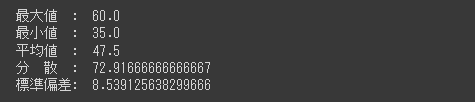
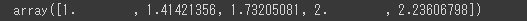NumPyには、切り捨て、切り上げ、四捨五入を行うメソッドが用意されています。
切り捨て
floor()メソッドを使うと、小数部を切り捨てて、値が小さい方の整数に変換にします。
[Google Colaboratory]
1
2
3
4
| import numpy as np
x = np.array([-1.8, -1.4, -1.0, -0.6, -0.2, 0., 0.2, 0.6, 1.0, 1.4, 1.8])
np.floor(x)
|
[実行結果]

trunc()メソッドを使うと、単純に小数部を切り捨てます。
[Google Colaboratory]
[実行結果]

切り上げ
ceil()メソッドを使うと、小数部を切り上げます。
[Google Colaboratory]
[実行結果]

四捨五入
round()メソッドを使うと、小数部を四捨五入します。
[Google Colaboratory]
[実行結果]

around()メソッドを使うと、小数部を四捨五入します。
[Google Colaboratory]
rint()メソッドを使うと、小数部を四捨五入します。
[実行結果]

[Google Colaboratory]
[実行結果]

0に近い方の整数
fix()メソッドを使うと、0に近い方向の整数に変換します。
[Google Colaboratory]
[実行結果]