機械学習によるクラスタリングを行ってみます。
クラスタリング用のデータ準備
まずはクラスタリング用のデータを準備します。
クラスタリングでは学習データとテストデータという区別はありません。
ただデータを与えれば、データを種類ごとに分けてくれます。
[コード]
1 | # matplotlibとnumpyをインポート |
クラスタリング
クラスタリングを行います。今回はデータを3つに分けてグラフに表示します。
7行目のn_clustersに分類数を設定します。
[コード]
1 | from sklearn import cluster |
実行結果は下記の通りです。
[実行結果]
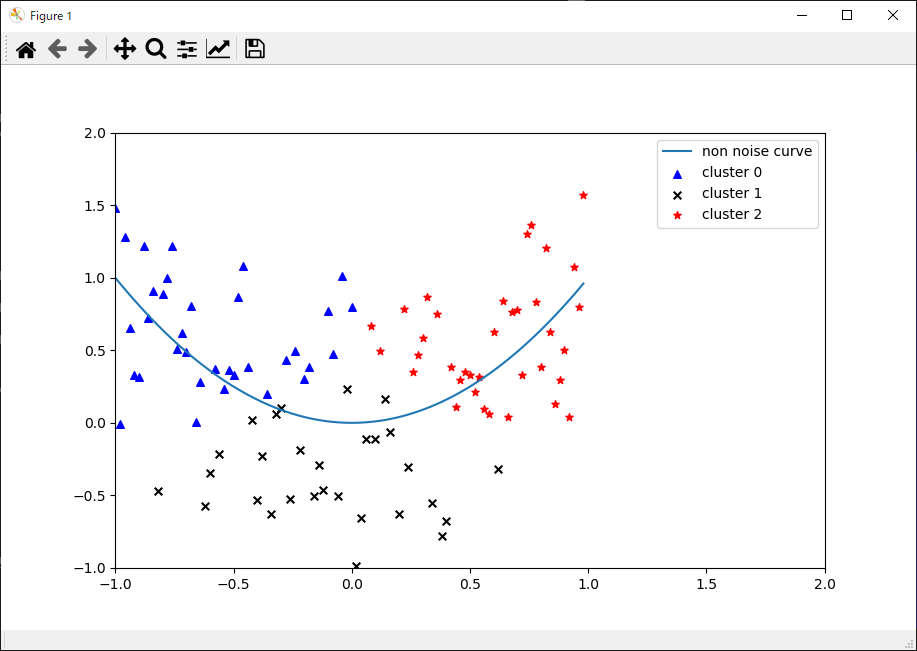
データが青の▲マーク、黒の×マーク、赤の★マークの3つに分類されていることが分かります。