Conquering Chaos
If you’ve ever worked in optimization, you know that not all problems are created equal. Some cost functions have a single, elegant global minimum that any basic gradient descent can find in seconds. Others are a minefield of local minima designed to trap naive algorithms. Today, we’re tackling one of the most famous examples of the latter: the Rastrigin function.
This benchmark function is a rite of passage for anyone studying metaheuristic optimization — genetic algorithms, particle swarm optimization, differential evolution, and simulated annealing all get tested against it. Let’s break down exactly why it’s so difficult, and then solve it properly in Python.
What Makes the Rastrigin Function So Difficult?
The Rastrigin function is defined as:
$$
f(\mathbf{x}) = An + \sum_{i=1}^{n} \left[ x_i^2 - A\cos(2\pi x_i) \right]
$$
where $A = 10$ and $\mathbf{x} = (x_1, x_2, \dots, x_n) \in [-5.12, 5.12]^n$.
At first glance, this looks simple — it’s just a quadratic bowl ($x_i^2$) with a cosine term layered on top. But that cosine term is the troublemaker. It creates a highly regular pattern of ripples across the entire search space, generating an enormous number of local minima that grow exponentially with dimension $n$. The global minimum is always at $\mathbf{x} = \mathbf{0}$, where $f(\mathbf{0}) = 0$, but a naive local optimizer starting anywhere off-center will almost certainly get stuck in one of the surrounding “dips” long before it ever finds the true bottom.
This makes the Rastrigin function the perfect testbed for demonstrating the difference between local optimization (which gets fooled) and global optimization (which doesn’t).
Our Approach
In this article, we’ll do four things:
- Visualize the Rastrigin landscape in 3D to see why it’s so treacherous.
- Demonstrate how a standard local optimizer (L-BFGS-B) gets trapped in local minima.
- Solve the problem properly using Differential Evolution (DE), a population-based global optimizer.
- Provide a vectorized, high-speed version of the DE solver for higher-dimensional cases, since naive implementations can be painfully slow.
Let’s get into the code.
Full Source Code
1 | import numpy as np |
Best value found across 30 local searches: 0.9950 Worst value found: 49.7474 Success rate (f < 0.01): 0/30 --- Standard (scalar) Differential Evolution --- Global minimum found: f(x*) = 9.949591e-01 x* = [-0. -0. -0. -0. 0.995 -0. -0. -0. -0. -0. ] Elapsed time: 10.238 s Generations run: 518 --- Vectorized (high-speed) Differential Evolution --- Global minimum found: f(x*) = 0.000000e+00 x* = [ 0. -0. 0. 0. 0. 0. 0. 0. -0. 0.] Elapsed time: 1.981 s Generations run: 778 Speedup factor: 5.17x faster
Code Walkthrough
1. Two flavors of the objective function
Notice that we defined two versions of the Rastrigin function: rastrigin_scalar and rastrigin_vectorized. This isn’t redundant — it’s the key to the performance story of this article.
rastrigin_scalar takes a single candidate solution (a 1D array) and returns a single number. This is the natural way to write an objective function, and it’s what most scipy.optimize routines expect by default.
rastrigin_vectorized, on the other hand, accepts an entire population of candidates at once — a 2D array where each column is one candidate solution — and returns all their objective values in one shot using NumPy’s broadcasting. This eliminates the Python-level loop overhead that occurs when an optimizer evaluates hundreds of candidates one at a time.
2. Visualizing the landscape
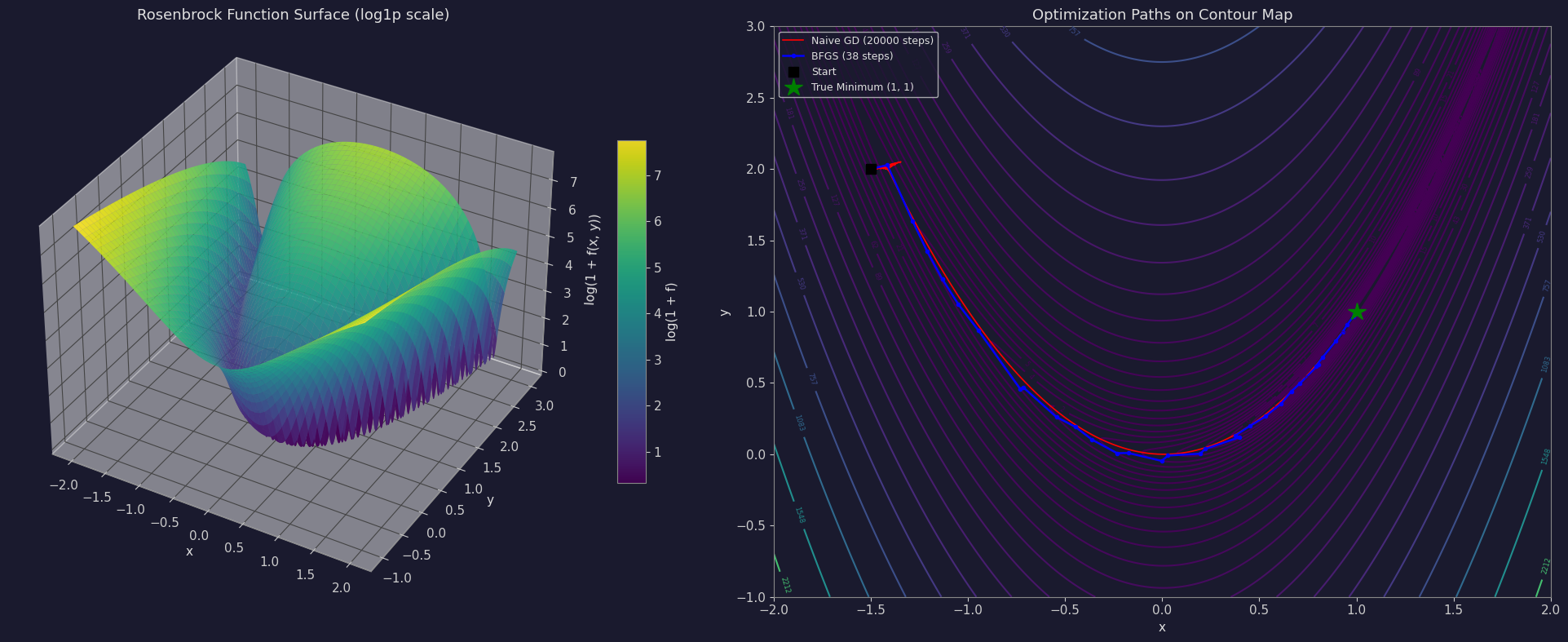
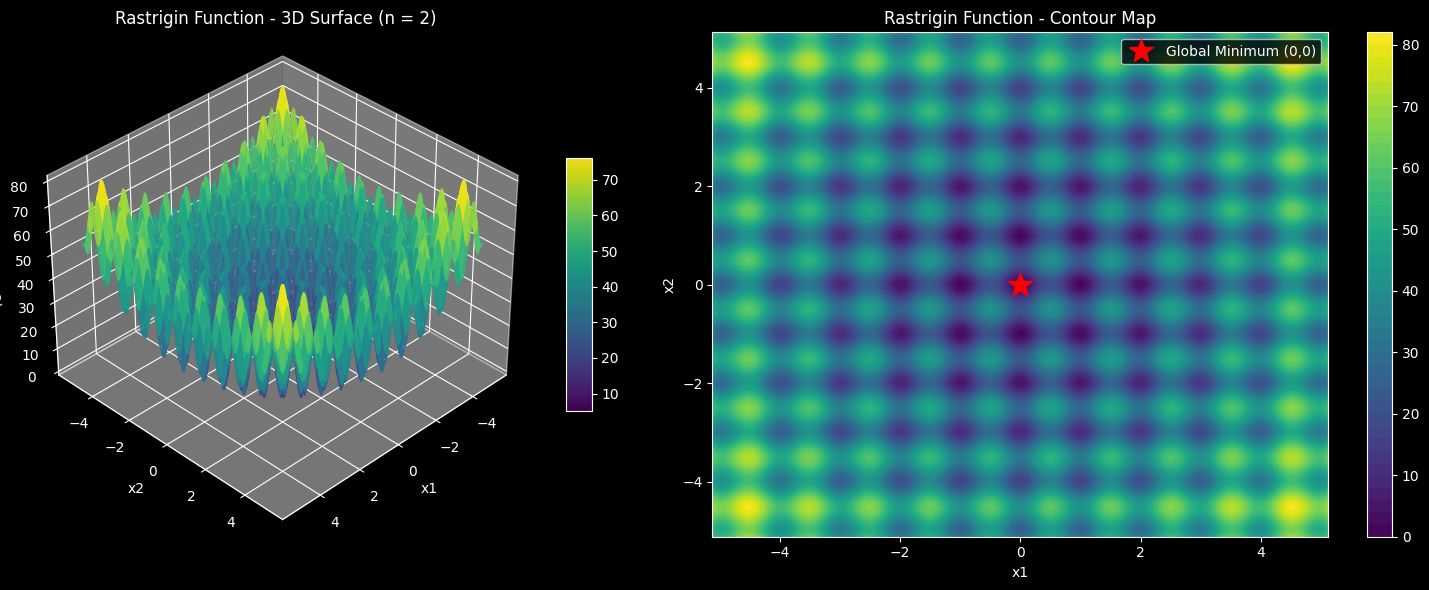
The 3D surface plot uses plot_surface on a 300×300 grid over the 2D search space $[-5.12, 5.12]^2$. You’ll immediately notice the “egg carton” texture — countless symmetric bumps surrounding a single, slightly deeper well at the origin. The contour map on the right shows the same thing from a bird’s-eye view, making the sheer number of local minima even more apparent. That red star marks the one true global minimum among dozens of decoys.
3. Proving the trap is real
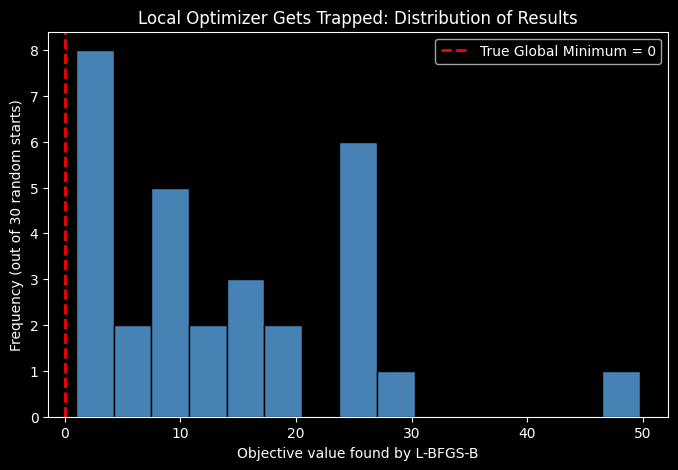
Before jumping to the “solution,” we first prove the problem exists. We run scipy.optimize.minimize with the L-BFGS-B method (a fast, gradient-based local optimizer) from 30 different random starting points. L-BFGS-B is excellent at descending smoothly to the nearest minimum — but “nearest” is the operative word. The resulting histogram typically shows results scattered across a wide range of nonzero values, with only a small fraction landing near the true minimum of 0. This is a direct, visual demonstration of why local search alone is unreliable on this function.
4. Solving it with Differential Evolution
Differential Evolution (DE) is a population-based, gradient-free metaheuristic. Instead of following a single point downhill, it maintains an entire population of candidate solutions that evolve generation by generation through mutation, crossover, and selection. Because it explores many regions of the search space simultaneously, it’s far more resistant to getting stuck in any single local minimum.
We apply it here to a 10-dimensional version of the Rastrigin function ($n=10$) — a much harder instance than the 2D visualization, with an astronomically larger number of local minima. Key parameters:
strategy='best1bin': a classic and robust DE mutation/crossover strategy.popsize=20: population size multiplier (actual population =popsize × dim).mutation=(0.5, 1.0): dithering range for the mutation factor, which helps avoid premature convergence.polish=True: after DE converges, scipy runs a quick local L-BFGS-B polish on the best solution to sharpen precision.callback=callback_de: lets us record the best objective value after every generation, which we use later for the convergence plot.
5. The high-speed version
Standard DE evaluates the objective function once per candidate per generation using a Python-level loop internally (or optionally via multiprocessing with workers=-1, which carries process-spawning overhead that isn’t worth it for a cheap function like this one).
Instead, we use scipy’s vectorized=True mode combined with updating='deferred'. This passes the entire population to rastrigin_vectorized in a single NumPy call per generation, letting NumPy’s compiled C backend handle the heavy lifting instead of Python’s interpreter loop. For cheap-to-evaluate functions like Rastrigin, this is typically several times faster than both the naive scalar approach and multiprocessing-based parallelism, since it avoids both interpreter overhead and inter-process communication costs. The speedup factor is printed directly in the output so you can see the improvement on your own machine.
6. Reading the convergence plot
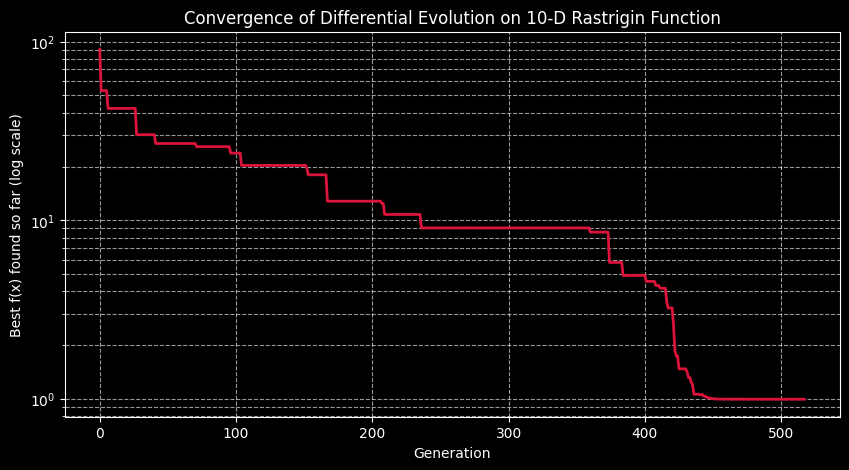
The final plot shows the best objective value found at each generation, plotted on a logarithmic y-axis (since the values shrink by orders of magnitude). You should see a characteristic staircase pattern: long flat stretches where DE is exploring without improvement, punctuated by sharp drops when it discovers a better region of the search space. By the final generations, the curve should flatten out near $10^{-8}$ to $10^{-10}$ — effectively zero, confirming that the algorithm has converged to the true global minimum at the origin.
Interpreting the Results
Once you run this in your own environment, here’s what to look for in the output:
- The 3D/contour plots should confirm visually just how deceptive this landscape is — dozens of local dips surrounding one true minimum.
- The local-search histogram should show that L-BFGS-B rarely finds the true minimum on its own; most runs land at nonzero values corresponding to nearby local minima.
- Differential Evolution’s final result (
result_scalar.funandresult_fast.fun) should be extremely close to0, with the solution vectorx*close to all zeros — even in 10 dimensions. - The speedup factor printed at the end quantifies how much faster the vectorized approach is compared to the naive scalar approach on your hardware.
Key Takeaways
The Rastrigin function is a small piece of code with an outsized lesson: gradient-based local optimizers are only as good as their starting point when the landscape is riddled with local minima. Population-based global optimizers like Differential Evolution trade some computational cost for dramatically better robustness — and with proper vectorization, that computational cost can be kept surprisingly low.
If you’re building optimization pipelines for real-world problems — hyperparameter tuning, engineering design, portfolio optimization — and you suspect your loss landscape might be non-convex or multimodal, this is exactly the kind of test you should run before trusting a purely local method.