発行上限は2100万BTC
ビットコインには中央銀行のような管理組織はありません。
このためマイニングで無限にビットコインが発行されると、ビットコイン自体の価値が低下するというインフレになります。
コア開発者はこれを防ぐため、2100万BTCを発行上限とし、半減期という仕組みで徐々に発行量を減らすプログラムを組み込みました。
具体的には4年ごとにマイニング報酬額を半分に減らすというもので、2140年頃に発行量はゼロとなるように作られています。
ビットコインには中央銀行のような管理組織はありません。
このためマイニングで無限にビットコインが発行されると、ビットコイン自体の価値が低下するというインフレになります。
コア開発者はこれを防ぐため、2100万BTCを発行上限とし、半減期という仕組みで徐々に発行量を減らすプログラムを組み込みました。
具体的には4年ごとにマイニング報酬額を半分に減らすというもので、2140年頃に発行量はゼロとなるように作られています。
ビットコインの取引を行うためには、ウォレット・アプリを自身のパソコン・スマホ・タブレットに導入する必要があります。
このウォレットに誰かからビットコインを送金してもらうと、ウォレット上に自身が所有するビットコインの量(BTC)が表示されるようになります。
取引されたビットコインは、利用者同士のウォレット間で送受信された訳ではありません。
取引データはビットコイン・ネットワークと呼ばれる世界中にある何千台ものノードにブロードキャストされ、各ノードの中にある台帳に書き込まれます。
この台帳に書かれた取引データこそがビットコインの実態です。
全てのノードの台帳は常に同期されているため、ウォレットがどのノードに接続しても同じ取引データを参照でき、送金が行われるとそれを利用者は認識できます。
前回はUbuntuで、Ethereumの起動テストまでを行いました。
今回はアカウントの登録とマイニングを行います。
アカウントを登録するためにはpersonal.newAccountコマンドを使います。
コマンド入力後、パスフレーズを2回入力する必要がありますが、このパスフレーズは絶対に忘れないようにしてください。
パスフレーズを忘れた場合の救済措置は一切ありません。
[コマンド]
1 | personal.newAccount() |
[実行結果]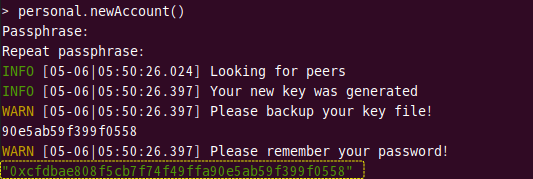
途中実行ログが表示されてしまって少々見づらいですが、最終行に表示されている文字列がアカウントを表す情報となります。
ちなみに、eth.accountsコマンドを使うと、登録されているアカウントの一覧を表示することができます。
[コマンド]
1 | eth.accounts |
[実行結果]
Ethereumでは何かを行うときに、ether(コイン、報酬)が必要となります。
理由は仲間内のブロックチェーンでも、チェーンがつながるためには複数ノードのよるマイニングが必要で、そのマイニングする動機づけとして報酬が必要だからです。
というわけで、下記コマンドを使ってマイニングを開始します。
[コマンド]
1 | minert.start() |
[実行結果]
マイニングを開始すると下記のようなログが表示されるようになります。
[実行結果]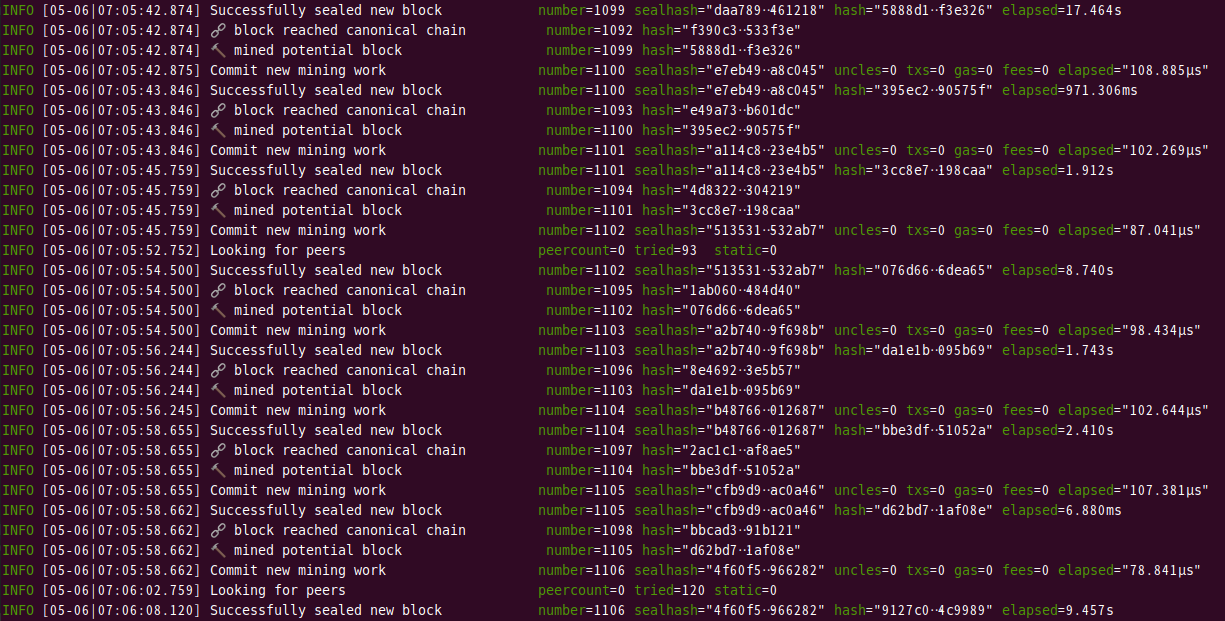
マイニングしている雰囲気を感じてもらえたら十分かと思います。🙇♀️🙇♀️🙇♀️
しばらくマイニングを続けたら、一旦下記コマンドでマイニングを止めます。
[コマンド]
1 | miner.stop() |
[実行結果]
採掘されたブロック数を確認します。
[コマンド]
1 | eth.blockNumber |
[実行結果]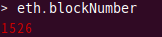
次に残高(マイニングして得た報酬)を確認します。
[コマンド]
1 | eth.getBalance("アカウント") |
[実行結果]
マイニングを行うことで、ブロックが生成され、マイニングを行ったアカウントに対して報酬(ether)を入手できることが確認できました。
前回はWSL上で、Ethereumの起動テストを行いまして失敗しました。
調べたところWSLだとListen設定ができないとのことで、WindowsにVirtualBoxをインストールし、ゲストOSとしてUbuntu20.04を設定し、再度Ethereumの起動テストを行いました。
さらに、これまでWSL上で実行してきた手順オープンソースのブロックチェーンを試す(1)~(3)をやり直しました。
以下はその続きとなります。
まず、Ethereum起動の前準備としてジェネシス・ブロックを用意します。
[ジェネシス・ブロック genblock.json]
1 | { |
次に下記のコマンドを実行し、環境の初期化を行います。
datadirオプションにはデータを保存するディレクトリを指定します。
initには作成したジェネシス・ブロック(genblock.json)を指定します。
[Ethereum起動コマンド]
1 | geth --datadir ./data init ./genblock.json |
[実行結果]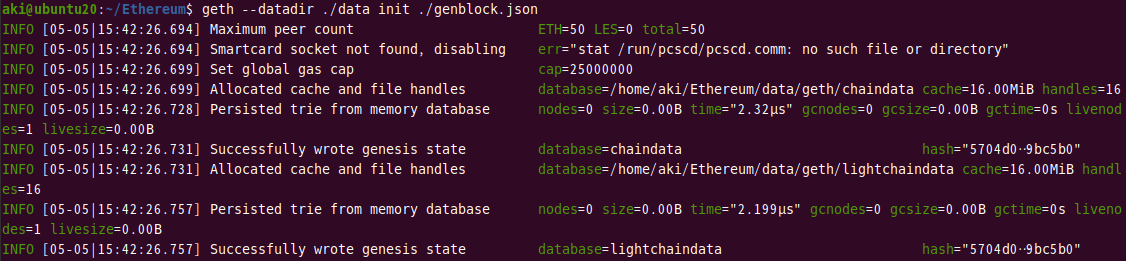
初期化が完了したら、いよいよEthereumの起動を行います。
下記コマンドを実行します。
なおnetworkidオプションには、genblock.jsonのchainIdで設定した値と同じものを指定します。
[Ethereum起動コマンド]
1 | geth --networkid "1100" --datadir ./data console |
[実行結果]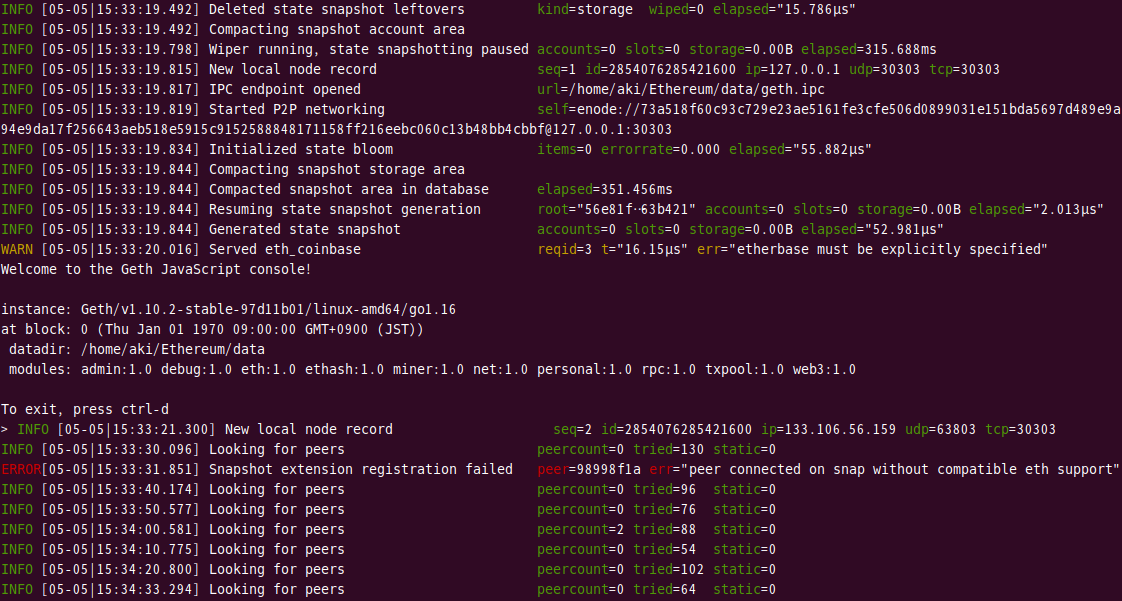
一部エラーは出ていますが、起動自体はできているようです。
次回は、アカウントの登録とマイニングを行ってみます。
今回はEthereumの起動を行います。
まずは、Ethereum起動の前準備としてジェネシス・ブロックを用意する必要があります。
[ジェネシス・ブロック genblock.json]
1 | { |
次に下記のコマンドを実行し、環境の初期化を行います。
datadirオプションにはデータを保存するディレクトリを指定します。
initには作成したジェネシス・ブロック(genblock.json)を指定します。
[Ethereum初期化コマンド]
1 | geth --datadir ./data init ./genblock.json |
[実行結果]
初期化が完了したら、いよいよEthereumの起動を行います。
下記コマンドを実行します。
なおnetworkidオプションには、genblock.jsonのchainIdで設定した値と同じものを指定します。
[Ethereum起動コマンド]
1 | geth --networkid "1100" --datadir ./data console |
[実行結果]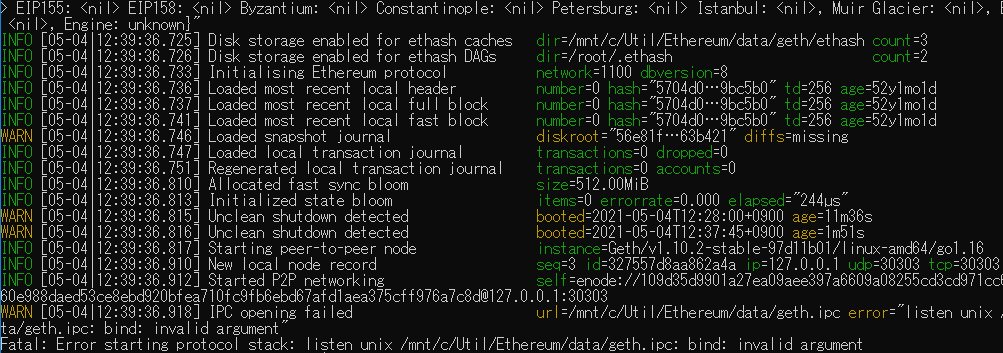
致命的なエラーとなり、うまく起動できませんでした。
調べたところWSL環境ではソケットのListenができないために、Ethereumが起動できないようです😢
次回は、WSLではなくLinux環境を構築し、再びEthereum環境の起動をトライします。
前回記事にてEthereumを使う準備が整いました。
Ethereum環境については、本番環境ではなくプライベート・ネットワーク(テスト用)を使います。
またネットワークに接続するコンピュータの数を0に設定し、自分一人がローカルで動作するモードとします。
スマート・コントラクトは、契約の自動化を目的としたものではありますが、プログラムの実行環境でもあります。
今回はデータを保存処理を組み込んでいきます。
データを保存するプログラムは以下の通りです。
プログラムはSolidityというEthereumの独自言語です。
[ソース savedata.sol]
1 | pragma solidity ^0.8.4; |
ソースをビルドするためには、solcコマンドが必要なのでインストールします。
[コマンド]
1 | sudo apt-get install solc |
[結果]
solcコンパイラが準備できたので、準備したプログラム(savedata.sol)を下記コマンドでビルドします。
[コマンド]
1 | solc -o savedata --abi --bin savedata.sol |
正常にビルドできると次のような2ファイルが生成されます。
savedata/SingleNumRegister.abi

savedata/SingleNumRegister.bin
次回は、Ethereum環境の起動を行います。
オフィシャル・リリースであるgo-ethereumを使って、Ethereumの環境を構築します。
ソースからビルドする方法もありますが、今回はパッケージを使用してインストールします。
WSLコンソールでgo-ethereumをインストールしていきます。
まずはリポジトリ追加のコマンドとethereumリポジトリの追加を行います。
[コマンド]
1 | sudo apt-get install apt-file |
Ethereum gethコマンドをインストールします。
[コマンド]
1 | sudo apt-get update |
go-ethereumがインストールできていることを確認するために、gethコマンドのバージョンを確認します。
[コマンド]
1 | geth version |
[結果]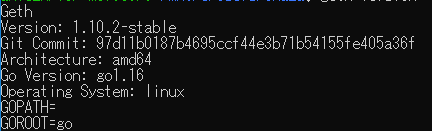
次回は、Ethereum環境の起動を行います。
ブロックチェーンは、さまざまな実装が行われ暗号通貨サービス以外への応用も進められてきました。
その多くがオープンソースとして公開されています。
ビットコインについでシェアが大きい暗号通貨はEthereum(イーサリアム)です。
Ethereumは暗号通貨としてだけではなく、スマートコントラクトと呼ばれる、契約条件の確認や実行の自動化を実現するための基盤となっています。
分散環境で処理を実行するためのプラットフォームという側面もあります。
Ethereumは、実サービスでも利用でき、開発環境も用意されています。
これからオープンソースのブロックチェーン基盤を使ったアプリ作成を行っていきます。
次回はまず、ステップ1としてEthereum環境の構築をしていきます。
通常本を出版する場合、印税が5%~10%程度ですが、Amazonの電子書籍で出版すると70%のロイヤリティが得られるということです。
(地域によってロイヤリティが変わるようですが、日本は70%みたいです)
つまり売り上げの7割を収入として得られることになり、通常本の出版に比べて7倍から14倍の収益率となります。
そこで本の内容はともかく、Kindleの電子書籍を出版する方法(手順)を調べてみました。
(全部無料で使えるものです。)
いろいろ調べたところ、次のように電子書籍を作成することにしました。
LaTexを使って本を作成します。
LaTexは最強の文書整形システムと言われており、綺麗な文章を書きたい人、綺麗な数式を書きたい人、化学式を綺麗に書きたい人に好まれて使用されています。
Wordを使うよりも、はるかに作業しやすくとにかく綺麗な文章が書けるのでおススメなのですが、慣れない人にはその良さは伝わりにくいかと思います。
(Sigilというフリーツールを使って、epubファイルを作るという方法もありました。
こちらの方法が一般的かもしれません。)
まずWSLのコンソールを開いて、下記コマンドを実行しLaTex環境をインストールします。
[コマンド]
1 | sudo apt install language-pack-ja manpages-ja manpages-ja-dev nkf |
次にsample.texというLaTexファイルを作成します。
[sample.tex]
1 | \documentclass{article} |
sample.texをコンパイルして、pdfファイルを出力します。
[コマンド]
1 | platex sample.tex |
次のようなpdfファイルが出力されます。
[出力されたpdf]
やはりLaTexは数式がきれいに表示されて気持ちがいいです。
pandocというツールを使うと、いろいろな文書形式のファイルを相互に変換することができます。
今回はLaTexファイルをepubファイルに変換します。
まずは次のコマンドを実行しpandocをインストールします。
[コマンド]
1 | sudo apt install pandoc |
pandocコマンドを使ってtexファイルをepubファイルに変換します。
[コマンド]
1 | LANG=ja_JP.UTF-8;pandoc sample.tex -o sample.epub |
※次項目でのepubファイルを開く際に、言語に関するメタデータがないというエラーがでたため、変換前に言語設定(LANG=ja_JP.UTF-8)を行っています。
下記サイトからKindle Previewerをダウンロードし、インストールを行います。
作成したepubファイルを開いて表示を確認します。

pdfとは少し表示が異なっていますが、Kindle Previewerでの表示が出版した時の正しい表示となると思います。
というとで、今回の手順で本を作成する方法を簡単にまとめます。
本を編纂するために上記作業を繰り返すことになると思います・・・・結構手間ですね。
本が完成したら、Amazon Kindle Direct Publishingにepubファイルを登録し出版することになります。
出版手順は下記サイトが分かりやすいのでご参照ください。
書籍出版というものは、著名人や頭のいい人たちがするもので自分には関係ないものかと思っていましたが、電子書籍で在庫を抱えずノーリスクで出版できるとなると一気に敷居が下がったように感じます。
しかも印税が7割と通常の書籍出版より断然収益率が高いというメリットもあります。
今回はLaTexで本の内容を書いて、epubに変換して出版するという王道とは外れた方法かと思いますが、LaTex大好きな人達にとっては有益な記事になったのではないかと思います。
(少数派とは思いますが・・・)
ビットコインでは、マイニングはPoW(Proof of Work)によって行われます。
これは新規ブロックを生成し、そのブロックに正しい取引データが記録されているかどうかを承認するものです。
PoWはより多くの仕事がなされたブロックチェーンが有効になります。
総当たり的にハッシュ値を求めるので、計算範囲が広く、コンピュータの処理能力と大きなメモリ、そして大きな電力が必要となります。
ビットコインは簡単にマイニングできないように設計されているので、ラズベリー・パイなどの小型コンピュータではマイニングすることが不可能です。
PoWの改善策として、非力なコンピュータでもマイニングできるように考え出されたのがPoS(Proof of Stake)です。
PoSでは新規ブロックの生成はマイニングまたはフォージングと呼ばれ、暗号通貨の保有量と保有期間の掛け算でしめされるcoin ageが大きいほど、ハッシュ計算の範囲が狭くなり、有利になります。