AnyTrading は、FXや株式のトレーディングアルゴリズムを検証するための環境です。
今回はUSDJPYの分足データを使ってFX投資シミュレーションをしてみます。
USDJPYの分足データを使っての投資シミュレーション
2018年の1年分のデータを使って学習し、その学習結果をもとに2019年に1年間投資するとどうなるかを確認します。
準備したデータの2018年の最初のデータのインデックスは 5981180 で、2019年の最初のデータのインデックスは 6346695 でしたので、これをソースに反映します。
1 | import os, gym |
18行目 で学習用の2018年の1年分のデータ範囲を指定し、43行目 で検証用の2019年の1年分のデータを指定しています。
学習用データと検証用のデータは同じレングスでないといけません。そのため2019年の1年分データ範囲は多少ずれてしまいますが、誤差の範囲とします。
FXトレードを実行
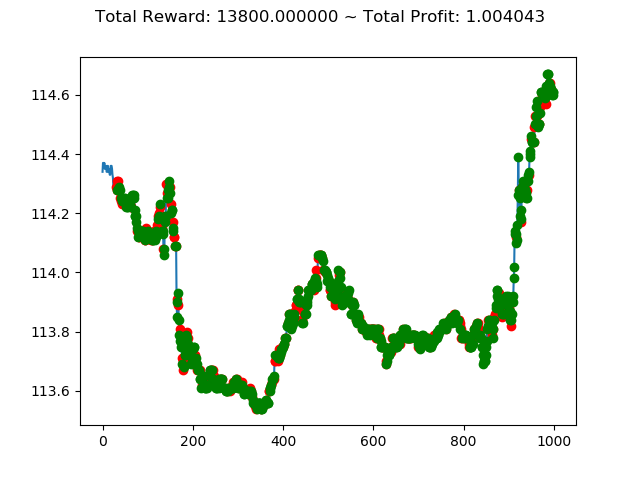
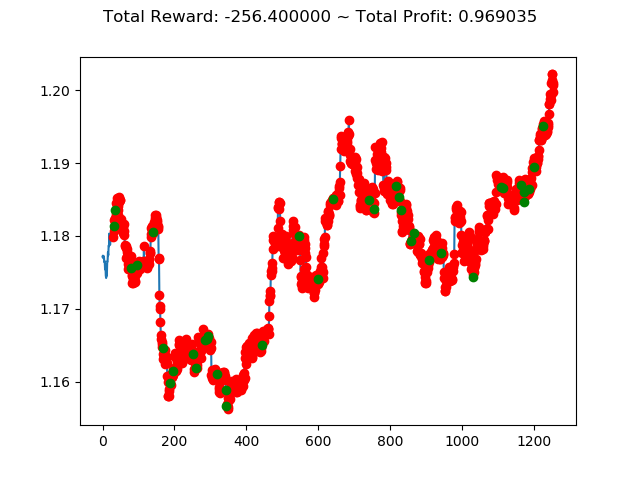
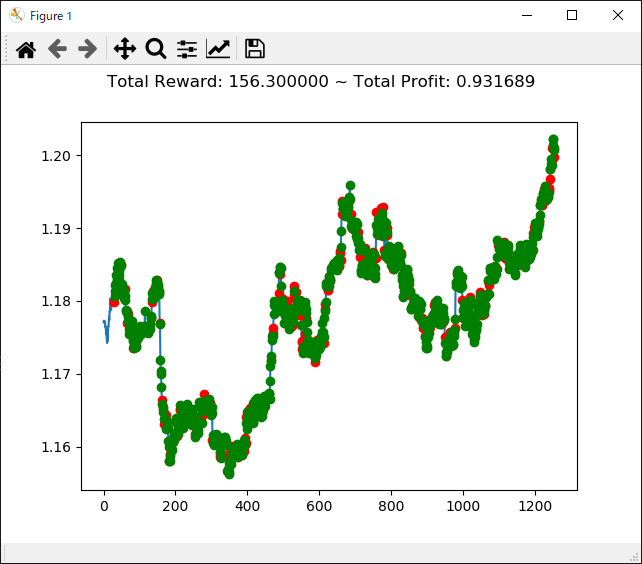
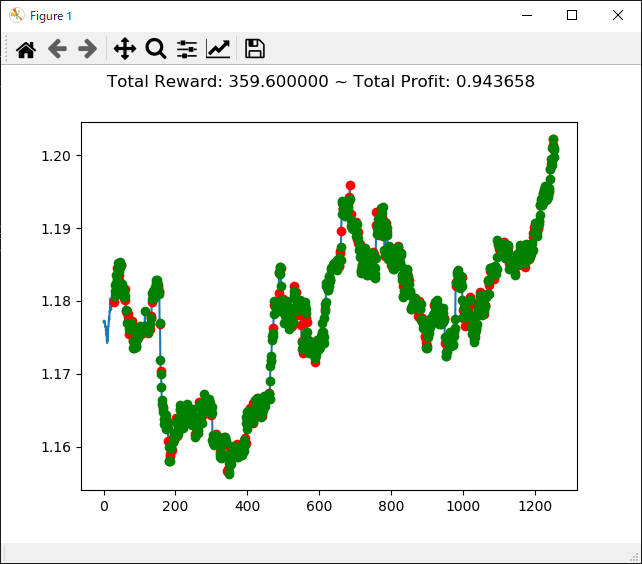
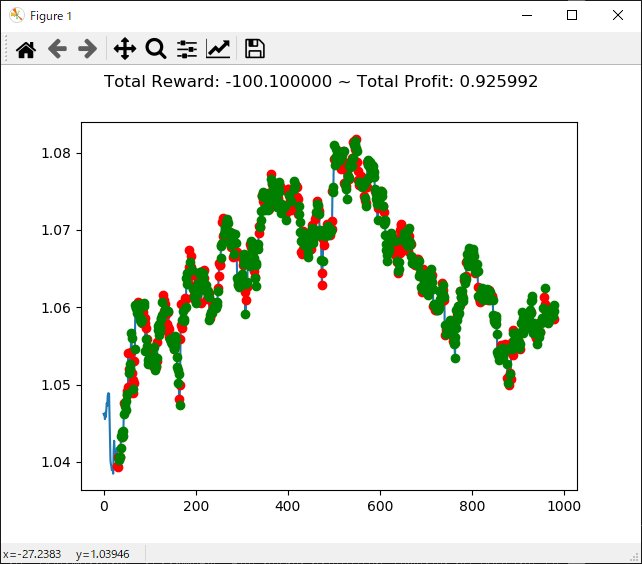
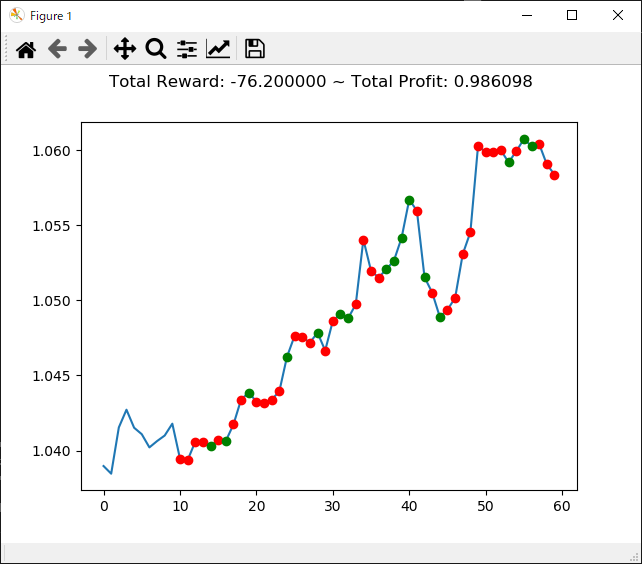
上記コードを実行すると次のような結果になります。
[コンソール出力]
1 | info: {'total_reward': 56600.00000000502, 'total_profit': 0.9830014666797735, 'position': 0} |
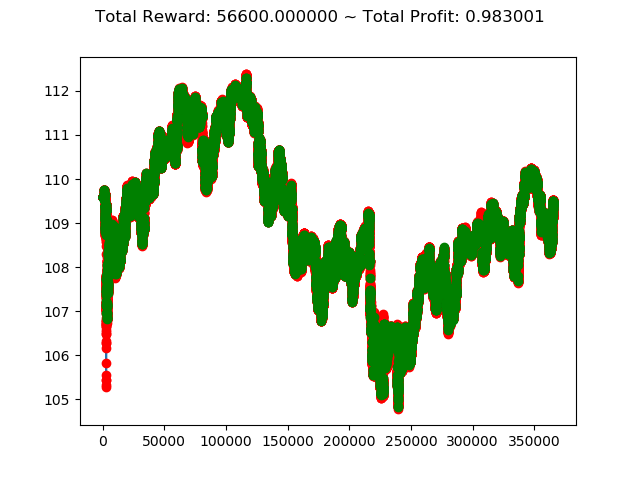
トータル報酬が 56600 で、トータル収益が 0.98 となりました。
かなり優秀な成績のようですが本当でしょうか・・・。分足データで一年中投資し続けるという人間には無理な行動ですが、強化学習で愚直に行うといい成績になってくれるということでしょうか。引き続きの検証が必要です。
今回はデータに気をとられて学習アルゴリズムを気にしなかったのですが、次回は ACKTR ではなく PPO2 を使いその他の条件は同じとして検証してみます。