pandasの基本操作を一通り試してみます。
まずは単純にpandasでcsvファイルを読み込んでみます。
[csvファイル]
1 | date,station,temp |
[コード]
1 | # pandasでcsvファイルを読み込む |
[結果]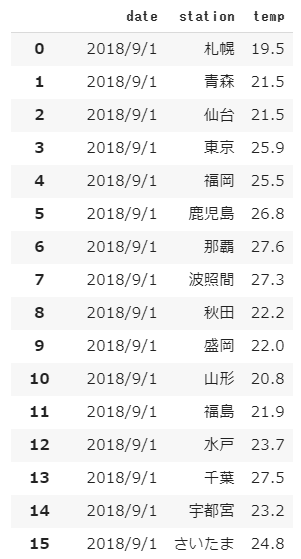
print関数を使わずJupyter上でdataframe型の変数を表示するといい感じのテーブルで表示してくれます。
dataframe型データの先頭数行を表示する場合はhead関数を使います。
(引数にデータ数を指定することもできます。)
1 | df.head() |
[結果]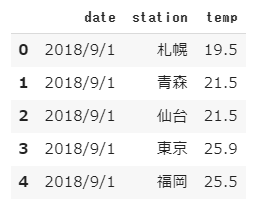
末尾数行を表示する場合はtail関数を使います。
(引数にデータ数を指定することもできます。)
1 | df.tail() |
[結果]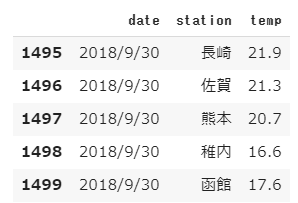
次に変数dfをインデックス指定で分割します。
範囲指定の数字はデータ自体の順番を考えるよりもデータとデータの間の順番と考えるとわかりやすいと思います。
1 | df_sliced = df.iloc[2:7] |
[結果]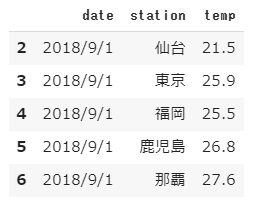
分割したデータをさらに分割することもできます。
1 | df_sliced.iloc[2:4] |
[結果]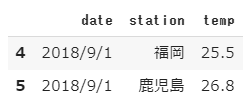
今度は行ごとに指定ではなく、列ごとに指定します。
列を指定する場合は、単純に列名(カラム名)を使用します。
1 | df['temp'] |
[結果]
カラム名で指定したデータはシリーズデータになっていて最大値、最小値、合計、平均を簡単に取得することができます。
1 | print('最大値', df['temp'].max()) |
[結果]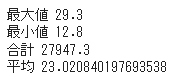
また欠損値がある場合はfillna関数を使って補完することができます。
下記は平均値で補完するサンプルコードとなります。
1 | m = df['temp'].mean() |
(Google Colaboratoryで動作確認しています。)