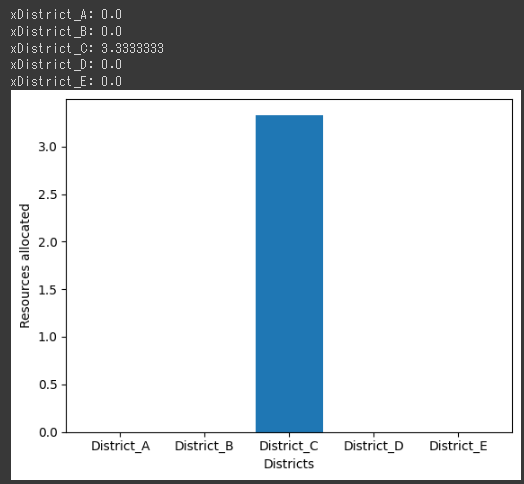
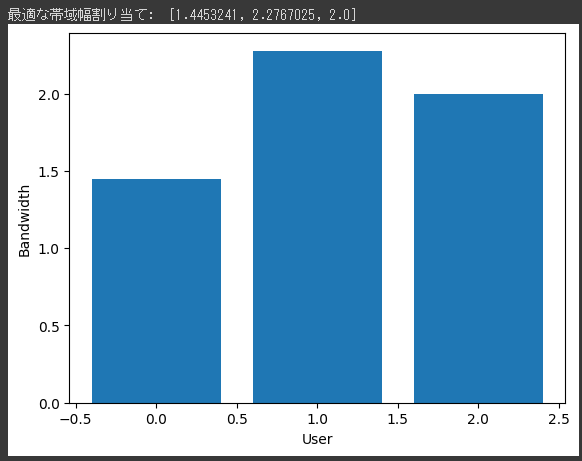
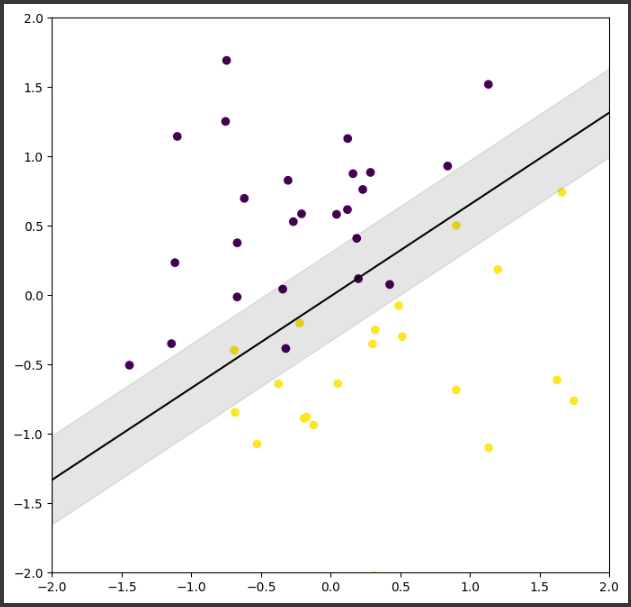
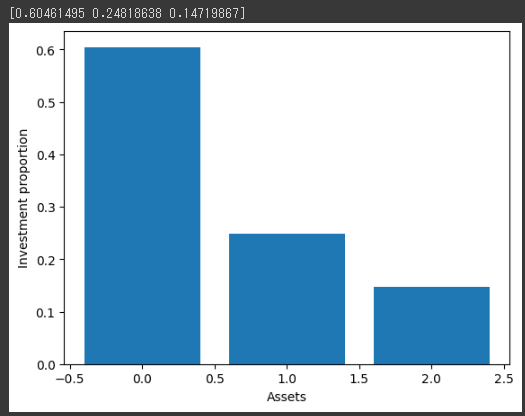
風力発電の出力予測
風力発電の出力予測に関する問題を考えてみましょう。
風力発電の出力は風速に大きく依存しますが、風速は時間とともに変化するため、出力の予測は重要な課題となります。
この問題を線形回帰モデルを用いて解くことを考えます。
風速を独立変数、風力発の出力を従属変数として、最小二乗によりモデルのパラメータを最適化します。
Pythonのライブラリであるscikit-learnを用いてこの問題を解くことができます。
以下に、風力発電の出力予測のための簡単なコードを示します。
1 | from sklearn.linear_model import LinearRegression |
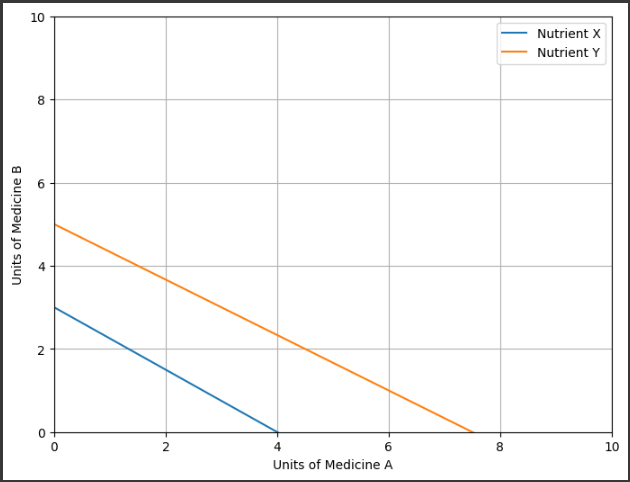
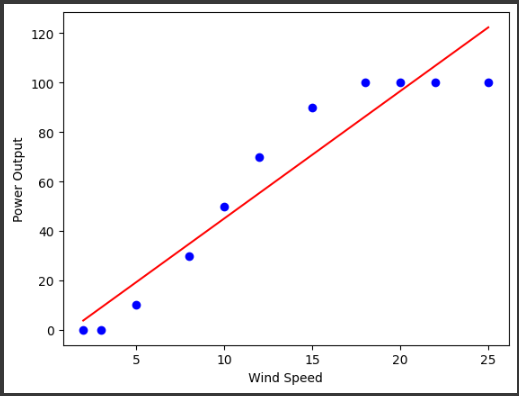
このコードでは、風速と風力発電の出力の関係を学習し、その結果をグラフ化しています。
青色の点が実際のデータ、赤色の線が予測モデルによる出力を表しています。
ただし、実際の風力発電の出力は風速だけでなく、風向や気温、湿度などの他の要素にも影響を受けます。
また、風力発電の出力は風速が一定の値を超えると飽和するため、線形モデルよりも複雑なモデルを用いることが適切な場もあります。
[実行結果]
解説
このコードは、線形回帰を使用して風速と風力発電の出力の関係をモデリングし、その結果をグラフで表示するためのものです。
from sklearn.linear_model import LinearRegression:
scikit-learnライブラリからLinearRegressionクラスをインポートします。これは、線形回帰モデルを作成するためのクラスです。import matplotlib.pyplot as plt:
matplotlibライブラリからpyplotモジュールをインポートします。
これは、グラフを描画するための機能を提供します。import numpy as np:
numpyライブラリをインポートします。
numpyは、数値計算や配列操作などの機能を提供します。wind_speed = np.array([2, 3, 5, 8, 10, 12, 15, 18, 20, 22, 25]):
風速のデータをnumpyの配列として定義します。power_output = np.array([0, 0, 10, 30, 50, 70, 90, 100, 100, 100, 100]):
風力発電の出力のデータをnumpyの配列として定義します。model = LinearRegression():
LinearRegressionクラスのインスタンスを作成し、modelという名前の変数に格納します。model.fit(wind_speed.reshape(-1, 1), power_output):
モデルをデータに適合させます。fitメソッドは、与えられた入力データ(風速)と出力データ(風力発電)を使用してモデルを学習します。plt.scatter(wind_speed, power_output, color='blue'):
scatter関数を使用して、散布図を描画します。
x軸に風速、y軸に風力発電の出力をプロットします。plt.plot(wind_speed, model.predict(wind_speed.reshape(-1, 1)), color='red'):
plot関数を使用して、線形回帰モデルによる予測値を描画します。model.predictメソッドを使用して、与えられた風速に対する予測値を計算し、その結果をプロットします。plt.xlabel('Wind Speed'):
x軸のラベルを設定します。plt.ylabel('Power Output'):
y軸のラベルを設定します。plt.show():
グラフを表示します。
このコードの結果として、散布図と線形回帰モデルによる予測値を持つグラフが表示されます。
グラフを通じて、風速と風力発電の出力の関係を視覚化することができます。
散布図は青色でプロットされ、実際の風速と風力発電の出力のデータを表示します。
また、線形回帰モデルによる予測値は赤色の線で表示され、風速に対する予測された風力発電の出力を示します。
線形回帰モデルは、与えられたデータセットを基に学習し、風速と風力発電の出力の間の線形な関係を捉えようとします。
この例では、風速が増加すると風力発電の出力も増加する傾向があることが示されています。
このグラフを通じて、風速と風力発電の出力の関係性を直感的に理解することができます。
また、線形回帰モデルの予測を用いることで、未知の風速に対しても風力発電の出力を予測することが可能です。
Logitec LGB-8BNHEU3