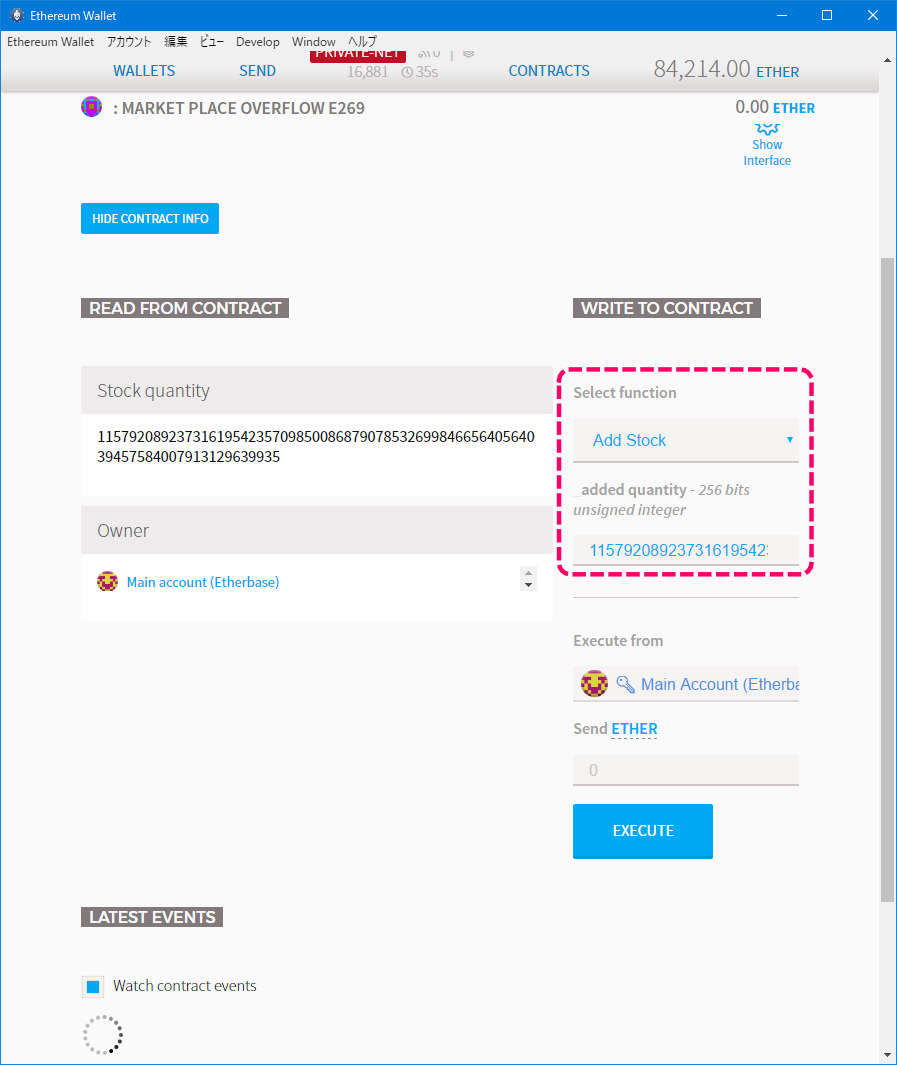
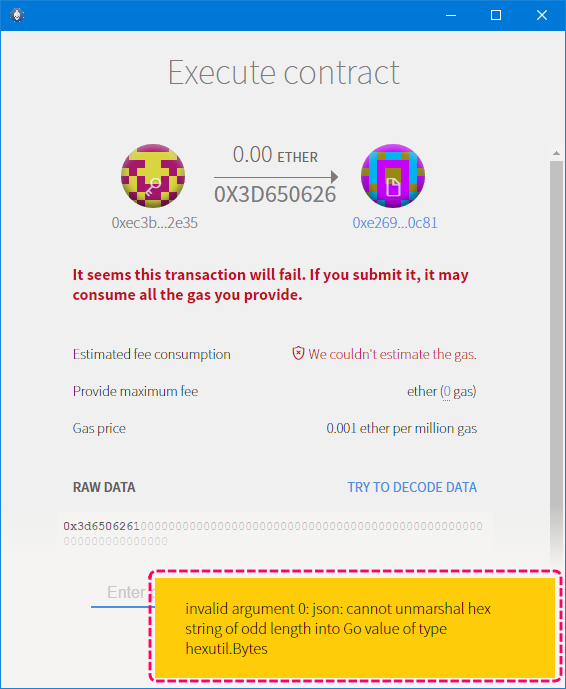
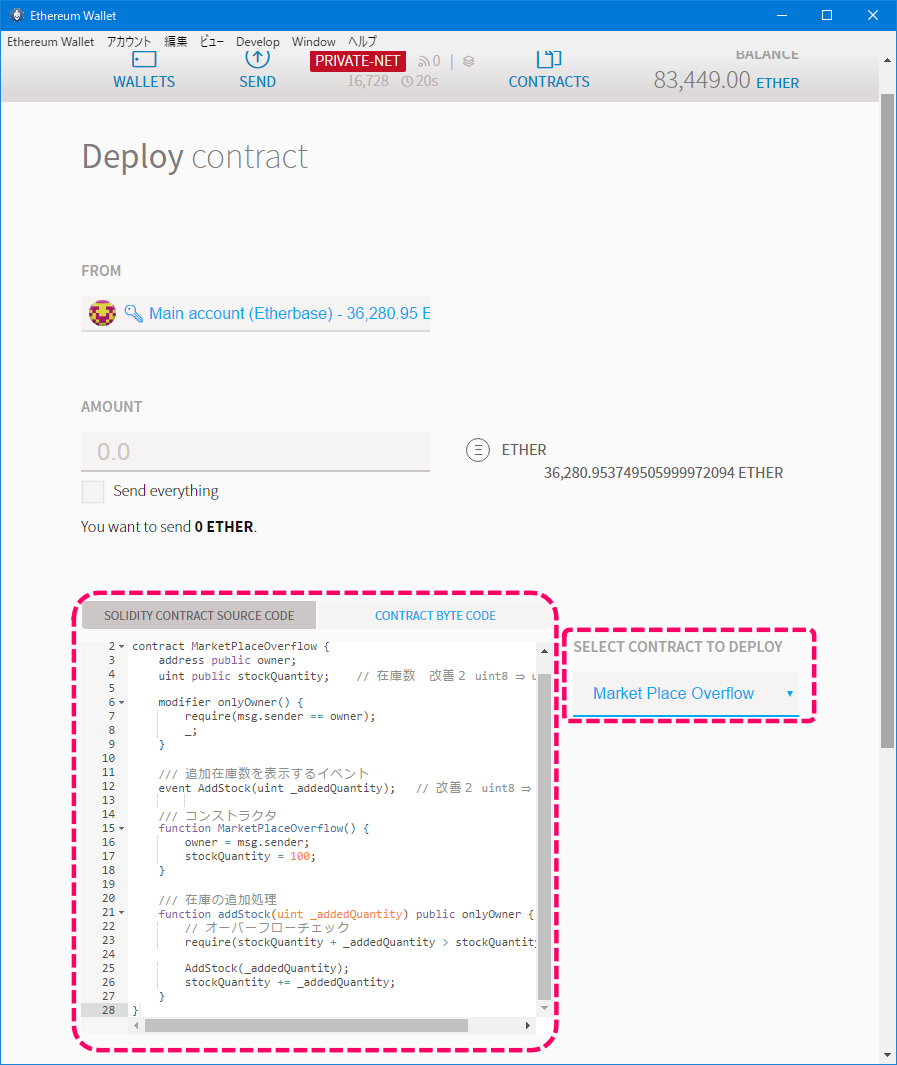
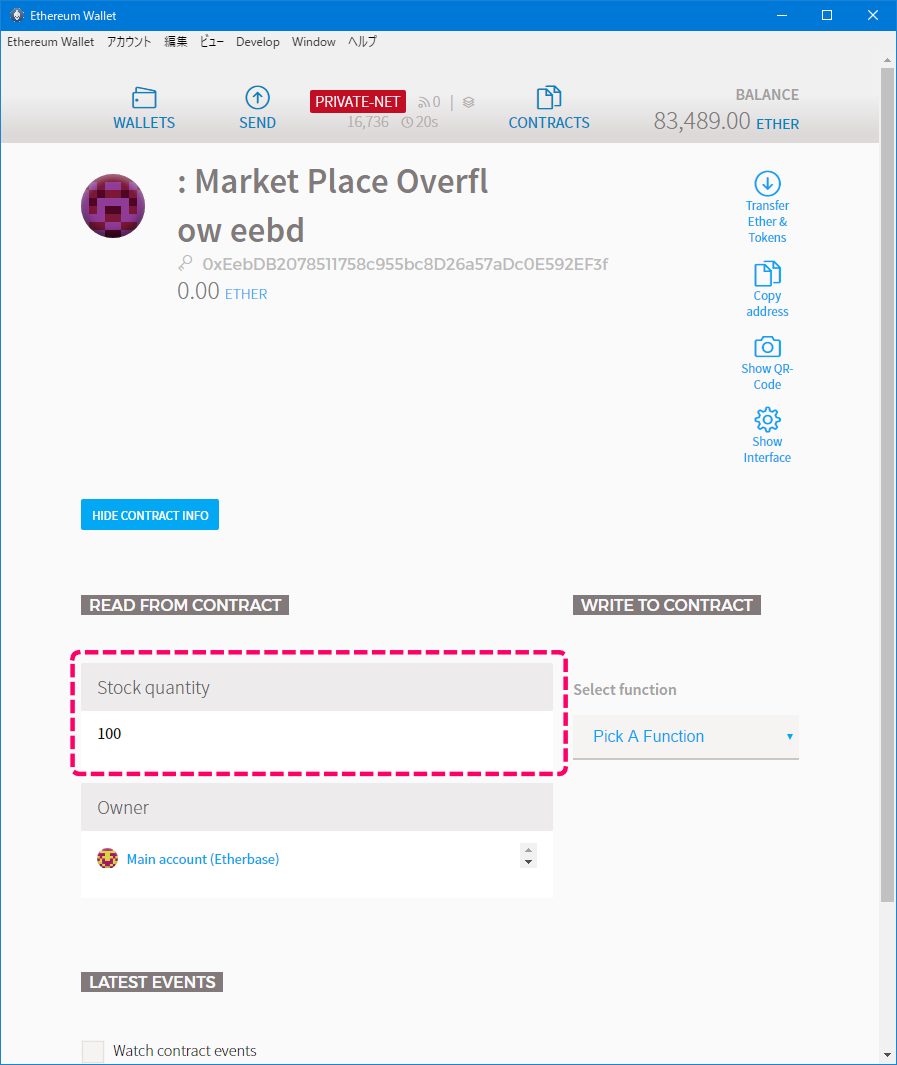
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
| > db.group.stats()
{
"ns" : "db1.group",
"size" : 0,
"count" : 0,
"storageSize" : 4096,
"freeStorageSize" : 0,
"capped" : false,
"wiredTiger" : {
"metadata" : {
"formatVersion" : 1
},
"creationString" : "access_pattern_hint=none,allocation_size=4KB,app_metadata=(formatVersion=1),assert=(commit_timestamp=none,durable_timestamp=none,read_timestamp=none,write_timestamp=off),block_allocation=best,block_compressor=snappy,cache_resident=false,checksum=on,colgroups=,collator=,columns=,dictionary=0,encryption=(keyid=,name=),exclusive=false,extractor=,format=btree,huffman_key=,huffman_value=,ignore_in_memory_cache_size=false,immutable=false,import=(enabled=false,file_metadata=,repair=false),internal_item_max=0,internal_key_max=0,internal_key_truncate=true,internal_page_max=4KB,key_format=q,key_gap=10,leaf_item_max=0,leaf_key_max=0,leaf_page_max=32KB,leaf_value_max=64MB,log=(enabled=true),lsm=(auto_throttle=true,bloom=true,bloom_bit_count=16,bloom_config=,bloom_hash_count=8,bloom_oldest=false,chunk_count_limit=0,chunk_max=5GB,chunk_size=10MB,merge_custom=(prefix=,start_generation=0,suffix=),merge_max=15,merge_min=0),memory_page_image_max=0,memory_page_max=10m,os_cache_dirty_max=0,os_cache_max=0,prefix_compression=false,prefix_compression_min=4,readonly=false,source=,split_deepen_min_child=0,split_deepen_per_child=0,split_pct=90,tiered_object=false,tiered_storage=(auth_token=,bucket=,bucket_prefix=,local_retention=300,name=,object_target_size=10M),type=file,value_format=u,verbose=[],write_timestamp_usage=none",
"type" : "file",
"uri" : "statistics:table:collection-7-156884005367683298",
"LSM" : {
"bloom filter false positives" : 0,
"bloom filter hits" : 0,
"bloom filter misses" : 0,
"bloom filter pages evicted from cache" : 0,
"bloom filter pages read into cache" : 0,
"bloom filters in the LSM tree" : 0,
"chunks in the LSM tree" : 0,
"highest merge generation in the LSM tree" : 0,
"queries that could have benefited from a Bloom filter that did not exist" : 0,
"sleep for LSM checkpoint throttle" : 0,
"sleep for LSM merge throttle" : 0,
"total size of bloom filters" : 0
},
"block-manager" : {
"allocations requiring file extension" : 0,
"blocks allocated" : 0,
"blocks freed" : 0,
"checkpoint size" : 0,
"file allocation unit size" : 4096,
"file bytes available for reuse" : 0,
"file magic number" : 120897,
"file major version number" : 1,
"file size in bytes" : 4096,
"minor version number" : 0
},
"btree" : {
"btree checkpoint generation" : 0,
"btree clean tree checkpoint expiration time" : 0,
"column-store fixed-size leaf pages" : 0,
"column-store internal pages" : 0,
"column-store variable-size RLE encoded values" : 0,
"column-store variable-size deleted values" : 0,
"column-store variable-size leaf pages" : 0,
"fixed-record size" : 0,
"maximum internal page key size" : 368,
"maximum internal page size" : 4096,
"maximum leaf page key size" : 2867,
"maximum leaf page size" : 32768,
"maximum leaf page value size" : 67108864,
"maximum tree depth" : 0,
"number of key/value pairs" : 0,
"overflow pages" : 0,
"pages rewritten by compaction" : 0,
"row-store empty values" : 0,
"row-store internal pages" : 0,
"row-store leaf pages" : 0
},
"cache" : {
"bytes currently in the cache" : 182,
"bytes dirty in the cache cumulative" : 0,
"bytes read into cache" : 0,
"bytes written from cache" : 0,
"checkpoint blocked page eviction" : 0,
"checkpoint of history store file blocked non-history store page eviction" : 0,
"data source pages selected for eviction unable to be evicted" : 0,
"eviction walk passes of a file" : 0,
"eviction walk target pages histogram - 0-9" : 0,
"eviction walk target pages histogram - 10-31" : 0,
"eviction walk target pages histogram - 128 and higher" : 0,
"eviction walk target pages histogram - 32-63" : 0,
"eviction walk target pages histogram - 64-128" : 0,
"eviction walk target pages reduced due to history store cache pressure" : 0,
"eviction walks abandoned" : 0,
"eviction walks gave up because they restarted their walk twice" : 0,
"eviction walks gave up because they saw too many pages and found no candidates" : 0,
"eviction walks gave up because they saw too many pages and found too few candidates" : 0,
"eviction walks reached end of tree" : 0,
"eviction walks restarted" : 0,
"eviction walks started from root of tree" : 0,
"eviction walks started from saved location in tree" : 0,
"hazard pointer blocked page eviction" : 0,
"history store table insert calls" : 0,
"history store table insert calls that returned restart" : 0,
"history store table out-of-order resolved updates that lose their durable timestamp" : 0,
"history store table out-of-order updates that were fixed up by reinserting with the fixed timestamp" : 0,
"history store table reads" : 0,
"history store table reads missed" : 0,
"history store table reads requiring squashed modifies" : 0,
"history store table truncation by rollback to stable to remove an unstable update" : 0,
"history store table truncation by rollback to stable to remove an update" : 0,
"history store table truncation to remove an update" : 0,
"history store table truncation to remove range of updates due to key being removed from the data page during reconciliation" : 0,
"history store table truncation to remove range of updates due to out-of-order timestamp update on data page" : 0,
"history store table writes requiring squashed modifies" : 0,
"in-memory page passed criteria to be split" : 0,
"in-memory page splits" : 0,
"internal pages evicted" : 0,
"internal pages split during eviction" : 0,
"leaf pages split during eviction" : 0,
"modified pages evicted" : 0,
"overflow pages read into cache" : 0,
"page split during eviction deepened the tree" : 0,
"page written requiring history store records" : 0,
"pages read into cache" : 0,
"pages read into cache after truncate" : 0,
"pages read into cache after truncate in prepare state" : 0,
"pages requested from the cache" : 0,
"pages seen by eviction walk" : 0,
"pages written from cache" : 0,
"pages written requiring in-memory restoration" : 0,
"tracked dirty bytes in the cache" : 0,
"unmodified pages evicted" : 0
},
"cache_walk" : {
"Average difference between current eviction generation when the page was last considered" : 0,
"Average on-disk page image size seen" : 0,
"Average time in cache for pages that have been visited by the eviction server" : 0,
"Average time in cache for pages that have not been visited by the eviction server" : 0,
"Clean pages currently in cache" : 0,
"Current eviction generation" : 0,
"Dirty pages currently in cache" : 0,
"Entries in the root page" : 0,
"Internal pages currently in cache" : 0,
"Leaf pages currently in cache" : 0,
"Maximum difference between current eviction generation when the page was last considered" : 0,
"Maximum page size seen" : 0,
"Minimum on-disk page image size seen" : 0,
"Number of pages never visited by eviction server" : 0,
"On-disk page image sizes smaller than a single allocation unit" : 0,
"Pages created in memory and never written" : 0,
"Pages currently queued for eviction" : 0,
"Pages that could not be queued for eviction" : 0,
"Refs skipped during cache traversal" : 0,
"Size of the root page" : 0,
"Total number of pages currently in cache" : 0
},
"checkpoint-cleanup" : {
"pages added for eviction" : 0,
"pages removed" : 0,
"pages skipped during tree walk" : 0,
"pages visited" : 0
},
"compression" : {
"compressed page maximum internal page size prior to compression" : 4096,
"compressed page maximum leaf page size prior to compression " : 131072,
"compressed pages read" : 0,
"compressed pages written" : 0,
"page written failed to compress" : 0,
"page written was too small to compress" : 0
},
"cursor" : {
"Total number of entries skipped by cursor next calls" : 0,
"Total number of entries skipped by cursor prev calls" : 0,
"Total number of entries skipped to position the history store cursor" : 0,
"Total number of pages skipped without reading by cursor next calls" : 0,
"Total number of pages skipped without reading by cursor prev calls" : 0,
"Total number of times a search near has exited due to prefix config" : 0,
"bulk loaded cursor insert calls" : 0,
"cache cursors reuse count" : 0,
"close calls that result in cache" : 1,
"create calls" : 1,
"cursor next calls that skip due to a globally visible history store tombstone" : 0,
"cursor next calls that skip greater than or equal to 100 entries" : 0,
"cursor next calls that skip less than 100 entries" : 1,
"cursor prev calls that skip due to a globally visible history store tombstone" : 0,
"cursor prev calls that skip greater than or equal to 100 entries" : 0,
"cursor prev calls that skip less than 100 entries" : 0,
"insert calls" : 0,
"insert key and value bytes" : 0,
"modify" : 0,
"modify key and value bytes affected" : 0,
"modify value bytes modified" : 0,
"next calls" : 1,
"open cursor count" : 0,
"operation restarted" : 0,
"prev calls" : 0,
"remove calls" : 0,
"remove key bytes removed" : 0,
"reserve calls" : 0,
"reset calls" : 2,
"search calls" : 0,
"search history store calls" : 0,
"search near calls" : 0,
"truncate calls" : 0,
"update calls" : 0,
"update key and value bytes" : 0,
"update value size change" : 0
},
"reconciliation" : {
"approximate byte size of timestamps in pages written" : 0,
"approximate byte size of transaction IDs in pages written" : 0,
"dictionary matches" : 0,
"fast-path pages deleted" : 0,
"internal page key bytes discarded using suffix compression" : 0,
"internal page multi-block writes" : 0,
"internal-page overflow keys" : 0,
"leaf page key bytes discarded using prefix compression" : 0,
"leaf page multi-block writes" : 0,
"leaf-page overflow keys" : 0,
"maximum blocks required for a page" : 0,
"overflow values written" : 0,
"page checksum matches" : 0,
"page reconciliation calls" : 0,
"page reconciliation calls for eviction" : 0,
"pages deleted" : 0,
"pages written including an aggregated newest start durable timestamp " : 0,
"pages written including an aggregated newest stop durable timestamp " : 0,
"pages written including an aggregated newest stop timestamp " : 0,
"pages written including an aggregated newest stop transaction ID" : 0,
"pages written including an aggregated newest transaction ID " : 0,
"pages written including an aggregated oldest start timestamp " : 0,
"pages written including an aggregated prepare" : 0,
"pages written including at least one prepare" : 0,
"pages written including at least one start durable timestamp" : 0,
"pages written including at least one start timestamp" : 0,
"pages written including at least one start transaction ID" : 0,
"pages written including at least one stop durable timestamp" : 0,
"pages written including at least one stop timestamp" : 0,
"pages written including at least one stop transaction ID" : 0,
"records written including a prepare" : 0,
"records written including a start durable timestamp" : 0,
"records written including a start timestamp" : 0,
"records written including a start transaction ID" : 0,
"records written including a stop durable timestamp" : 0,
"records written including a stop timestamp" : 0,
"records written including a stop transaction ID" : 0
},
"session" : {
"object compaction" : 0,
"tiered operations dequeued and processed" : 0,
"tiered operations scheduled" : 0,
"tiered storage local retention time (secs)" : 0,
"tiered storage object size" : 0
},
"transaction" : {
"race to read prepared update retry" : 0,
"rollback to stable history store records with stop timestamps older than newer records" : 0,
"rollback to stable inconsistent checkpoint" : 0,
"rollback to stable keys removed" : 0,
"rollback to stable keys restored" : 0,
"rollback to stable restored tombstones from history store" : 0,
"rollback to stable restored updates from history store" : 0,
"rollback to stable sweeping history store keys" : 0,
"rollback to stable updates removed from history store" : 0,
"transaction checkpoints due to obsolete pages" : 0,
"update conflicts" : 0
}
},
"nindexes" : 1,
"indexBuilds" : [ ],
"totalIndexSize" : 4096,
"totalSize" : 8192,
"indexSizes" : {
"_id_" : 4096
},
"scaleFactor" : 1,
"ok" : 1
}
|