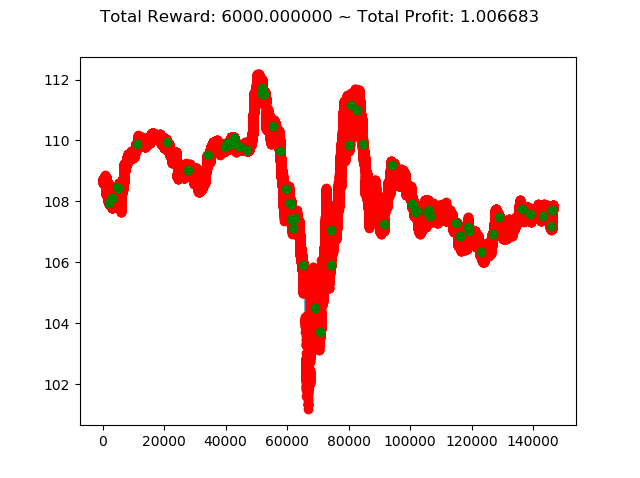
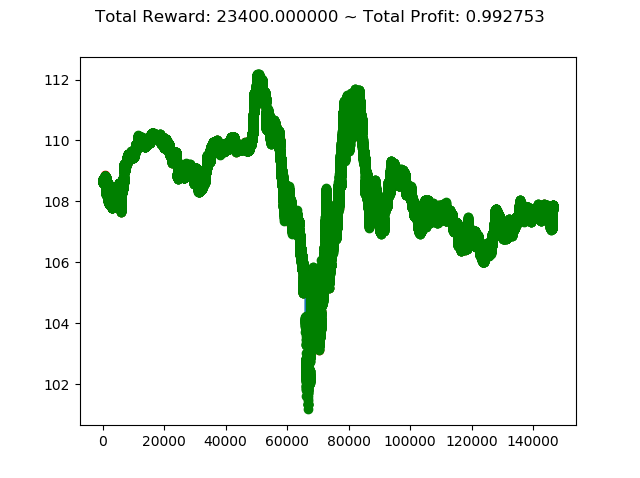
2020年になってコロナショックがあり大幅に動いた投資市場ですが、こんなときに強化学習で投資してたらどうなっていたのか気になったので検証してみます。
コロナショック時の投資シミュレーション(ACKTR)
検証データとしては USDJPYの分足データ を 2020年1月の最初から2020年5年の最後 までを使い、学習データとしては 2019年6月から2019年12月 のデータを使います。
今回は 強化学習アルゴリズムとしてACKTR を使い、前回使用した学習アルゴリズム PPO2 との結果を比較します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| import os, gym
import gym_anytrading
import matplotlib.pyplot as plt
from gym_anytrading.envs import TradingEnv, ForexEnv, StocksEnv, Actions, Positions
from gym_anytrading.datasets import FOREX_EURUSD_1H_ASK, STOCKS_GOOGL
from stable_baselines.common.vec_env import DummyVecEnv
from stable_baselines import PPO2
from stable_baselines import ACKTR
from stable_baselines.bench import Monitor
from stable_baselines.common import set_global_seeds
# ログフォルダの生成
log_dir = './logs/'
os.makedirs(log_dir, exist_ok=True)
# 2020年1月1日最初のインデックス
idx1 = 6677691
# 2020年5月31日最後のインデックス
idx2 = 6824172
# 2020年1月1日最初から2020年5月31日最後のデータ数
span = 6824172 - 6677691
# 環境の生成
env = gym.make('forex-v0', frame_bound=(idx1 - span, idx1), window_size=30)
env = Monitor(env, log_dir, allow_early_resets=True)
# シードの指定
env.seed(0)
set_global_seeds(0)
# ベクトル化環境の生成
env = DummyVecEnv([lambda: env])
# モデルの生成
#model = PPO2('MlpPolicy', env, verbose=1)
model = ACKTR('MlpPolicy', env, verbose=1)
# モデルの読み込み
# model = PPO2.load('trading_model')
# モデルの学習
model.learn(total_timesteps=128000)
# モデルの保存
model.save('trading_model')
# モデルのテスト
env = gym.make('forex-v0', frame_bound=(idx1, idx2), window_size=30)
env.seed(0)
state = env.reset()
while True:
# 行動の取得
action, _ = model.predict(state)
# 1ステップ実行
state, reward, done, info = env.step(action)
# エピソード完了
if done:
print('info:', info)
break
# グラフのプロット
plt.cla()
env.render_all()
plt.show()
|
35行目のアルゴリズム PPO2 をコメントアウトし、36行目のアルゴリズム ACKTR を有効化します。
FXトレードを実行
上記コードを実行すると次のような結果になります。
[コンソール出力]
1
2
3
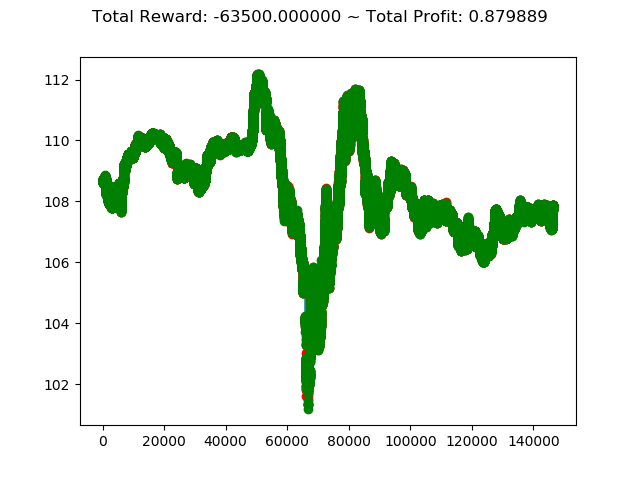
| info: {'total_reward': -68300.00000000806,
'total_profit': 0.9079909009227386,
'position': 0}
|
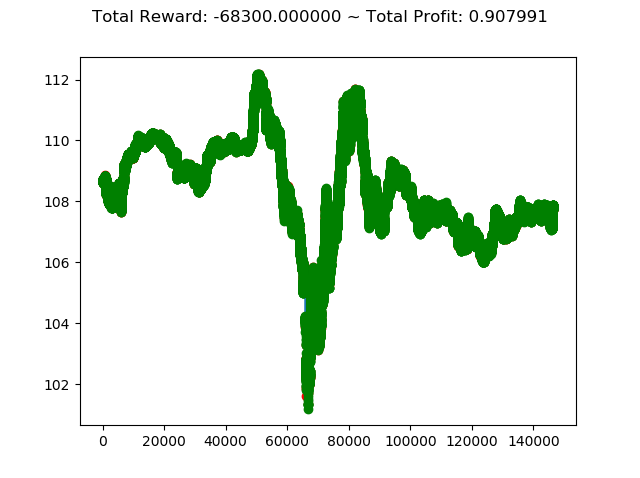
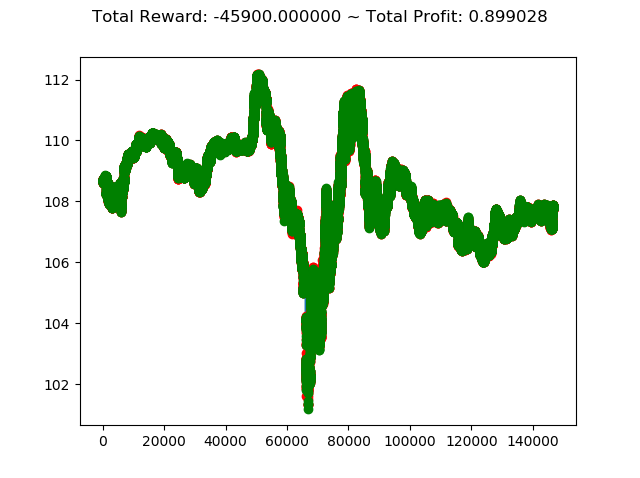
学習アルゴリズムを PPO2 から ACKTR に変更し、投資成績は次のように変化しました。
- トータル報酬 -63500 → -68300
- トータル収益 0.879 → 0.907
トータル報酬では PPO2 の方が成績がよく、トータル収益では ACKTR の方がやや上という結果になりました。
ただ今回はトータル報酬がどちらもかなりのマイナスなので、どちらのアルゴリズムでもコロナショック下の投資環境ではうまくいかないということが分かりました。
ただコロナショック直前のデータを学習したものでシミュレーションしたので、リーマンショック時など今回の状況に似たデータを学習すれば結果が変わるのかもしれません。