numpyで生成した乱数を、特定関数で分類し、その分類したデータをグラフに表示します。
まずは必要なモジュールをimportします。
1 | # 基本モジュールの宣言 |
次に乱数を生成します。縦100横2の配列にreshapeしています。
1 | # 乱数生成(縦100,横2の配列分の乱数を生成) |

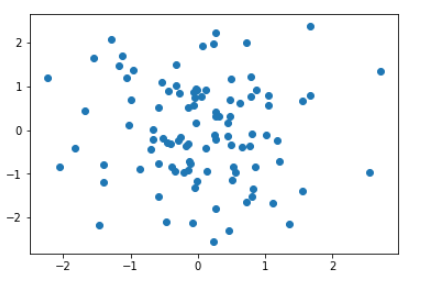
生成した配列をx,yを表した100個のデータとみなして散布図を表示します。
1 | # 散布図を表示 |
分類用の関数を定義します。ここでは単純にxを2乗した数値を返しています。
1 | # 関数の定義 |
乱数の配列に対して、定義した関数の上にくるか下にくるかを判定します。
上にくる場合は1を、下にくる場合は0が返ります。
(ループで1つずつ処理しなくても入力の配列に対して、結果の配列が返ってくるのがnumpyの便利なところです。)
1 | # 条件にあてはまるものを探す |

結果がTrue(1)となる配列のインデックスをndata0に、False(0)となる配列のインデックスをndata1に格納します。
1 | # 乱数のデータを2つのグループに分ける |

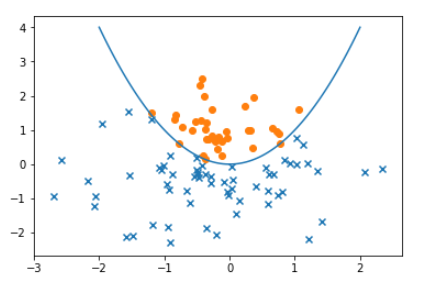
最後にグループ分け関数と分類されたデータを1つのグラフとして表示します。
1 | # 2つの種類のデータを図に示す |
(Google Colaboratoryで動作確認しています。)