今回は、2011年のデータで学習を行い、2012年のデータで検証してみます。
2011年で学習し2012年で検証
パラメータとしては、学習アルゴリズム PPO2 で参照すべき直前データを 100 としています。
1 | import os, gym |
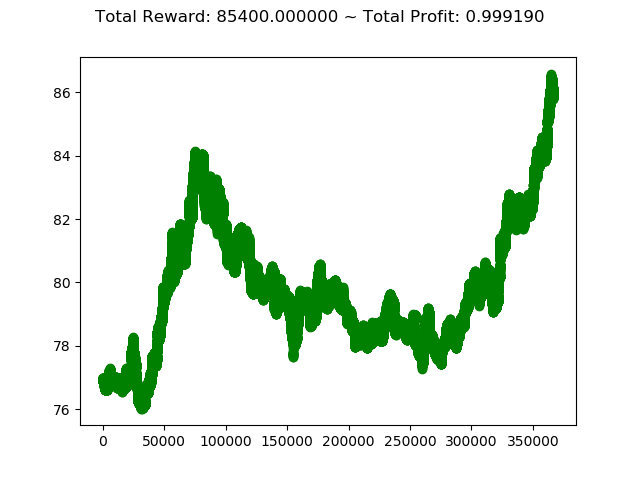
info: {‘total_reward’: 85399.99999999991,
‘total_profit’: 0.9991904595279201,
‘position’: 1}
<br>
<center>
</center>
<br>
2011年のデータで学習し、2012年のデータで検証した成績は次の通りです。
- トータル報酬 -10000 → 85399
- トータル収益 0.7218 → 0.9991
<br>
前回の結果(2010年のデータで学習し、2011年のデータで検証)に比べて大きく成績が向上しました。
アルゴリズムやパラメータというよりも、データによって大きく成績が変わるようです。