ステファン・ボルツマンの法則
ステファン・ボルツマンの法則は、物体が放射するエネルギーの量を温度と関連付ける物理法則です。
この法則によれば、物体が放射する熱エネルギーの放射束は、その温度の4乗に比例します。
具体的には、放射束 $(W/m^2)$は絶対温度 $(K)$の4乗に比例します。
つまり、物体が高温になるほど、放射するエネルギーの量が急速に増加します。
この法則は、宇宙や星、地球の大気など、さまざまな物体の放射特性を理解するのに役立ちます。
ソースコード
ステファン・ボルツマンの法則は、放射されるエネルギーの強度(放射束)が、絶対温度の4乗に比例することを述べます。
数式的には、以下のように表されます。
$$
E = \sigma \cdot T^4
$$
ここで、$ (E) $は放射束、$ (\sigma) $はステファン・ボルツマン定数$((\sigma = 5.67 \times 10^{-8}) W/m(^2)/K(^4)) $、$ (T) $は絶対温度です。
以下のPythonコードでは、異なる温度における放射束を計算し、それをグラフ化しています。
1 | import numpy as np |
このコードでは、$100 K $から$ 1000 K $の範囲で絶対温度を変化させ、それぞれの温度における放射束を計算し、それをグラフにプロットしています。
[実行結果]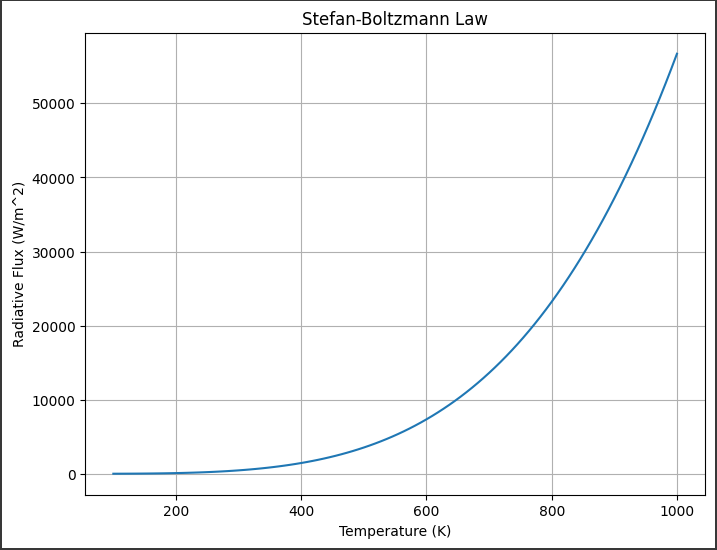
ソースコード解説
以下に、ソースコードの詳細を示します。
import numpy as npとimport matplotlib.pyplot as pltは、それぞれNumPyおよびMatplotlibパッケージをインポートします。
これらのパッケージは数値計算やグラフ描画に使用されます。sigma = 5.67e-8は、ステファン・ボルツマン定数を定義しています。
この定数は、放射束と温度の関係を示す物理定数です。T_values = np.linspace(100, 1000, 100)は、$100 K$から$1000 K$までの範囲で$100$個の等間隔の温度値を生成します。
これは絶対温度の範囲を指定しています。radiative_flux = sigma * T_values**4は、ステファン・ボルツマンの法則に基づいて、各温度における放射束を計算します。
放射束は温度の4乗に比例するので、この式を使用して放射束を計算しています。plt.figure(figsize=(8, 6))は、グラフのサイズを設定しています。plt.plot(T_values, radiative_flux)は、計算された放射束を温度に対してプロットしています。
温度が増加するにつれて放射束がどのように変化するかを示しています。plt.title('Stefan-Boltzmann Law')、plt.xlabel('Temperature (K)')、plt.ylabel('Radiative Flux (W/m^2)')は、それぞれグラフのタイトルと軸ラベルを設定しています。plt.grid(True)は、グリッド線を表示するように設定しています。plt.show()は、グラフを表示します。
これにより、ステファン・ボルツマンの法則に基づいて計算された放射束の温度依存性が視覚化され、温度が上昇するにつれて放射束がどのように増加するかがわかります。
グラフ解説
[実行結果]
このグラフは、ステファン・ボルツマンの法則に基づいて計算された放射束を表しています。
横軸は温度(絶対温度、$K$)を示し、縦軸は放射束 $(W/m^2)$を表します。
放射束は温度の4乗に比例するため、温度が上昇するにつれて急速に増加します。
グラフを見ると、温度が低いとき($100 K$付近)は放射束が非常に低いことがわかります。
しかし、温度が上昇するにつれて放射束が急速に増加し、高温領域では非常に大きな値を示します。
これは、高温の物体がより多くのエネルギーを放射するためです。
ステファン・ボルツマンの法則は、このような温度と放射束の関係を定量化しています。