機械学習の代表的な処理として次の3つを挙げることができます。
- 分類
与えられたデータから分類(クラス)を予測します。 - 回帰
与えられたデータから数値を予測します。 - クラスタリング
データの性質に従って、データの塊(クラスタ)を作成します。
今回は機械学習の前準備としまして、データの準備とグラフ化を行っていきます。
データの準備・グラフ化
[コード]
1 | # matplotlibとnumpyをインポート |
[実行結果]
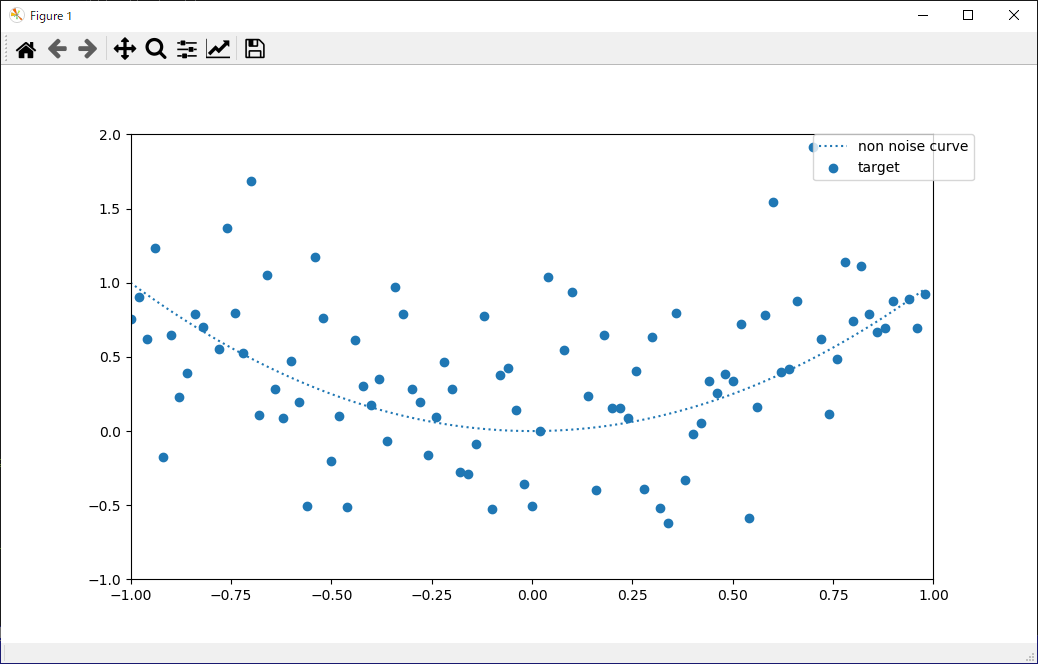
青い●が機械学習で使用するデータとなります。
点線はノイズが乗る前の元の曲線を表しています。