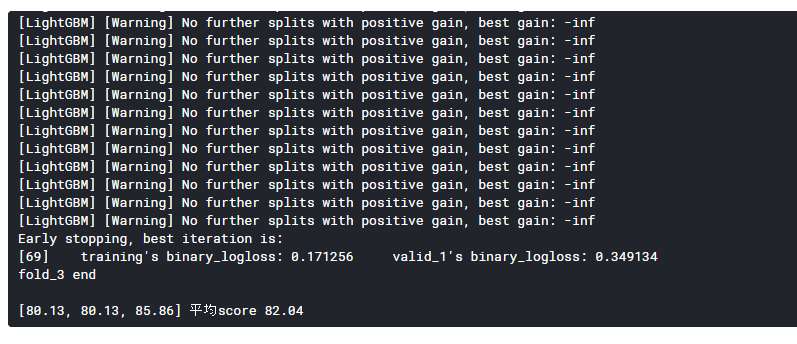
平均スコアは82.04%となりました。
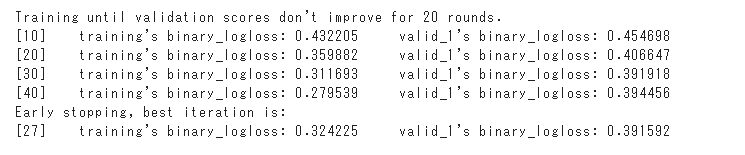
学習済みモデルを使って推論
学習済みモデルを使って、推論を行います。
3回推論を行い予測した生存の平均が0.5より大きい場合に、生存している(1)と予測します。
[ソース]
1 | # 検証データの読み込み |
提出用に作成したcsvファイルは下記のようなフォーマットになります。
[出力結果]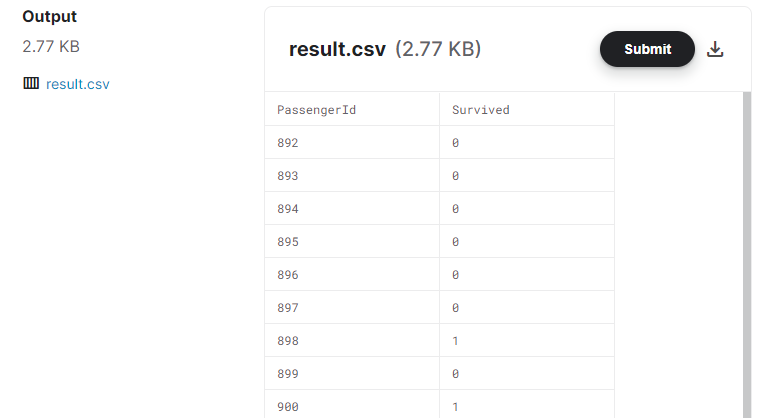
結果提出
予測したcsvファイルを提出(submit)してみます。
[提出結果]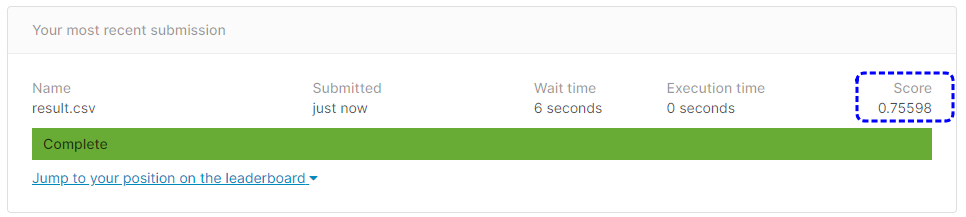
提出結果は75.56%という正解率になりました。
もう少しいい成績なると思っていたのですが、残念です。